
Just because computing and storage are commodities does not mean, by any stretch of the imagination, that they are inexpensive. What it does mean is that these are raw materials that can be bought and sold at volume and are therefore subject to the laws of supply and demand and, importantly, can benefit from economies of scale.
If companies learn any lesson real quick once they cross over the threshold from large scale to hyperscale, it is that everything is different at that scale and at the speed with which hyperscalers tend to grow. What seems like a commodity to an enterprise must be refined further, down to its bare essence, by a hyperscaler and reconstituted as a globe-spanning platform.
This is the very lesson that Microsoft, one of the big eight hyperscalers, started to learn the hard way a decade ago when it stepped across that scale threshold. This lesson is one that its peers – Google, Amazon, Facebook, Baidu, Tencent, Alibaba, China Mobile, Yahoo, and a handful of others – all learned in their own times and reacted to in their own ways.
Microsoft, interestingly enough, reacted to the scale issues of its infrastructure, which were compounded mightily by the launch of the Azure public cloud in the fall of 2008 and its gradual transformation from a platform cloud to a broader offering that included the raw infrastructure services of compute, storage, and networking, by opening itself up more than it ever has in its history. The company not only embraced open hardware, but it has contributed back to the community much as Facebook, Rackspace Hosting, Goldman Sachs, Fidelity Investments, and others have – and in a way that neither Google nor Amazon have done with their infrastructure.
This is surprising to some, who do not quite yet understand the new Microsoft, which like its peers in the Open Compute Project understands enlightened self interest. But Microsoft, thanks to its unique position in the corporate datacenter centers of the world, is using open hardware as multiple levers for its business.
As part of our series on the state of the Open Compute ecosystem, we reached out to Kushagra Vaid, general manager of server engineering for Microsoft’s cloud, which includes the Azure public cloud as well as other services like Bing search, the Office365 suite, and Xbox Live, to get some insight into why Microsoft went the open route with hardware and what affect it has had on the company’s infrastructure. We will be talking to other players in the Open Compute ecosystem and attending the Open Compute Summit in two weeks as well to take the pulse of the community.
If Vaid knows a lot about something, it is servers. After getting his bachelor’s and master’s in computing engineering from the University of Mumbai and the State University of New York, respectively, he took a job at Intel and rose from the ranks of engineers working on Xeon server designs to be the lead architect for the Xeon platform. After nearly a dozen years doing that work, Vaid moved over to Microsoft in late 2007 to lead the design of its datacenters and the gear that runs inside of them, a few months ahead of the launch of “Project Red Dog,” which we now know as Azure, in early 2008.
A lot has changed about the infrastructure in Microsoft’s datacenters since that time.
“When I started at Microsoft, what we used to do was use an industry standard design and then work with the vendor to configure that machine to meet our requirements,” Vaid explains to The Next Platform. “It wasn’t a fully custom design from the ground up, it was more about having an OEM add this or remove that. This approach continued for a few years, and in the middle of 2011, we started talking to ODMs such as Quanta and other folks in Taiwan. The cloud was in its infancy at Microsoft back then, and our infrastructure was really focused on search engines, email, and other applications.”
But after a few years of ramping up the Azure service, it very quickly became apparent that just buying off the shelf gear and fussing with it would not scale well. To do hyperscale and not go broke means that things have to scale and get radically cheaper, not radically more expensive, as they scale.
“As we picked up speed, we realized that at the speed which we were growing at would require us to have more control,” Vaid continues. “It always comes down to control. We needed to manage the quality of the design, we could ensure that the right features were built into the design and that the reverse of that happened also, that the wrong features were not in the design. If we don’t need features, why should be pay for them? Supply chain aspects factor into this control, as does deployment, datacenter operations, warranty management, and how we maintain fleets of servers. All of this mandates a certain level of control, and we would not get that control if we did not have a design of our own.”
So Microsoft got to work creating its own server design. Notice how that is not plural. The Open Cloud Server design that Vaid and his engineers crafted is modular so it can accommodate various kinds of compute and storage in different combinations but still remain essentially the same iron.
After about a year, the design was done, and a year after that, Microsoft had brought together its supply chain and had lined up Quanta Computer, perhaps the biggest ODM for computing equipment in the world, to start building the machines. The Open Cloud Servers started rolling into Azure datacenters in early 2013. WiWynn became Microsoft’s second ODM partner shortly thereafter, and in January 2014, Microsoft announced that it was joining the Open Compute Project started by Facebook and was contributing the intellectual property behind its Open Cloud Server design to the open hardware community.
