
Proprietary and quasi-proprietary interconnects are nothing new to the supercomputing space, and in fact, this is where they still live and thrive and evolve. While hyperscalers will do anything to keep their infrastructure as uniform as possible in space and across time because they need economies of scale to serve billions of users, HPC centers need to have systems that are tightly integrated to have simulations span tens of thousands of cores in a more or less coherent fashion.
It is no surprise, then, that the upper echelons of the HPC community has not gone the cheap and easy route and simply adopted Ethernet. Those whose applications are sensitive to both bandwidth and latency continue to invest heavily in InfiniBand, Aries, NUMALink, and other proprietary interconnects such as the one that the Chinese government created for the Tianhe-2A machine, called TH Express-2, and the one that Atos/Bull is working on, called BXI, for the Tera 1000 supercomputer at CEA. Soon, we will also see Intel’s Omni-Path interconnect, which is an amalgam of technologies that Intel got through its acquisition of the interconnect businesses of QLogic and Cray, enter the market, with Intel expected to offer Omni-Path at a very aggressive price.
The Top500 supercomputing list is a leading indicator of sorts for very high end networking, and sometimes it is a precursor to the technologies that will find their way outside of the HPC arena. The general trend in recent years is that the list is bifurcated between machines that are latency sensitive and therefore are compelled to use special interconnects like InfiniBand from Mellanox and Intel, Gemini and Aries from Cray, the unnamed interconnect inside of the BlueGene supercomputers from IBM, and others. Here is how the system counts have tracked over the past eight and a half years:
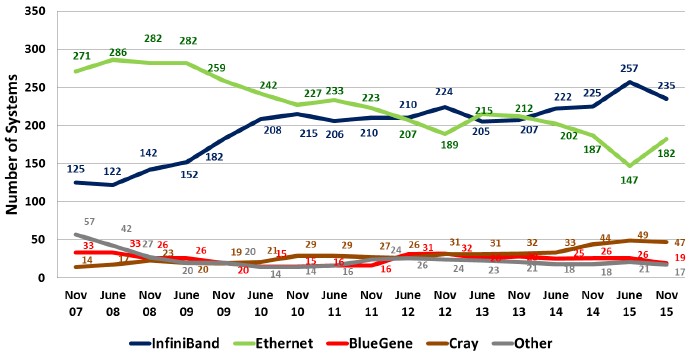
The addition of 45 machines that were tested using LINPACK by Sugon in China, which we discussed in detail earlier this week from the SC15 supercomputing conference in Austin, Texas, has caused a big upward bubble for 10 Gb/sec Ethernet connectivity on the November 2015 Top500 list. Submissions for the LINPACK benchmark test results do not actually require that machines be performing simulation and modeling workloads to be included in the list, which undermines the analysis of processor and interconnect technologies used in the traditional HPC market but also reflects what we know is the broadening use of HPC technologies in data analytics outside of traditional HPC.
But in an ideal world, the Top500 rankings should qualify what the systems under test actually do to help us separate out real HPC systems from merely scale-out systems that have run the LINPACK test, and perhaps more importantly, maybe we should work across industries and workloads to expand beyond 500 systems. To our thinking, what we need is a Top1000 or Top2000 scale-out systems ranking that includes machines dedicated to HPC, data analytics, data warehousing, caching, parallel database, and application serving. This would be tricky, of course, but what fun it would be to gather this data and have appropriate performance benchmarks for each type of machine. Personally, we want to see an MPI-enabled variant of Memcached tuned up for a Cray Aries beast, or a parallel OpenPower Power-GPU cluster using EDR InfiniBand that is doing analytics. . . . But we digress.
As you can see from the table above, the number of systems running Ethernet has been trending downward over time with an occasional spike. It is no surprise that InfiniBand, which generally speaking provides the lower latency and higher bandwidth compared to Ethernet and which usually comes to market with a higher bandwidth level at least a year in advance, has been on the rise. But what we were hearing from SC15 is that for certain kinds of workloads where Ethernet has prevailed for a long time – notably, seismic processing in the oil and gas industry – companies are either shifting towards InfiniBand or looking ahead to Omni-Path because the applications are requiring lower latency to scale. Similarly, the Aries interconnect sold by Cray (and controlled by Intel) is on the rise across myriad workloads in the HPC arena, and is particularly strong in weather forecasting and modeling, as we have discussed previously.
