

We have often opined that ARMv8 processors would struggle to meet Intel Xeon chips head-on until they got a few microarchitecture revisions under their belts to improve per-core performance and until they narrowed the manufacturing gap to 14 nanometers or 16 nanometers, or perhaps even 10 nanometers.
But it looks like ARM server chip maker Applied Micro is aiming to do just that with its X-Gene 3 chip, which we profiled last November when its architecture was announced. Applied Micro has reached for this lofty goal before, with its X-Gene 1 and X-Gene 2 processors, but it appears that their its third generation of custom core system on chip processors will deliver performance that is “well within range of Xeon E5 products,” according to a recently released report by the Linley Group, publisher of The Microprocessor Report.
This announcement tees up two important topics. First, will X-Gene 3 really deliver Xeon-class performance? And second, does it matter? That is, do ARM server chip makers really need to chase Intel’s Xeons, or is there a market for less powerful Atom-class SoCs in the datacenter?
Going Head-To-Head With Xeon?
Implemented in the 16 nanometer finFET processes from Taiwant Semiconductor Manufacturing Corp, the X-Gene 3 will sport 32 single-threaded, quad-issue cores, eight DDR4 memory controllers (yes, eight), and will run at speeds up to 3 GHz. If Applied Micro can deliver on the 3 GHz promise, this certainly looks to be a contender in the fight for Xeon dollars, at least for the midrange of the Xeon line (call it in the range of ~600 SPECint_rate performance) even if Applied Micro misses the clock speed target by a couple hundred megahertz. The decision to dedicate die space to the extra memory controllers is particularly welcome news, since many applications see “stranded cores” caused by insufficient memory bandwidth. From our friends over at Linley Group, you can see that X-Gene 3 will have both per-socket and per-thread (but not per-core) performance that is in the right zip code:
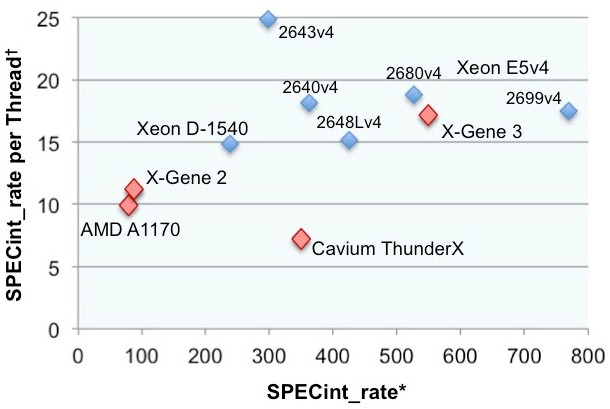
Figure 1. Comparison of server-processor performance. X-Gene 3 delivers better per-thread performance than any other ARM server processor and matches the newest Xeon E5 products in per-thread and total performance. *SPECint_rate2006 (base) for GCC; all ICC scores reduced by 15%. † at maximum thread count. (Source: The Linley Group)
From my experience, you need to be close to 20 SPECint_rate per core to be a player in general purpose cloud compute infrastructure at this time, so this looks pretty good. But to temper your excitement just a tad, look closely at the data and note that they are comparing a 14-core Xeon, with two threads on each core, to a 32-core single threaded X-Gene 3. Not all apps can run or run well in multi-threaded mode, and efficiency of multi-threading can vary, so a core-to-core comparison would be more meaningful for those applications and would significantly favor Xeon. Also, X-Gene 3 will come out in late 2017, assuming the schedule holds firm. Intel is likely to be shipping the “Skylake” Xeon E5 v5 chips in this same timeframe, which is a major uplift from the current generation, and will raise the ante yet again with more cores, faster cores, the OmniPath interconnect, perhaps PCI-Express 4.0 and more memory controllers than the “Broadwell” Xeon E5 v4 chips. Finally, these are simulations only, and are based on Applied Micro reaching 3 GHz for the X-Gene3, which is not an easy task for a 32-core SoC. These caveats notwithstanding, Applied Micro has certainly put Intel on notice that ARM can and will come after the heart of its profitable datacenter monopoly. And ARM chips do not need to match Intel’s top-bin parts to have an impact.
Is More And Faster Always Better?
These nits may not matter as much in the future as they appear to today. While public clouds require excellent per-core and per-socket performance to be able to handle the wide variety of workloads run by their enterprise customers, high-end processors are overkill for many of the fastest growing workloads. There may be a large opportunity for smaller, more efficient processors that are “right-sized” to match the needs of the IoT and other segments.
