

Although there will be some meaty hardware and systems news in high performance computing over the course of 2016, this will be the year that programming models for HPC systems take center stage, especially as large supercomputing sites prepare for their first waves of pre-exascale machines. We have covered what is happening with OpenMP, PGAS, and other programming challenges ahead for such systems, and checked in with the OpenACC team to understand what lies ahead for the year.
OpenACC allows parallel programming for both GPUs and CPUs on a single version of the source code. It is currently in version 2.5, and will remain so for most of the year, but 3.0 does offer some noteworthy additions, including a feature called “Deep Copy” which will help centers tackle the problems presented by hierarchical data structures and various levels of the memory hierarchy.
As PGI’s Michael Wolfe (now part of Nvidia) explains to The Next Platform, “HPC applications aren’t just working with arrays of floats and doubles, they have a more intricate and hierarchical data structure. There can be an array of structures, each of which has subarrays that are dynamically allocated and some of those have their own dynamic subarrays—there is a lot of complexity there and also in the memory hierarchy with system, graphics, and other memory.” Much of the work there has been done with allowing the system to move data between system memory and high bandwidth memory, but there is still quite a bit left to be done—something Wolfe and team hope to tackle with features like Deep Copy.
“What we are trying to do is move the complexity into the language and the runtime as opposed to the application,” Wolfe explains. One of the most prominent examples of the challenges created by complex data structures and the memory hierarchy can be found in a weather code like a massive FORTRAN-based package at MeteoSwiss. In this case, they wanted to use a Kepler generation GPU, but had to copy the data to process on the device, which exposed the complicated nest of arrays with subarrays, attached to more subarrays. Wolfe and team are working on this code as a reference for how Deep Copy might work on similar HPC codes, making GPU acceleration easier for developers while getting the benefits of the deep memory hierarchy.
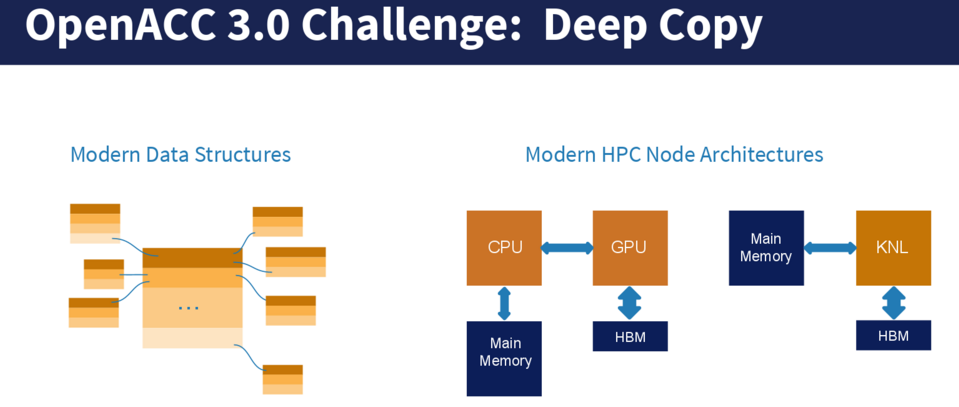
The above code example is just one, this issue is cropping up with more frequency, especially as applications are being written beyond the simple array variables and data types. Wolfe says that Oak Ridge National Lab and other centers are hitting this issue as they write their applications in a more modern style but then have to wonder if they need to revert back to an older style of coding versus have a programing model that can handle this new style. OpenACC hackathons are also revealing this as a challenge as users try to port their sophisticated codes, which is spurring effort toward new capabilities in OpenACC 3.0.
The OpenACC team expects that version 3.0 will roll out by the end of the year, preferably in time for the annual Supercomputing Conference (SC16) in November. A technical report will be issued in the next two week in time for the GPU Technology Conference (we will be on hand for this event, as well as the companion OpenPower Summit).
OpenACC has been growing rapidly and encompasses a number of scientific computing applications. “We are succeeding because of the developer-driven approach of our members, through events like Hackathons, and due to the increasing adoption of GPU computing as evidenced in the most recent Top 500 list. OpenACC is the only directives-based programming model for accelerators, such as NVIDIA GPUs, with multiple production implementations,” said Duncan Poole, OpenACC President. “OpenACC compilers and tools are an essential part of the basic tool chest for parallel programming, and are delivering performance portability across accelerators and CPUs today.”


OpenACC Cozies Up To C, C++, and Fortran Standards
Not so long ago, there was a question whether exascale supercomputers would be built from a very large number of thin nodes containing only modest amounts of parallelism or a smaller number of fat nodes powered by specialized accelerators and powerful manycore processors. As PGI’s Michael Wolfe pointed out, the …

Rethinking MPI for GPU Accelerated Supercomputers
In the accelerated era of exascale supercomputing, MPI is being pushed to its logical limits. No matter how entrenched it has become over the last two decades, it might be time to rethink programming for increasingly large, heterogenous systems. Every field has its burdens newcomers must bear and for HPC …

Programming In The Parallel Universe
This week is the eighth annual International Workshop on OpenCL, SYCL, Vulkan, and SPIR-V, and the event is available online for the very first time in its history thanks to the coronavirus pandemic. One of the event organizers, and the conference chair, is Simon McIntosh-Smith, who is a professor of …
As long as nVidia still pushes their CUDA instead of OpenACC I am very skeptical. Besides that I don’t see that much enthusiasm from other hardware vendors for this “open” standard either. But maybe my perception is skewed. OpenMP seems to have much wider industry support.