

Intel has finally opened the first public discussions of its investment in the future of machine learning and deep learning and while some might argue it is a bit late in the game with its rivals dominating the training market for such workloads, the company had to wait for the official rollout of Knights Landing and extensions to the scalable system framework to make it official—and meaty enough to capture real share from the few players doing deep learning at scale.
Yesterday, we detailed the announcement of the first volume shipments of Knights Landing, which already is finding a home on future supercomputers set to emerge throughout this year and beyond. While the focus of that news was centered on high performance, during his keynote last night, Intel’s head of HPC, Raj Hazra, described what the future holds for Knights Landing for machine learning. While he did not announce what many expected—custom SKUs offering more precision, memory, and other variants targeting this market, he did outline software investments that are ongoing and described the single-platform approach to blending complex workloads on a single cluster using Knights Landing, showing some notable benchmarks along the way. We will get to those in just a bit, but it’s worth backpedaling to look at the deep learning workload from a hardware perspective for a moment first.
If there has been any hardware trend this year that we have watched for deep learning and machine learning, it is far less about the CPU and much more focused on various modes of acceleration or novel architectures. At the top of the architecture list for deep learning, there has certainly been the GPU, followed closely by some of the custom ASICs, FPGAs, neuromorphic and other devices that are holding promise to efficiently train neural networks and execute the inference portion of that workload. While there have been notable results with all of these, especially GPUs, the fact remains that scalability is capped, separate clusters for the two main parts of deep learning workloads are required, and accordingly, there are two areas of software development to contend with.
The very fact that the deep learning workload is comprised of two distinct steps has led some companies, including Nvidia in particular, to roll out unique chips to support both parts of that process (for instance, with the M40 and M4 GPUs). While Nvidia has packaged these capabilities into systems like the DGX-1 appliance and is touting the ability of its Pascal P100 to handle both sides of that workload, Intel has finally arrived with a credible threat—and it is one worth paying attention to now that Knights Landing is shipping and their scalable system framework, which is designed to provide a common architectural and software basis that can be tuned for many different workloads at scale, is stretching to meet the needs of machine learning, particularly with the development of new libraries and hooks for the major deep learning and machine learning frameworks.
As Charlie Wuishpard, VP of Intel’s Datacenter Group and general manager for the company’s high performance computing division said in a briefing in advance of the International Supercomputing Conference (ISC), which is going on this week, his group is aware that they have not been as vocal as other companies when it comes to their take on machine learning. “It is notable that we’ve been reticent to talk about our investments in machine learning. I think at this point it’s worth saying that while we believe machine learning is an important workload, it remains just one of many we are trying to serve. We are trying to capture modeling and simulation, HPDA (high performance data analytics), visualization, and others in that range. Our strategy with both technology and the scalable system framework is to address all these needs.”
“There is machine learning training and there is inference; if I start with inference, the Xeon is still the most widely deployed landing space for that part of the workload and that has not been broadly advertised,” Wuishpard explains. “It’s an interesting and evolving area and we think Xeon Phi is going to be a great solution here and are in trials with a number of customers. We believe ultimately we’ll get a faster and more scalable result than GPUs—and we say GPUs because that’s gotten a lot of the attention.”
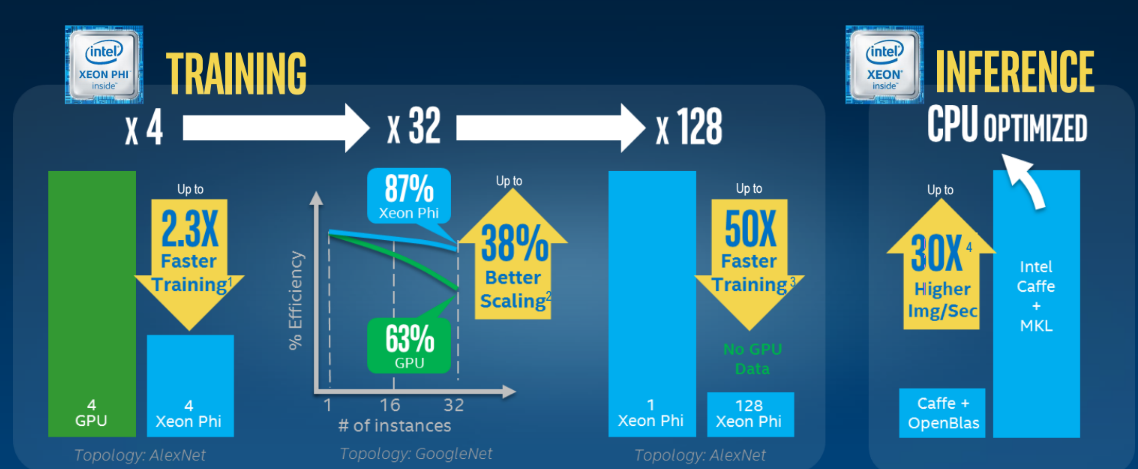
While the estimates about the majority of the inference side of the workload are based on Intel’s own estimates, this is a tough figure to poke holes in, in part because indeed, while the training end gets more attention, it is rarely a CPU-only conversation. “These codes tend to be tough to scale, they tend to live in single boxes. So people are buying these big boxes and chock them full of high power graphics cards, and there is an efficiency loss here,” he says, noting that users in this area desire to keep the entire workload on a single machine, have the ability to scale out, and use a cluster with a highly parallel implementation and without an offload model on the programming front. And it is in this collection of needs that the strongest case for Knights Landing is made—at least for deep learning training and inference.
So, why is Knights Landing a suitable competitor in the deep learning training and inference market? That answer kicks off with the fact that it’s a bifurcated workload, requiring two separate clusters for many users with limited scalability. In fact, scalability of deep learning frameworks on GPUs has been a challenge that many have faced for some time. The easy answer is to solve those underlying challenges using a common architecture that both scales and allows deep learning training and inference to happen on the same cluster using a simplified code base (i.e. not requiring offload/CUDA) and do so in a way that moves from beyond a single node for training.
Intel’s goal across workloads via the single system framework is to put forth a single architecture that can be tuned for specific workloads. While Knights Landing offers the acceleration within a familiar X86 wrapper for deep learning users, what really needs to happen as Intel scales out its approach to this market is perhaps the addition of some custom SKUs for this market that offer more options if users will be scaling out their boxes to run both the training and inference on the same cluster. We had been expecting such an announcement yesterday during Hazra’s keynote at ISC, but as Wuishpard reiterated during the briefings in advance of that keynote, this is really just Intel’s first public stake in the ground for machine learning–one that had to wait for the performance and stack details that rolled out yesterday with Knights Landing. He says we can expect more on the roadmap for this area, especially in terms of the code base (libraries, etc) but did not directly claim there would be new parts for this market.
Meanwhile, companies doing machine learning at scale like Google are simply forging ahead with their own processors to meet specific needs. Wuishpard says Intel is working closely with Google and other hyperscale companies to look at various parts of their workloads and already has KNL in test at some centers that we hope to hear about soon.
The one outstanding question we’ve been asking other companies is just how big the market for systems tailored for machine learning will be. We have yet to obtain Intel’s estimates, but as Wuishpard tells The Next Platform, Intel expects to ship more than 100,000 Xeon Phi units this year into the HPC market, and there is a good chance that more than a few hyperscalers are going to buy a bunch, too, for machine learning and possibly other workloads. More than 30 software vendors have ported their code to the new chip, and others will no doubt follow. And more than 30 system makers are bending metal around the Knights Landing processors.