Having said all of that, there is one outside force that may come into play in the HPC space: relatively inexpensive 25 Gb/sec server connectivity on the server and 50 Gb/sec and 100 Gb/sec Ethernet switching to link to it. It really depends on pricing, however. At the moment, 100 Gb/sec Ethernet switches are still considerably expensive compared to InfiniBand, which might be surprising to a lot of people. Moreover, Mellanox Technologies is setting the pace for pricing on both fronts. It costs on the order of $333 per port for EDR InfiniBand with the new Switch-IB 2 switch that Mellanox announced at SC15 compared to $590 per port for the Spectrum 100 Gb/sec Ethernet switches that Mellanox debuted in the summer. The other players in the 25G Ethernet switching market, including Dell, Hewlett Packard Enterprise, and Arista Networks, are being pulled down to below $1,000 per 100 Gb/sec port for fixed port switches, and we think it won’t be long before it is $500 per port on the switch. Everyone is expecting Intel to undercut Mellanox on Omni-Path – perhaps as low as $250 per 100 Gb/sec port at the street level was the chatter we heard at the SC15 conference. As we went to press earlier this week with our Omni-Path coverage, no one knew what Intel’s plans were with regard to 100 Gb/sec Ethernet switch pricing. (Intel did announce is 100 Gb/sec multihost Ethernet adapters two weeks ago and showed off its Omni-Path switches and adapters at SC15 last week.) But the pricing has been published on Intel’s hardware archive site. The 24-port Omni-Path edge switch costs $13,980, or about $583 per port, and the 48-port edge switch costs $20,695, or $431 per port. (The Omni-Path director switches are considerably more expensive, of course.)
Out point is that HPC centers will be weighing the factors of bandwidth, latency, price, and software compatibility very carefully in the coming years, and they will have more options than they have had in long time when it comes to interconnects.
Only five years ago, there were 219 systems on the Top500 list that employed Gigabit Ethernet interconnects, and another 7 machines used 10 Gb/sec Ethernet. InfiniBand accounted for 214 systems; the remaining 60 machines were spread across various custom interconnects. On the November 2015 list, InfiniBand at its various speeds accounts for 47.4 percent of systems and 36.2 percent of total sustained performance on the LINPACK test for those systems.
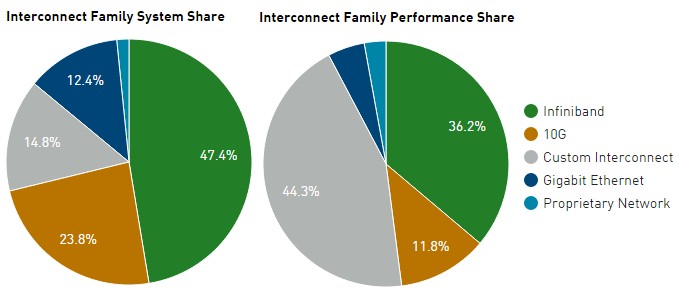
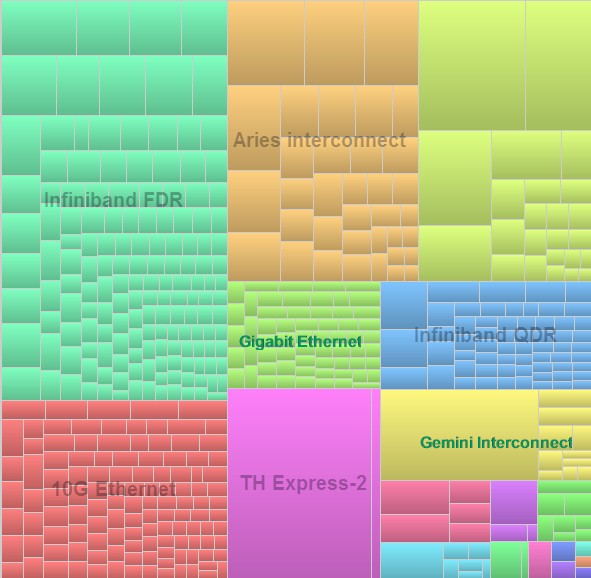
Custom interconnects, particularly the Cray Aries and the IBM BlueGeneQ, account for 14.8 percent of systems and 44.3 percent of total LINPACK capacity embodied on the November 2015 Top500 list. This, in a datacenter world that is utterly dominated by Ethernet excepting HPC and a minority of workloads at cloud builders and hyperscalers. If you like to drill down into the details, as we do at The Next Platform, here is the detailed table from the November list regarding installations by interconnect:

If you want to get a visual sense of the installed capacity by interconnect type, check out this tree graph:
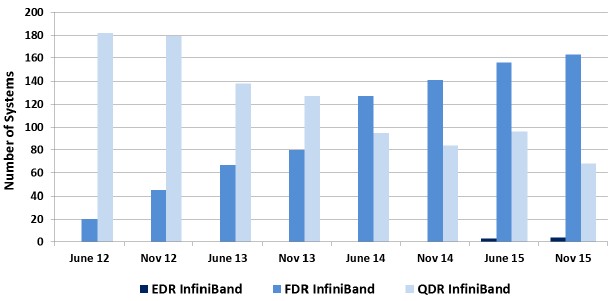
