

In a decade and a half, Nvidia has come a long way from its early days as a provider of graphics chips for personal computers and other consumer devices.
Jensen Huang, Nvidia co-founder and chief executive officer, put his sights on the datacenter, pushing GPUs as a way of accelerating HPC applications and the CUDA software development environment as a way of making that happen. Five years later, Huang declared artificial intelligence the future of computing and that Nvidia would not only enable that, but bet the company on this being the future of software development – that AI-enhanced everything would be, in fact, the next platform.
The company has continued to evolve, expanding its hardware and software capabilities aimed at meeting the demands of an ever-changing IT landscape that now includes multiple clouds and the fast-growing edge and, Huang expects, a virtual world of digital twins and avatars, and all of this dependent on the company’s technologies.
Nvidia has not been a point product provider for some time, but is now a full-stack platform vendor for this new computing world.
“Accelerated computing starts with Nvidia CUDA general-purpose programmable GPUs,” Huang said during his keynote address at the company’s virtual GTC 2021 event this week. “The magic of accelerated computing comes from the combination of CUDA, the acceleration libraries of algorithms that speed-up applications and the distributed computing systems and software that scale processing across an entire datacenter.”
Nvidia has been advancing CUDA and expanding the surrounding ecosystem for it for more than fifteen years.
“We optimize across the full stack, iterating between GPU, acceleration libraries, systems, and applications continuously, all the while expanding the reach of our platform by adding new application domains that we accelerate,” he said. “With our approach, end users experience speedups through the life of the product. It is not unusual for us to increase application performance by many X-factors on the same chip over several years. As we accelerate more applications, our network of partners see growing demand for Nvidia platforms. Starting from computer graphics, the reach of our architecture has reached deep into the world’s largest industries. We start with amazing chips, but for each field of science, industry and application, we create a full stack.”
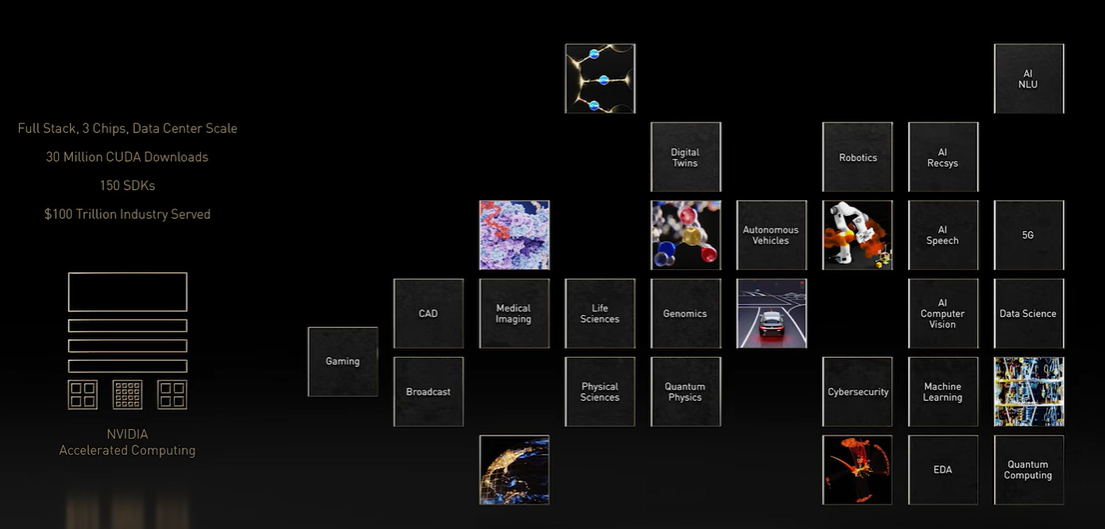
To illustrate that, Huang pointed to the more than 150 software development kits that target a broad range of industries, from design to life sciences, and at GTC announced 65 new or updated SDKs touching on such areas as quantum computing, cybersecurity, and robotics. The number of developers using Nvidia technologies has grown to almost three million, increasing six-fold over the past five years. In addition, CUDA has been downloaded 30 million times over 15 years, including seven million times last year.
“Our expertise in full-stack acceleration and datacenter-scale architectures lets us help researchers and developers solve problems at the largest scales,” he said. “Our approach to computing is highly energy-efficient. The versatility of architecture lets us contribute to fields ranging from AI to quantum physics to digital biology to climate science.”
That said, Nvidia is not without its challenges. The company’s $40 billion bid for Arm is no sure thing, with regulators from the UK and Europe saying they want to take a deeper look at the possible market impacts the deal would create and Qualcomm leading opposition to the proposed acquisition. In addition, the competition in GPU-accelerated computing is heating up, with AMD advancing its capabilities – we recently wrote about the company’s “Aldebaran” Instinct MI200 GPU accelerator – and Intel last week saying that it expects the upcoming Aurora supercomputer will scale beyond 2 exaflops due in large part to a better-than-expected performance by its “Ponte Vecchio” Xe HPC GPUs.