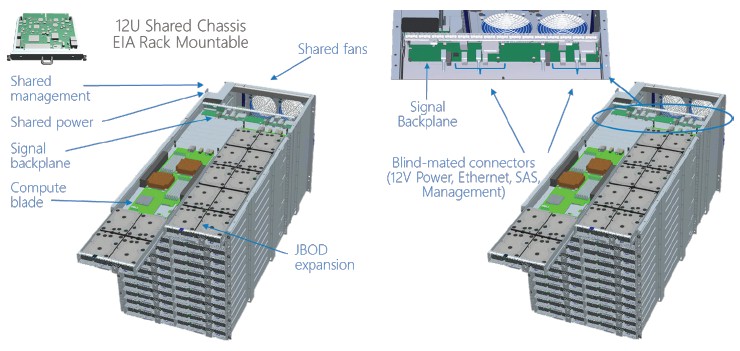
The Open Cloud Server has a 12U high rack enclosure that supports two dozen half-width trays that can have either compute or storage configurations. The base compute element is a two-socket Xeon E5 server with four 3.5-inch SATA disk drives and an M.2 flash memory stick for local operating system image support; an alternative sled with ten 3.5-inch drives is used to expand storage for the local nodes. The nodes plug into a midplane in the chassis, which has shared power and cooling and which also has networking modules. The initial Open Cloud Servers donated to Open Compute in January 2014 had 10 Gb/sec Ethernet networking into the server and storage nodes, but with the V2 machines that were unveiled in October 2014, 40 Gb/sec Ethernet with Remote Direct Memory Access over Converged Ethernet, or ROCE, support was added. The servers support Microsoft’s FPGA accelerators, its GPU accelerators, and its SmartNIC network adapters, too.
This basic design and the flexibility that it affords is sufficient to meet most of Microsoft’s server and storage needs. Vaid says that “well north of 90 percent” of the servers it currently deploys are based on the Open Cloud Server spec, and that the company only buys other gear because it takes time to phase out legacy gear and because it does acquisitions from time to time where companies have other iron and they cannot make an immediate shift.
“In the end, what really matters is that you want to have the right capacity in the right region at the right time so you can fulfill the promise of the cloud, which is that the cloud has to look infinite even though it is not.”
Microsoft started out with Quanta Computer and WiWynn as its initial Open Cloud Server suppliers, and although they don’t talk about it much, Vaid confirmed to The Next Platform that Hewlett-Packard Enterprise and Dell are also supplying iron to Microsoft as it builds out the Azure cloud.
“The general supply chain principles apply,” says Vaid. “One supplier is not acceptable because you have supply chain risk. Two is not good either, because one could go out of business. Three is a sweet spot, and the fourth is a hedge. So three or four suppliers is what you would tend to shoot for. The other thing with Azure is that we are deploying across various geographies, and some suppliers are stronger in Asia, some in South America, some in Europe or North America. So it gives you the flexibility to pick the right supplier for the right geography also.”

There are a few misconceptions that many have about hyperscalers, and one of them is that they build their own machines. None of them do that, except for prototypes. They either use ODM or OEM manufacturing partners. Another misconception is that hyperscalers literally call up Intel or Micron or Seagate Technology and buy processors, memory, and disk drives in bulk from them and then ship them to their manufacturing partners. While this latter thing can sometimes happen, it is not the way it works generally. The control that hyperscalers have is more subtle most of the time.
Vaid elaborates, somewhat delicately because he does not want to give out too many secrets.
“We have full control over the specification, and we know what it means to build an implementation of the specification. That allows us to have control over the pricing of the components that come into the design as well. The rest of what the supply chain team figures out is what factors on top of that, such as market dynamics like inventory excesses or shortages and they try to optimize around these. But the base design and costed bill of materials is something we control, and the rest is opportunistic in terms of how much more we can save on top of that given market dynamics.”
While Microsoft doesn’t have to buy components like processors, memory, flash, and disks, but in some cases if it makes sense, it will do that. It really depends on the situation. For instance, when it asks chip makers like Intel to create a custom Xeon part, that is, for all intents and purposes, the same thing as buying the processors outright from Intel. In other cases, the ODM and OEM vendor will do the buying of components. (All of the big cloud providers have custom SKUs of Xeon chips, by the way, and it stands to reason they might have custom memory and storage parts, too.)
“In the end, what really matters is that you want to have the right capacity in the right region at the right time so you can fulfill the promise of the cloud, which is that the cloud has to look infinite even though it is not,” Vaid says. “The supply chain is not black and white, and the level of control can change depending on situations.”
Ultimately, Microsoft has to let the parts suppliers know what it might need ahead of time so they can do their own building plans, whether it is directly or through its ODM and OEM partners. This is not something that large enterprises or HPC centers need to do, but maybe the biggest cloud builders and hyperscalers have to because they buy systems in lots that are one, two, or three orders of magnitude larger. Tens of thousands of machines at a time.
Counting The Costs, Adding Up The Benefits
It would no doubt be a lot easier for Microsoft to not be so heavily involved in server and datacenter design, but hyperscalers have no choice in the matter because extreme efficiency means the difference between success and failure.