A few examples may help illustrate the point. Facebook’s massive server farms do not require absolute screaming performance, and depend instead on lower-clocked and lower-cored Xeons, and more recently the new Xeon D in the “Yosemite” microserver, which can deliver sufficient single-socket performance and enough DRAM at lower prices and lower power envelopes. (See our recent coverage from the Open Compute Summit on Facebook’s server configurations.)
Similarly, content delivery networks do not require brawny cores, and this market will experience hyper-growth as virtual reality games begin shipping in earnest and as video continues to displace old fashioned photos in advertising and communications. Content deliver networks need good I/O and networking bandwidth, but they don’t require a lot of computational performance to pick up data off a disk drive and put it on the (right) virtual wire. Finally, in computationally intensive applications like deep learning, where the compute is all on a GPU or other accelerator, the CPU is such a small part of the equation that a more modest CPU like an ARM server chip could deliver better economics.
In short, we are finally gearing up for a wave of competitive ARM-based server SoCs as 14 nanometer and16 nanometer manufacturing comes online and more affordable. From Applied Micro’s X-Gene 3 to a Snappier Dragon (sorry, they still haven’t given us a name) from Qualcomm, these parts will find a welcoming market in the traditional datacenter, where Xeon performance is de rigor, and from the new datacenters that are evolving to support the fast growing workloads coming online and that value good enough performance at lower costs and power.
Karl Freund has been an executive in the server and processor business for over 35 and is a frequent speaker at technology and investment conferences. He has been an outspoken advocate for alternative computing technologies such as ARM chips and GPUs, and is the author of the armservers.com site. Freund holds a bachelor’s degree from Texas A&M University in applied mathematics and a master’s degree in computer science from the University of North Carolina at Chapel Hill.


Cooling Magma Is A Challenge That Lawrence Livermore Can Take On
With 5.4 petaflops of peak performance crammed into 760 compute nodes, that is a lot of computing capability in a small space generating a considerable amount of heat. And that is what Lawrence Livermore National Laboratory’s latest HPC system – aptly nicknamed “Magma” and procured under the Commodity Technology Systems …

Programming The Network With Intel NEX Chief Nick McKeown
It would be very difficult indeed to find a better general manager for Intel’s newly constituted Network and Edge Group networking business than Nick McKeown, and Pat Gelsinger, the chief executive officer charged with turning around Intel’s foundries and its chip design business, is lucky that Intel was on an …
Intel Pits Its “Sapphire Rapids” Xeon SP Against AMD “Genoa” Epycs
Any performance comparisons across compute engines in use in a datacenter are always valid for a point in time since new CPUs, GPUs, FPGAs, and other ASICs are always coming into the market at different times. When AMD launched the “Genoa” Epyc 9004 processors back in November 2022, the Intel …
If the power8, a RISC ISA design, can be made into a very wider order superscalar design with 8 instruction decoders to feed 16 execution pipelines supporting 8 SMT processor threads per core then any custom micro-architecture engineered to run the ARMv8A ISA(RISC also) should be able to be made with some of the very same execution resources that the power8 designs possess.
One question for the The Linley Group’s Microprocessor report should be asked is what about AMD’s custom K12 ARMv8 ISA running custom micro-architecture. Looking at some of the YouTube interviews with at the time AMD’s Jim Keller, he in a few discussions mentioned that there was a great deal of idea sharing between His Zen x86 teams and his custom ARM K12 teams, so will AMD’s K12 custom ARMv8A running designs have the same SMT capabilities as Zen, similar cache subsystems, and a much wider order superscalar design more in line with Apple’s A7/A8/A9 designs that lack SMT abilities but are twice as wide order superscalar as the standard ARM reference design (A53,A57,A72) CPU cores.
So will AMD’s K12 have SMT capabilities and be able to retire more IPCs than even Apple’s Custom wide order superscalar designs. SMT for a custom ARMv8A running server/consumer micro-architecture should give much better CPU core execution resources utilization and does AMD, or anyone else for that matter, have any SMT enabled custom ARMV8A ISA running designs on the drawing board?
Well I would not hold my breath there AMD always seems to fail in the execution department. Seattle is a total flop and I am not sure if K12 will fair any better
Seattle uses a reference design ARM Holdings A57, it’s not very wide order superscalar design compared to some of the custom ARMv8A ISA running designs like Apple’s A7. So no one was expecting Seattle to be that much of a revolution, but AMD and some of its partners can use the Seattle development boards to get their ARM/Linux/other software ducks in order for AMD’s K12 when it is scheduled to arrive in 2017. And there will be some Seattle usage before the K12 designs arrive to replace them and AMD/partners will be supporting Seattle designs for the proper amount if time for the server market users.
