
This week at the International Supercomputing Conference (ISC ’16) we are expecting a wave of vendors and high performance computing pros to blur the borders between traditional supercomputing and what is around the corner on the application front—artificial intelligence and machine learning.
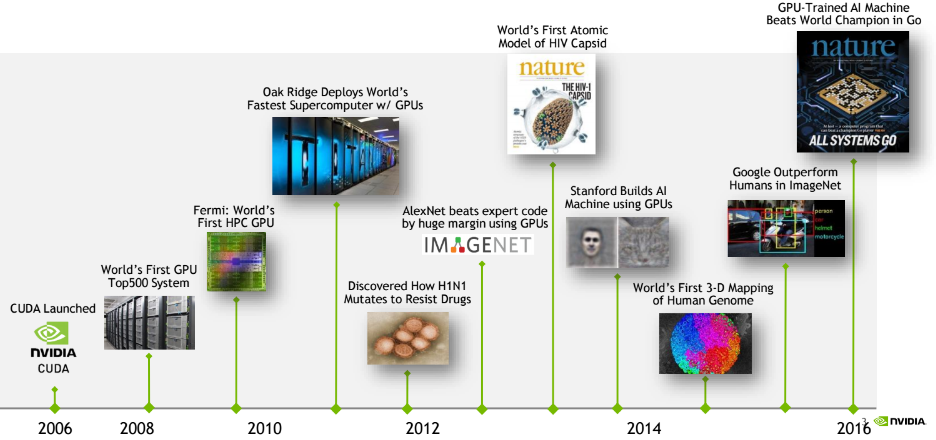
For some, merging those two areas is a stretch, but for others, particularly GPU maker, Nvidia, which just extended its supercomputing/deep learning roadmap this morning, the story is far more direct since much of the recent deep learning work has hinged on GPUs for training of neural networks and machine learning algorithms.
We have written extensively over the last year about how GPUs are being used in both deep learning and in HPC separately, but we might soon arrive at a fuller merger between the two areas, at least from a systems and hardware perspective. “Deep learning is not just an application segment, it’s a whole new computing model,” Ian Buck, VP of Accelerated Computing, tells The Next Platform. “If you had asked me at the launch of CUDA if GPUs would be in the largest supercomputers or revolutionizing artificial intelligence, I would have said that was a vision or even a pipe dream.”
HPC techniques and hardware are already at play for deep learning, so the question is, where will deep learning will fit for HPC?

