

In the last couple of years, we have written and heard about the usefulness of GPUs for deep learning training as well as, to a lesser extent, custom ASICs and FPGAs. All of these options have shown performance or efficiency advantages over commodity CPU-only approaches, but programming for all of these is often a challenge.
Programmability hurdles aside, deep learning training on accelerators is standard, but is often limited to a single choice—GPUs or, to a far lesser extent, FPGAs. Now, a research team from the University of California Santa Barbara has proposed a new middleware platform that can combine both of those accelerators under a common programming environment that creates enough abstraction over both devices to allow a convolutional neural network to leverage both with purported ease.
The idea that using programmable devices like FPGAs alongside GPUs in a way that makes anything easier for programmers sounds a bit far-fetched, but according to the research team, which did show impressive results on an Altera DE5 FPGA board along with an Nvidia K40 GPU, the approach can “provide a universal framework with efficient support for diverse applications without increasing the burden of the programmers.”
“Compared to GPU acceleration, hardware accelerators like FPGAs and ASICs can achieve at least satisfying performance with lower power consumption. However, both FPGAs and ASICs have relatively limited computing resources, memory, and I/O bandwidths. Therefore, it is challenging to develop complex and massive deep neural networks using hardware accelerators. Up to now, the problem of providing efficient middleware support for different architectures has not been adequately solved.”
They also looked at the trade-offs and relative differences between the two devices in terms of energy consumption, throughput, performance density, and other factors, and found it is possible to balance the framework to favor the better device for parts of the workload.
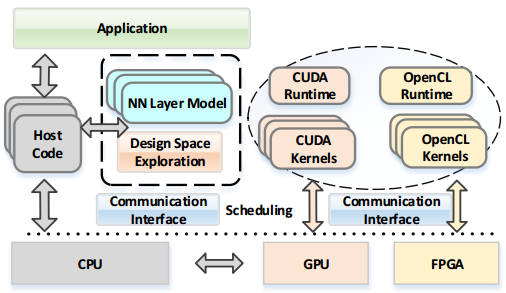
The effort, called CNNLab allows applications to be mapped into the kernels using CUDA and OpenCL using the team’s middleware as a bridge between the neural network and the accelerators. The framework is flexible, meaning tasks can be allocated to either device and a common runtime is used for both architectures.
In developing the middleware framework, the team did some interesting benchmarks to understand the relative differences between GPUs and FPGAs for different deep learning approaches using a hardware prototype they built using the Nvidia and Altera parts to understand the differences in execution time, throughput, power, energy cost, and performance density. These results alone are worth a look.
The team’s results show that “the GPU has better speedup (100x) and throughput (100x) against FPGAs, but the FPGAs are more power saving (50x) than GPU.” They also note that the energy consumption for convolutional neural networks across both devices is approximately similar. In terms of performance density, both are also not far from each other, with the FPGA in the 10 gigaflops per watt range with 14 gigaflops per watt for the GPU. However, they note that the operational efficiency is higher for GPUs.
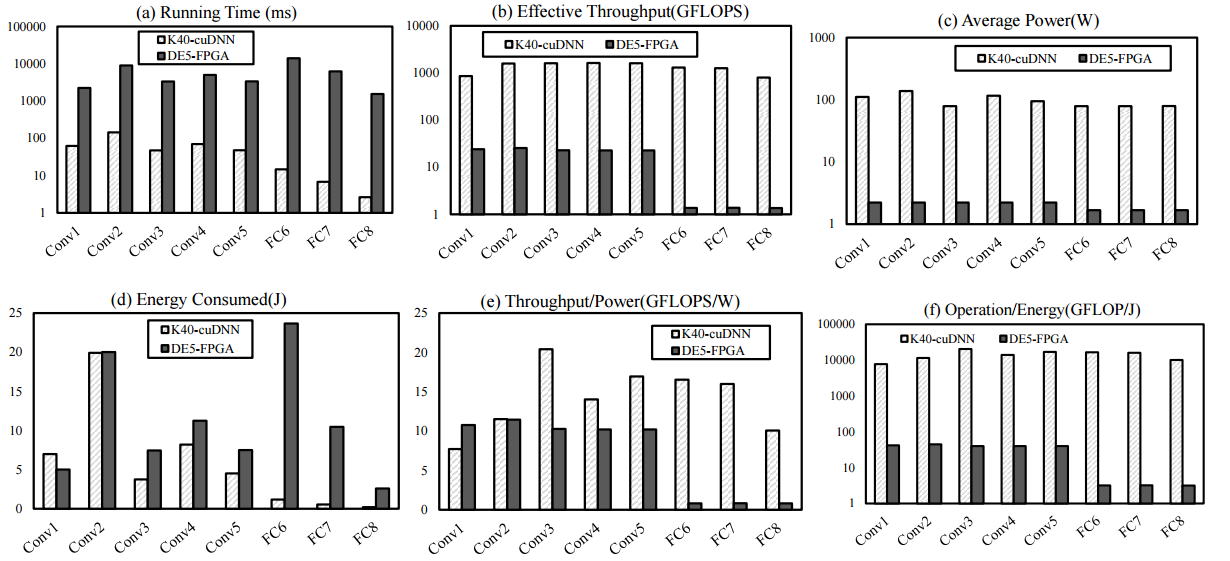
Comparison figures between GPUs and FPGAs across a number of metrics for convolutional neural networks.
Although the team was able to show speedups on their platform, they note that there are further developments needed. The speedup of both devices can be enhanced by better compressed network models. Further, they are considering how the accelerators might be paired using Spark or TensorFlow as the data processing backbone.
It is interesting research work in terms of the creation of a bi-directional layer of software that can speak both FPGA and GPU to maximize performance and efficiency, and with some work, one can see how boards based on both with a low-power processor can be strung together for convolutional neural network workloads. but if FPGAs were indeed easy to talk to and the OpenCL/CUDA interfaces were so easy to co-mingle, one has to wonder why this hasn’t been attempted already–if, indeed, it hasn’t.
The larger story here, beyond the middleware framework the team created, is how the metrics for both accelerators stack up in the chart above. While Microsoft Catapult and other systems and approaches are using FPGAs for deep learning, it is one side of the accelerator story for this area that has been less touted. We expect that Intel’s acquisition of Altera and its now direct focus on machine learning might yield more work in this area in the coming year or two.