It’s the custom ARMv8a ISA designs that will make the most headway in the server room, if they can get a foothold into some price/performance niche for web-page serving and other tasks that do not need much heavy number crunching and such. I will also remind some of AMD’s ability to add its GPU and other IP to the ARM based equation that will allow for some ARM/Polaris/other APU server solutions that very well may perform well on some analytical workloads that are now done only on x86 and Power/OpenPower based systems.
AMD’s, and others, use of the newer Interposer based technology for some new APUs/SOCs and GPUs/HBM(currently) on an interposer designs is very interesting for some very powerful systems made up of separately fabricated processor dies all wired up in a more parallel and power saving fashion for the HPC/Server/Workstation markets and also the exascale market that is now just beginning to be funded through government grants worldwide.
AMD’s server/workstation purposed APUs on an interposer will see their designs carried into the consumer market for some very powerful consumer variants, and with the interposer technology SOC/APU makers will be able to increase their yields by fabricating CPU die complexes separately from GPUs and other on interposer processor dies that can be added to the interposer package and all wired up via the interposer’s silicon substrate as if they where made from a single monolithic processor/SOC die. If AMD can create Custom ARM APUs on an interposer using all of its IP(Interconnect, HBM, GPU, and other) then that GPU accelerator IP alone will add to AMDs total attraction in the custom ARM(AMD K12) based server markets.
Also let it be known that there is nothing stopping Nvidia from getting a power/OpenPower license and doing something very similar like it has with its Denver ARMv8A ISA running SKUs, and even AMD could get an OpenPower license and integrate its GPU IP for some business in the third party OpenPower market. I see no reason for AMD to not consider the integration of its GPU/interconnect IP into the open power market it’s just another ISA, to go along with x86 and custom ARMV8A ISA running designs should one of AMDs custom customers want it.
Much more press attention needs to be focused on the custom ARM market among those that only license the ARMv8A ISA from ARM holdings then go about creating some very powerful micro-architectures of their very own that run the ARMv8A ISA, Apple’s P.A. semiconductor acquisition engineers did a great job with the Apple A7, pity there is so little information on the A8s/A9s from the technical press.
OranjeeGeneral you never have anything constructive to add to the debate on the technology, and this is not some sports match with some definite winners and losers for some of those with not much in the area of a rational thought processes who have a need to sublimate their super ego conflicts about their station in life. Does the need to be associated with a winner, or have a definite winner/loser so consume you that all rational discussion and debate needs to be constantly supplanted?
And you paint the overal AMD picture way too rosy. I am not saying that AMD hasn’t the right ingredients but they always seem to have the right ingredients but never seem to be able to execute on it. Their whole APU gamble they started six years ago still hasn’t paid off they actually lost marketshare in all their key markets in these six years. They missed the mobile train, they missed the data center train, they missed the ARM train, they missed the GPGPU train, they missed the micro server train (they even bought SeaMicro damnit and still managed to screw it up???)
, DeepLearning train and they will miss the IoT train as well. AMD has missed so many trains I’ve given up the hope that things ever will change.
That is of no concern, AMD, Intel, IBM(hardware part), Nvidia, and others could all become licensers of IP(like ARM Holdings) to entire markets of OEMs, and the market will be better for it. What matters the most is the decentralization of the APU/SOC/GPU/FPGA/Other supply chain of parts to the OEMs! The same goes for OSs. Let’s put the Intel’s and the M$’s in their proper place as suppliers to the OEMs and not monopolistic overlords over any supply chain so vital to the OEMs and an entire industry like the PC/laptop/server industry.
IBM never let Intel get between its supply of x86 16/32 bit ISA parts like Intel did with the entire PC/Laptop market, its too bad that IBM did not go with its own OS from the start over that which Bill gates cobbled together!
AMD has some pretty good products in the pipeline, including its own custom ARM(K12) custom micro-architecture engineered to run the ARMv8A ISA. So let’s wait and see just how wide order superscalar the K12 custom ARM core is, and if it has SMT capabilities! Zen is AMD’s first x86 ISA based product where the underlying x86 ISA running micro-architecture will use SMT, in addition to some reworking of its Caching algorithms , and other execution resources(Full Fat Cores with no FP/SIMD sharing among cores). If AMDs K12 follows it Zen’s engineering DNA, then K12 may give any of Apple’s A series custom designs a run for the performance metrics on custom ARMv8A ISA running core designs. AMD also has its Graphics/Interconnect/other IP to value add to the custom AMD market of GPU driven HSA aware GPU/APU accelerators! Now if Both AMD and Nvidia would just take a power license from OpenPower and add their various IP to the mix then things will be better for the supply of power based parts. Nvidia has already taken the steps towards getting its GPU IP into the power market, so now we need AMD to do the same, and IBM would be just as pleased with a second source of GPU accelerators for the power based market the openpower licensees included!