DUG Sets Foundation For Exascale HPC Utility With Xeon Phi
While exascale systems, even at the single precision computational capability commonly used in the oil and gas industry, will cost on the order of $250 million, that cost pales in comparison to the capital outlay of drilling exploratory deep water wells, which can cost $100 million a pop. The trick …

Deep Learning Just Dipped into Exascale Territory
We all expected that the Summit supercomputer at Oak Ridge National Lab would be a major part of pushing deep learning forward in HPC given its balanced GPU and IBM Power9 profile (not to mention the on-site expertise to get those graphics engines doing cutting-edge work outside of traditional simulations). …

Deep Learning Infiltrating HPC Physics Domains
While deep learning models might not be able to simulate large-scale physical phenomena in the same way purpose-built supercomputers and their application stacks do, there is more research emerging that shows how traditional HPC simulations can be augmented, if not replaced in some parts, by neural networks. An upcoming meeting …
I don’t understand how Atom CPU cores could possibly be as efficient as GPU cores for deep learning. It’s my understanding that the less fat the “core”, the more efficient deep learning training is. Atom itself a CPU. So how can a bunch of CPUs, even if they are older ones and lower clock speed and whatnot, possibly be “almost as efficient” as a bunch of GPU cores for deep learning?
So for now, I’m going to treat this as more BS marketing from Intel, at least until we see in real world scenarios just how well it does.
It’s not just an Atom core; it has four threads. 512-bit vector processors. It’s an Atom with a baby GPU stuck to it and each core has two. It’s the most powerful vector unit Intel has ever created. So usually don’t respond to comments, but yeah. This is not a simple Atom core. 72 cores, 3.4 TF, how many in a Pascal to get that? – Nic
Thanks for the reply. But then if it’s mostly using its GPUs and AVX instructions for deep learning, then it loses the advantage of using Phi cores in the first place – doesn’t it?
I mean, wasn’t this whole idea from Intel that they would not use GPUs as accelerators just like everyone else, but instead would use these mini-CPU cores because that would make them much more programmable and developers would just easily port their software to it?
If it’s going to be GPU/AVX programming anyway, but with fewer deep learning tools than say what you get with Nvidia, what’s the point?
Well first most public Deep learning benchmarks are absolutely sewed towards GPU. Simple because neither Torch nor Caffe two public widely used DNN packages have zero I repeat ZERO multithreading in their CPU code. So that’s already a super unfair comparison in those benchmarks while the GPU code is parallized the CPU codebase isn’t so in the other words if you have a 24 Core Intel CPU it will only run at 1/24 efficiency.
caffee is easy to run multithreaded.
you sir are WRONG i repeat WRONG
http://stackoverflow.com/questions/31395729/how-to-enable-multithreading-with-caffe
This is a joke. Intel PR is clearly doing a great job. These comparisons are with the K80/K20, which is 2 generations old technology! Knights Landing should be called Knights Crashing– the Pascal class of GPUs will be much better than KnL.
honestly, in all the third party public benchmarks intel CPUs get killed compared to FPGAs and GPUs.
looking at the specs, nivdia offers roughly 20 TFLOPS of FP16 performance compared to a peak of 6 TFLOPS in the KNL. Add to that the higher bandwidth of 768 GB/s on the GP100 one can reslly understand why the nvidia DGX-1 systems are selling like hot cakes.
even looking at inferencing efficiency, the TX1 SoC showcased 24 images/sec / watt, better than any FPGA so far.
Please do more research Nic instead of just passing on marketing slides.