Still, Nvidia sees its future in creating the accelerated-computing foundation for the expansion of AI, machine learning and deep learning into a broad array of industries, as illustrated by the usual avalanche of announcements coming out of GTC. Among the new libraries was ReOpt, which is aimed finding the shortest and most efficient routes for getting products and services to their destinations, which can save companies time and money in last-mile delivery efforts.
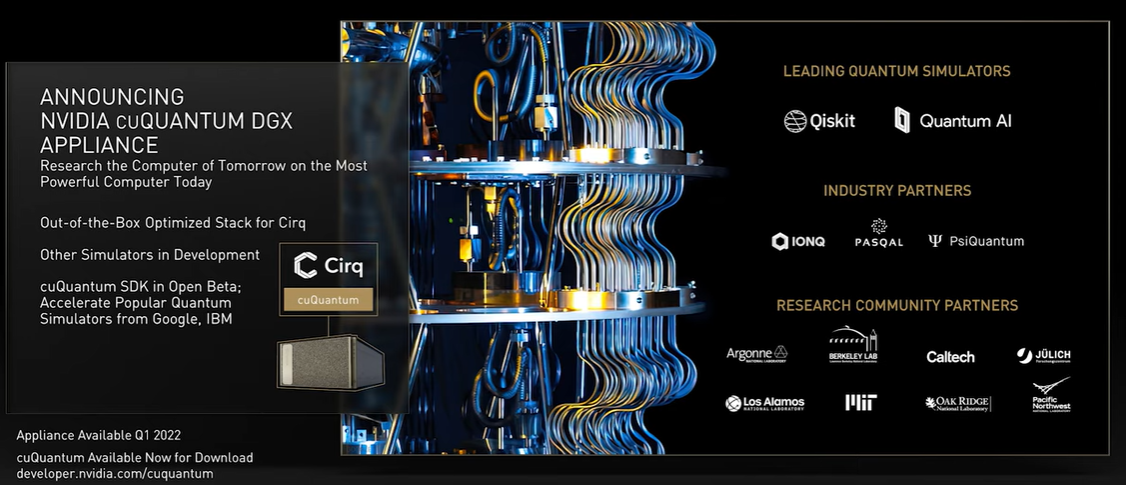
CuQuantum is another library for creating quantum simulators to validate research in the field while the industry builds the first useful quantum computers. Nvidia has built a cuQuantum DGX appliance for speeding up quantum circuit simulations, with the first accelerated quantum simulator coming to Google’s Cirq framework coming in the first quarter 2022. Meanwhile, cuNumeric is aimed at accelerating NumPy workloads, scaling from one GPU to multi-node clusters.
Nvidia’s new Quantum-2 interconnect (which has nothing to do with quantum computing) is a 400 Gb/sec InfiniBand platform that comprises the Quantum-2 switch, the ConnectX-7 SmartNIC, the BlueField 3 DPU, and features like performance isolation, a telemetry-based congestion-control system and 32X higher in-switch processing for AI training. In addition, nanosecond timing will enable cloud datacenters to get into the telco space by hosting software-defined 5G radio services.
“Quantum-2 is the first networking platform to offer the performance of a supercomputer and the shareability of cloud computing,” Huang said. “This has never been possible before. Until Quantum-2, you get either bare-metal high-performance or secure multi-tenancy. Never both. With Quantum-2, your valuable supercomputer will be cloud-native and far better utilized.”
The 7 nanometer InfiniBand switch chip holds 57 billion transistors – similar to Nvidia’s A100 GPU – and has 64 ports running at 400 Gb/sec or 128 ports running at 200 Gb/sec. A Quantum-2 system can connect up to 2,048 ports, as compared to the 800 ports with Quantum-1. The switch is sampling now and comes with options for the ConnectX-7 SmartNIC – sampling in January – or BlueField 3 DPU, which will sample in May.

BlueField DOCA 1.2 is a suite of cybersecurity capabilities that Huang said will make BlueField an even more attractive platform for building a zero-trust architecture by offloading infrastructure software that is eating up as much as 30 percent of CPU capacity. In addition, Nvidia’s Morpheus deep-learning cybersecurity platform uses AI to monitor and analyze data from users, machines and services to detect anomalies and abnormal transactions.
“Cloud computing and machine learning are driving a reinvention of the datacenter,” Huang said. “Container-based applications give hyperscalers incredible abilities to scale out, allowing millions to use their services concurrently. The ease of scale out and orchestration comes at a cost: east-west network traffic increased incredibly with machine-and-machine message passing and these disaggregated applications open many ports inside the datacenter that need to be secured from cyberattack.”