The mobile market is doing great with its decentralized source of SOC/GPU parts and that’s where the big money has been made for the OEMs that are most definitely in more control over their supply chain of very competitively sourced parts!
Good article. As you may recall we met super briefly at SC15. I am still keen to give an ARM based design a fair shake…(with $s too).
Wonder if any one else who is in the ARM is reading?
Yes I am serious.
Taiwant Semiconductor Manufacturing?
If you have not tried APM xGene and Cavium Thunder parts at their offer price, you should, because on the components design/production cost : price sacrifice shall we say, there is no better technology deal on the planet given the utility values of those transistors in relation to the design production cost to offer them.
Calculating xGene cost : price from the conference call data, Dr, Gopi on my private query at Open Server Summit assured me volume pricing will go up to Intel parity.
So lock in your procurement deal now.
Don’t let this opportunity for Freedom of Choice among competitive vendors pass by.
Mike Bruzzone, Camp Marketing
@OEMsSupplyChains
Well not sure look at the financials.
Intel, Qualcom,Apple and nVidia make way more money than ARM holding. So making an actual physical product is still superior than selling IP licenses Sure it would be better for us customer but not so good for those companies themselves.
So why would they give that up and just eat the breadcrumbs? Does not make much sense. AMD might be forced into that position sooner or later though especially if neither Zen and even less likely their K12 gets any foothold back in the market. Their problem is that their x86 license is useless to anybody due to their settlement agreement with Intel. And besides their GPU department they have nothing of value else where.
That Jim Keller left AMD pretty swiftly after joining (to join Tesla) shows me that he must have had very little confidence that AMD can actually execute. But lets wait and see. What IBM is trying to do I don’t quiet get frankly. Their roadmap is even more conservative than Intels so not sure if that’s going to persuade anybody long term. nVidia has the big problem they can only do very power hungry big design. Therefore their total failure and silent retreat in the mobile sector (even worse than Intel strangely nobody is talking about that). Without having the ability to go on die with a CPU I think their longevity in the HPC sector is at major threat.
“Intel, Qualcom,Apple and nVidia make way more money than ARM holding!”
ARM Holdings is an IP licenser/design bureau(reference design cores that run the ARM ISAs, and ISA designs for the ISA ONLY), but Intel is a monopoly supplier(Bad for OEMs), Qualcomm and Nvidia to a lesser degree than Intel! Intel and Microsoft need to be put back into their PROPER supplier of parts role to the OEM market, like AMD is in its proper place if it can survive, and AMD will! Apple is a Retailer first and foremost, that makes its own custom ARM ARMv8A ISA running SKUs using a top tier architectural license from ARM Holdings! so Apple licenses the ARMv8A ISA only from ARM Holdings and Apple rolls its own very wide order superscalar custom micro-architecture engineered to run the ARMv8A ISA! AMD’s K12 will likewise only be engineered to run the ARMv8A ISA, but be all AMD under the bonnet(Maybe SMT capable?)!
ARM holdings market cap/profits does not figure into the overall ARM based industry’s equation. As even Intel’s market cap and profits and R&D spending is dwarfed by the market caps of all the ARM based market players market caps combined! Hell Apple and Samsung are both larger than Intel in market cap and R&D spending. IBM is going with its ARM style licensing of the Power8/9 designs to a third party market that will become larger than Intel’s market cap in not too many years, for the third party openpower Power ISA based/power reference design THIRD PARTY market!
Jim Keller CPU lead project engineer for hire has finished with his contract with AMD and has moved on to Tesla for another challenging project, and Keller’s Zen(x86) and Custom ARM(K12) projects where completed as far as Keller’s contract was concerned!
OranjeeGeneral you have a talent for accentuating the negative with respect to some of the market players in the wider market place of SOC/APU/CPU and GPU/Other parts markets to the OEMs! Do you perhaps have any interest in fostering as much market volatility as possible in order to ply your trade?
I don’t agree. Look at http://www.hanselman.com/blog/Top10RaspberryPiMythsAndTruths.aspx