There are two systems on the Top500 list that have deployed 100 Gb/sec EDR InfiniBand – the “Hikari” machine built by Hewlett Packard Enterprise for the Texas Advanced Computing Center and the “Magic Cube II” machine built by Sugon for the Shanghai Supercomputer Center, and Mellanox says that it will have two more clusters running on its fastest InfiniBand by the end of the year. Gilad Shainer, vice president of marketing at Mellanox, told The Next Platform ahead of SC15 with tis Switch-IB 2 launch that the ramp for EDR InfiniBand – in terms of both revenue and port counts – was twice as fast as what Mellanox saw 56 Gb/sec FDR InfiniBand, and that the FDR ramp was faster than for 40 Gb/sec QDR InfiniBand. Here is what the transition looks like for the top speeds of InfiniBand for the past three and a half years:
Across the petaflops-class machines on the November 2015 Top500 list, Mellanox InfiniBand is used on 33 of the machines, Gemini and Aries interconnects from Cray are used on 25 machines, eight are using IBM’s BlueGene interconnect, and the remaining six are using other proprietary interconnects such as the Tofu interconnect from Fujitsu or the TH Express 2 interconnect from the National University of Defense Technology (NUDT) in China.
While QLogic had some traction in HPC before it sold off that business to Intel a few years back, the big question everyone wants an answer to is how will the new Omni-Path interconnect from Intel deliver in terms of price and price/performance compared to InfiniBand, Aries, and other options. Charles Wuischpard, general manager of the HPC Platform Group within Intel’s Data Center Group, said at SC15 that Omni-Path interconnects are involved in HPC cluster deals with over 100,000 server nodes and that this represents somewhere around 20 percent to 25 percent of the potential market for high-end interconnects such as InfiniBand, Aries, NUMALink, and others. Intel does not expect to capture all of that opportunity, but it will convert some of it. You can also count on makers and sellers of other interconnects to fight back very hard against Omni-Path, and the next effect will be very intense competition – and lower pricing – for all interconnects. Now is a good time to get some benchmarks ready for parallel simulations that will stress these high-end interconnects and put together a bakeoff for whatever systems you might want to install in 2016 or 2017.

The Pax Chipzilla Is Over, And Intel Can’t Hold Back The Barbarians
It is the nature of big tech companies with near monopolies to start looking a bit like Rome in its Golden Age – the Pax Romana that held from when Augustus Caesar became emperor in 27 BC until Marcus Aurelius died in 180 AD. During these peaceful times, all things …
Intel Unfolds Xeon Roadmap With More Cores, Denser Transistors
We were complaining a few weeks ago that Intel had not put out a server processor roadmap of any substance in a long time, and instead of just leaving it at that, we created our own Xeon SP roadmap based on rumors, speculation, hunches, and desires. In the absence of …
Intel’s First Discrete Xe Server GPU Aimed At Hyperscalers
We have been waiting for years to see the first discrete Xe GPU from Intel that is aimed at the datacenter, and as it turns out, the first one is not the heavy compute engine we have been anticipating, but rather a souped up version of the Iris Xe LP …
List prices for Omini-Path NICs and switches are now public on ark.intel.com (under High Performance Fabric category) and looks competitive:
1-port x8 HBA (58Gbs) – $528
1-port x16 HBA (100Gbs) – $958
24-port managed switch 1U – $13,980
48-port managed switch 1U – $20,695
etc. On the other hand, at this moment they looks like total vaporware in terms of retail availability.
Thanks for that. They were not available when we were doing our stories earlier in the week.