The worlds of large-scale scientific computing and AI have not yet blended enough to tell a clear story on the application front—even if some of the same hardware accelerated approaches keep them tied. According to Buck, there is more than meets the eye when it comes to HPC adoption of AI. “Without a doubt, the HPC community is taking notice of AI. If I go talk to the national labs, they want to understand how they can use AI for their scientific computing workloads because they are seeing how transformative it is and how it is replacing some traditional forms of computer science, including computer vision, as just one example,” Buck explains.
Yet another question one might ask during the AI-laden HPC talks this week is where deep learning and machine learning might fit in HPC workflows. Is it a pre- or post-processing step to help filter or understand the input data or ultimate simulation results or is it something that is poised to replace the decades-old codes that comprise many HPC workloads? On this front, Buck explains that the shift toward AI in HPC is happening at the core compute level. “There are some problems that will remain as they are for the foreseeable future, especially for many simulation-based workloads (fluid, plasma, astrophysics, and those types of simulations), but what we’re seeing now are areas where there are large data volumes of data, as in the case of NASA where they are trying to understand climate change using actual pictures from satellites, for example.” That use case takes advantage of image classification to understand the image and match that to questions about crop yields and other factors.
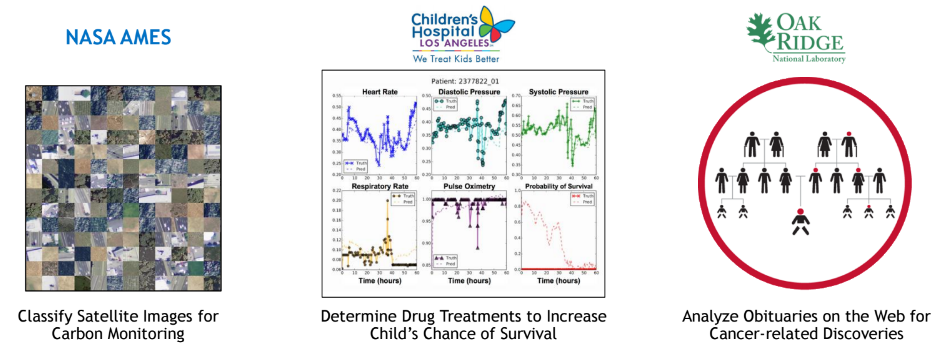
As seen in the set of examples above, the workloads in high performance computing that Nvidia refers to are not replacements for scientific computing simulations, but are instead focused on classification of text, images, and videos—the same areas where deep learning use cases are found now. Over the course of the next year, seeing how traditional parts of HPC workflows make use of this data for replacements to parts of simulations will be of interest—if it happens at all. Training neural networks for recognition tasks is valuable—but HPC comes with far more on the code-side than can be provided by neural networks in terms of capabilities, even with dramatic pattern recognition capabilities. Luckily for many top-tier supercomputing centers, there are already GPU nodes on existing systems to push new methods on deep learning frameworks, which could add to the volume of use cases for AI in HPC in the coming years.
Now, with that said, here is the other side of that argument. We have already seen how deep learning and machine learning can be used to “teach” an application to detect weather patterns at large scale and see big events before they happen. This same concept can be applied to other “storms” that can be seen developing off the horizon of massive data. In financial markets, for example. This is where a new breed of applications that truly represent that blurring of boundaries in AI and traditional supercomputing will emerge—and as we’ve highlighted, this is promising, functional, and really happening. With enough creativity and code footwork, especially since the hardware is there, this could be the shape of the new exascale computing story from an applications standpoint.
Nvidia is doing more than talking about the merger between HPC and AI. Although we already saw a similar move with the supercomputer-in-a-box approach to deep learning from GTC this year, the company announced PCIe versions of the Tesla P100 card this morning at ISC. These can plug into existing systems and have a 250 watt cap. In essence, these can work exactly like a K80, except they have more memory bandwidth (model depending) slightly less memory, and about 6.5% more single precision floating point capability (and 1.6X double precision floating point) plus support for FP16. One could argue it’s a more balanced GPU for about the same price and can be used for both the HPC and deep learning sides of the house or even on the same cluster. There is also the deep learning system Nvidia put together for GTC this past year, which has NVlink capable GPUs (and costs about 2X) and has been touted as suitable for both HPC and deep learning.
On that note, remember that it’s not just Nvidia that is looking to the AI hook for its HPC story this year at ISC. Intel’s keynote tomorrow night is entitled, “AI: The Next Exascale Workload” and while there might not be many HPC end users giving talks about how this fits into their scientific computing workflow, the vendors are creating a lot of noise. As mentioned above, this might change over the next few years, but for now, we’re all ears in terms of how these two worlds come together.


Nvidia Declares That It Is A Full-Stack Platform
In a decade and a half, Nvidia has come a long way from its early days as a provider of graphics chips for personal computers and other consumer devices. Jensen Huang, Nvidia co-founder and chief executive officer, put his sights on the datacenter, pushing GPUs as a way of accelerating …
China Export Controls Whack AMD Datacenter GPU Business
As far as we can tell, the export controls on crippled GPU compute engines announced by the US Department of Commerce back in April have had a disproportionately hard impact on AMD compared to Nvidia, as far as we can tell. These controls did not affect AMD’s first quarter financial …

Nvidia Entangled in Quantum Simulators
Quantum simulators are a strange breed of systems for purposes that might seem a bit nebulous from the outset. These are often HPC clusters with fast interconnects and powerful server processors (although not usually equipped with accelerators) that run a literal simulation of how various quantum circuits function for design …
intel will get killed in any serious performance / watt comparison of these systems, probably by as much as 4-5x.