Nvidia has bolstered its Triton Inferencing Server with new support for the Arm architecture; the system already supported Nvida GPUs and X86 chips from Intel and AMD. In addition, version 2.15 of Triton also can run multiple GPU and multi-node inference workloads, which Huang called “arguably one of the most technically challenging runtime engines the world has ever seen.”
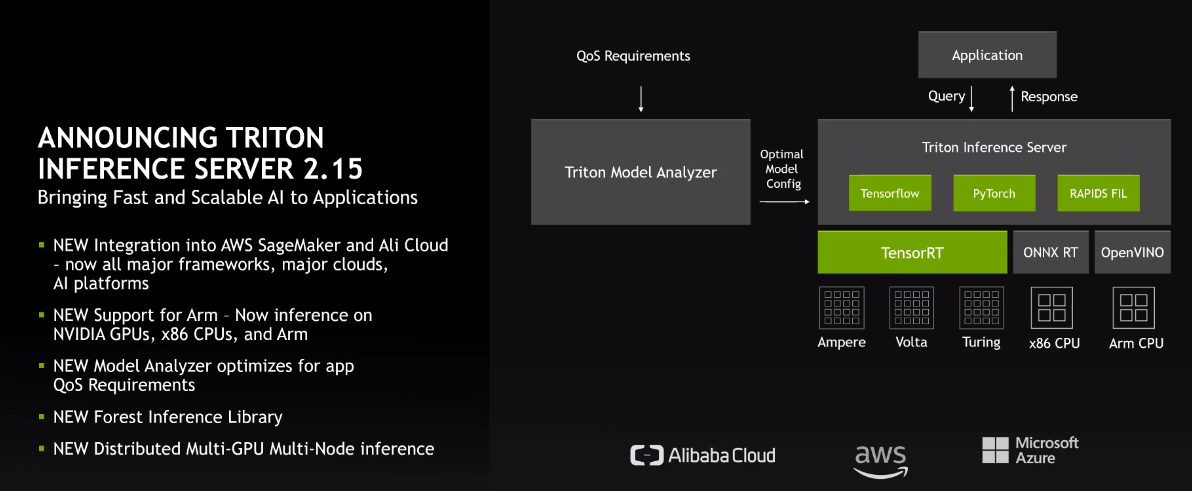
“As these models are growing exponentially, particularly in new use cases, they’re often getting too big for you to run on a single CPU or even a single server,” Ian Buck, vice president and general manager of Nvidia’s Tesla datacenter business, said during a briefing with journalists. “Yet the demands [and] the opportunities for these large models want to be delivered in real time. The new version of Triton actually supports distributed inference. We take the model and we split it across multiple GPUs and multiple servers to deliver that to optimize the computing to deliver the fastest possible performance of these incredibly large models.”
Nvidia also unveiled NeMo Megatron, a framework for training large language models (LLMs) that have trillions of parameters. NeMo Megatron can be used for such jobs as language translation and compute program writing, and it leverages the Triton Inference Server. Nvidia last month unveiled Megatron 530B, a language mode with 530 billion parameters.
“The recent breakthrough of large language models is one of the great achievements in computer science,” Huang said. “There’s exciting work being done in self-supervised multi-modal learning and models that can do tasks that it was never trained on – called zero-shot learning. Ten new models were announced last year alone. Training LLMs is not for the faint of heart. Hundred-million-dollar systems, training trillion-parameter models on petabytes of data for months requires conviction, deep expertise, and an optimized stack.”
A lot of time at the event was spent on Nvidia’s Omniverse platform, the virtual environment introduced last year that the company believes will be a critical enterprise tool in the future. Skeptics point to avatars and the like in suggesting that Omniverse is little more than a second coming of Second Life. In responding to a question, Buck said there are two areas where Omniverse is catching on in the enterprise.
The first is digital twins – virtual representations of machines or systems that recreate “an environment like the work we’re doing in embedded and robotics and other places to be able to simulate virtual worlds, actually simulate the products that are being built in a virtual environment and be able to prototype them entirely with Omniverse. A virtual setting allows the product development to happen in a way that has been before remotely, virtually around the world.”
The other is in the commercial use of virtual agents – this is where the AI-based avatars can come in – to help with call centers and similar customer-facing tasks.


Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …

The Most Complex Chip Ever Made?
Historically Intel put all its cumulative chip knowledge to work advancing Moore’s Law and applying those learnings to its future CPUs. Today, some of those advanced processors are destined for the forthcoming “Aurora” supercomputer at Argonne National Laboratory. However, demanding simulation and modeling workloads also benefit significantly from GPU acceleration. …
The New General And New Purpose In Computing
The term “general purpose” in regards to compute is an evolving one. What looked like general purpose in the past looks like a limited ASIC by today’s standards, and this is as true for GPUs and FPGAs as it is for CPUs. There is much talk about the era of …
Be the first to comment