Google and Microsoft have businesses that throw off a lot more cash than Amazon, and they can afford to learn and build on vast scales. Amazon is at the point where it only makes money because it has a massive public cloud, and its profits only drop to the bottom line because of the scale it has attained and its manic attention to every detail in its applications, systems, and datacenters. We don’t know if Google Compute Engine or Microsoft Azure are profitable, and for the time being it doesn’t matter so long as their other businesses are and they keep building their public cloud installed bases.
Keeping capital and operational costs low is the key to running a public cloud, as is driving up utilization on the infrastructure. The least expensive server capacity is the stuff you have already paid for, after all.
The financial benefits of shifting to its Open Cloud Servers have been large for Microsoft.
“There are multiple parts to the savings,” Vaid says. “One of them is capital expense, and that depends on what SKU you are buying and the workload, but I think it is fair to say that it is in the 15 to 20 percent range. But the bigger benefit you get is on the operational side, and it is much harder to quantify the savings here. If you have three or four different widgets that you are deploying, and they all have their own unique idiosyncrasies, if you shift to one widget coming from multiple suppliers, there is only one thing you need to worry about. When you hit a certain scale point, it gives you a tremendous amount of advantages. Your datacenter staff only has to manage one design, so the way you do operating system and software updates all gets standardized on that one thing. It is hard to quantify these benefits, but you have agility and can bring capacity and new applications to market faster, and you can debug issues faster when there are problems. All of this reduces the cost of owning and operating a large fleet. Operations has a much, much higher savings than the 15 to 20 percent on the capex side.”
“Among the cloud players, we are only one that has a presence in the public cloud and in the enterprise. The concept is to take the learnings from the public cloud and operating at scale and bring it back to the enterprise, closing the loop on that to create a virtuous cycle. Open Compute was a great way to close that loop on the hardware side, so we can drive consistency between the private clouds and the public cloud. We want to trickle the technologies we are developing down into the enterprise environment.”
But there are side benefits that are equally hard to quantify economically that the hyperscalers have, but a big one is that by being in charge of their own server designs, controlling their own supply chain, and buying in huge volumes they get a longer view into the future than other IT organizations. Intel has not even announced its “Broadwell” Xeon E5 chips, but Microsoft already knows about “Skylake” Xeons and a few years beyond that.
Vaid has to be a little coy about this. “Let me put it this way. We are a big part of shaping the design for a lot of these suppliers, which means we are already talking about features, for instance with CPUs, that could be designed into products coming in maybe 2019 or 2020. You have to be this far out in front or otherwise you are just buying off the shelf, and you don’t have any control. The workloads are changing so fast – machine learning did not really exist a few years ago – so you want to make sure that the CPUs, memory, SSDs, FPGAs, or whatever is coming out are designed the right way for your workloads. Otherwise, you just buy what they build anyway, and this is not optimal.”
So why do this through the Open Compute Project? Why didn’t Microsoft just keep all of this engineering to itself?
“We realized that Open Compute could bring a significant amount of benefits to our enterprise customers,” Vaid explains. “Among the cloud players, we are only one that has a presence in the public cloud and in the enterprise. The concept is to take the learnings from the public cloud and operating at scale and bring it back to the enterprise, closing the loop on that to create a virtuous cycle. Open Compute was a great way to close that loop on the hardware side, so we can drive consistency between the private clouds and the public cloud. We want to trickle the technologies we are developing down into the enterprise environment.”
It doesn’t hurt that by donating its Open Cloud Server design to the community that Microsoft has a chance to make its design a higher volume product that it can do by itself, which is one reason why Facebook opened up its server, storage, and datacenter designs to begin with. The irony, perhaps, is that Microsoft’s OCP designs could end up being the volume leader if the private Azure Stack software takes off inside large enterprises and they want hardware that is as close as possible to what Microsoft itself uses. There is a reason why HPE and Dell want to make Microsoft’s iron, and it is not only to supply Azure datacenters, but also its many clones that could pop up in tens of thousands of datacenters around the world.
There could come a day when Facebook just uses gear adhering to Microsoft designs. Stranger things have happened, like Microsoft becoming a hyperscaler and open sourcing hardware.

Meta Platforms Spent Over $1 Billion On Arista Networking In 2022
The hyperscalers and cloud builders are the toughest customers in the IT sector, demanding the highest performance at the lowest price and an ever-improving ratio between the two. They can be as tough as they want, of course, but unless they want to design their own ASICs and compute, storage, …
The Perfect AI Storage: Trino From Facebook And Iceberg From Netflix?
When it comes to solving data analytics problems at scale, it is tough to beat the hyperscalers. And that is why a combination of technologies that were originally developed at Facebook (now Meta Platforms) and Netflix could end up being the perfect pairing to create a “lakehouse” underpinning AI training …
Hyperscalers And Clouds Lift Arista Networks Sky High
A massive buildout of infrastructure is happening within the datacenter walls of at least several of the hyperscalers and large clouds in the world if the financial results of Arista Networks, the upstart switch maker that has been taking on Cisco Systems in the datacenter with machines based on merchant …
Be the first to comment