Teaching Kubernetes To Do Fractions And Multiplication On GPUs
When any new abstraction layer comes to compute, it can only think in integers at first, and then it learns to do fractions and finally, if we are lucky – and we are not always lucky – that abstraction layer learns to do multiplication and scale out across multiple nodes …

Huawei’s HiSilicon Can Compete With Nvidia GPUs In China
Each time that the United States has figured out that it needed to do export controls on massively parallel compute engines to try to discourage China from buying such gear and building supercomputers with them, it has already been too late to have much of a long term effect on …

“No Quick Fixes” As Intel Losses And Restructurings Continue
Intel’s new chief executive officer, Lip-Bu Tan, has his work cut out for him, just like his predecessor, Pat Gelsinger, did several years ago. And given the even worse state that Intel is in – generating less cash on lower sales and therefore making it that much harder to raise …
This is a very interesting research. Especially, because I have worked in recent years with both GPU and FPGA in machine learning. My experience is that CUDA is well suited for systems such as Tensor flow. The manipulation of image data and the calculation of networks hardly differ (plus: both usually work with floating point). With FPGAs in principle it is possible to implement typical GPU operations like those of vector types. Even if you use these types in HDL it will be significant slower than in CUDA/GPU. With an additional layer (OpenCL) there will be additional drain in performance and more important in memory throughput.
On the other hand my experience is: FPGA could be much much faster than any GPU. But you have to pay significant costs in development time. And often will be stated that the memory bandwidth is not sufficient and the local memory in fpga is too small.
Well I think a lot of ML will move away from floating point to integer math simply because of ever increased network size and if that happens then GPU are pretty much stuffed. This is where FPGA would definitely wipe the floor of GPUs with ease.
It’s fractal , so practically limitless!