
The Power8-based “Barreleye” server being engineered by cloud and hosting provider and OpenStack champion Rackspace Hosting has moved off the drawing boards and into silicon, printed circuit board, and bent metal.
As The Next Platform reported back in March from the OpenPower Summit that was hosted by IBM, Google, Nvidia, Mellanox Technologies, and Tyan, the hardware engineers at Rackspace want to have an open technology stack, from the software that controls its cloud and bare metal servers out to the processors and firmware in its systems that run that software and all the way out to the system design, which is being donated to the Open Compute Project created by Facebook four and a half years ago to foment an open hardware ecosystem.
Seven months ago, Aaron Sullivan, the senior director and distinguished engineer at Rackspace who has been driving the company’s Open Compute server effort for the past several years, detailed the reasons why Rackspace would be adopting OpenPower variants of the IBM’s Power processors for servers in the future and why the company was going to the trouble of making its own motherboard and system designs, too. The upshot is a familiar theme here at The Next Platform: That at a certain scale, hyperscalers, cloud builders, and other service providers not only can afford to custom fit their hardware for their software, but they must do so to stay competitive. Rackspace has become an ardent proponent of open technologies since helping to launch the OpenStack cloud controller with NASA, which predates the Open Compute effort by nine months. IBM is licensing its Power8 processors and related system microcode under the auspices of the OpenPower Foundation, and that means Rackspace and others can create a completely open hardware and software stack – something they cannot do with an X86 stack at the moment and that is theoretically possible but not yet done with an ARM stack.
Rackspace refers to the Barreleye OpenPower-Open Compute system it is creating as a “megaserver,” meaning that it is designed to have more compute threads, more memory capacity, more memory bandwidth, and more I/O bandwidth than the standard two-socket Xeon server that dominates Rackspace’s datacenters and indeed those of most of the datacenters of the world. The machine is called a Barreleye in reference to the fish of that same name, which has a translucent head that makes it clear to see everything that is inside of its noggin.
Sullivan tells The Next Platform Rackspace has been working with supply chain partners IBM, Mellanox, Samsung, Avago Technologies, and PMC Sierra to get the components together for the Barreleye machine, and that it is using Taiwanese company Ingrasys Technology as the system integrator for the server. Sullivan declines to name whom Rackspace has tapped to help design and manufacture the motherboard, but Ingrasys is part of the Foxconn (Hon Hai Manufacturing) behemoth and could also be making the motherboard. It only matters inasmuch as others might want to follow suit with Rackspace and either adopt Barreleye systems or design their own equivalents, as Google itself is testing. Here is what the finished system and I/O board looks like:

The Barreleye system board is the larger one at the back with the two CPU sockets and the I/O board slots into it through passive links on the front of the board. By splitting the CPU and memory from the I/O at the board level, Rackspace will be able to upgrade each piece independently from the other and also mix and match different I/O for different workloads. The two Power8 processors are front and center of the system board, with their voltage regulators on the outside left and right.
Rackspace is employing IBM’s merchant silicon variants of the Power8 chips, and in this case, two variants of the “Tourismo” processor that IBM is also using in its single-socket “Habanero” Power Systems S814 LC machine announced two weeks ago. The Tourismo Power8 chip is what IBM calls a single-chip module, which means all of its cores, caches, memory and I/O controllers, and NUMA interconnect is implemented on a single die. IBM uses this Power8 SCM in its high-end SMP systems, and it has a maximum of twelve cores and is optimized for high memory capacity and bandwidth and has support for 32 PCI-Express 3.0 lanes. IBM has a slightly different mix of clock speeds, caches, and core counts for its own systems.
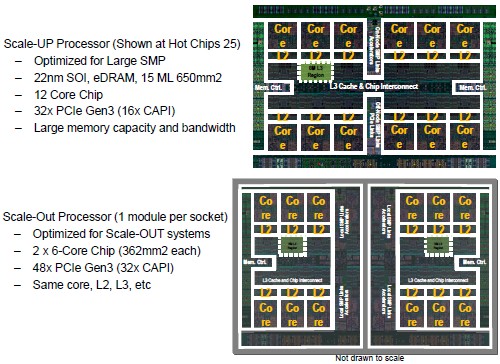
IBM’s own Power Systems and Power Systems LC (the latter can only run Linux) machines intended for scale-out clusters are based on what it calls dual-chip modules, or DCMs, and that means IBM is actually putting two six-core Power8 chips into a single socket. These Power8 variants (we do not know their code names) are optimized more for I/O scalability, with 48 lanes of PCI-Express 3.0 lanes. Both the Power8 SCM and DCM chips are implemented in a 22 nanometer process, which is now owned and controlled by Big Blue’s fab partner, Global Foundries.
The extra I/O for IBM’s own scale-out systems was aimed at offering more slots that support its Coherent Accelerator Processor Interface (CAPI) ports. These CAPI ports link accelerators such as GPUs, DSPs, or FPGAs into the virtualized main memory of the Power8 processor complex – in theory, at least. Thus far, CAPI is enabled on FPGAs (which you can do because they are inherently programmable) and in Mellanox ConnectX server adapter cards, but not with Nvidia GPUs. (Nvidia and IBM are instead adding support for NVLink clustering to future Tesla “Pascal” GPUs and future Power8+ CPUs.)
In any event, Rackspace is using three variants of the Tourismo Power8 chip in the Barreleye server: the first with eight cores running at 3.7 GHz and offering a turbo core speed bump up to 4.1 GHz provided there is thermal room in the system as it is running, the second with ten cores running at 3.4 GHz with a turbo to 3.9 GHz, and the third with twelve cores running at 3.1 GHz and boosting to 3.6 GHz. The Power8 chips have eight threads per core, which means a two-socket machine can bring 128, 160, or 192 threads to bear. The chips have more than 200 MB of combine L1, L2, and L3 cache memory, and Sullivan says that the Barreleye machine can deliver around 200 GB/sec of memory bandwidth. The Power8 chips in IBM’s homegrown systems – not those it is reselling based on designs from Tyan and Wistron, but those earlier two-socket machines – have processors that run at a few hundred megahertz faster and offer slightly higher memory bandwidth, too. While IBM does not provide thermal ratings for its own Power8 machines, we suspect they are a bit warmer, too – something that doesn’t matter in shops deploying a few machines but does add up among hyperscalers who want to deploy machines in the thousands and tens of thousands.
At the back of the Barreleye system board, you can see two rows of four of IBM’s “Centaur” memory buffer chips. These chips are akin to the memory buffer chips that Intel uses on its Xeon E7 processors, and in both cases, the buffers are necessary to balance memory expandability against the desired performance. In the case of IBM’s Centaur chips, the memory buffers also implement an L4 cache memory to help keep the Power8 memory and processor complex well fed with data. Each Centaur chip on the Barreleye has four DDR3 memory slots, which is half the number that the Centaur can, in theory support, but with 32 GB memory sticks that still gives the Barreleye machine 1 TB of memory to play with. If Rackspace wanted to splurge on 64 GB sticks, it could double that up to 2 TB, but that is probably not a very economical choice.

As for local storage, the Barreleye machine has a modular I/O cage, which you can see sticking its tongue out on the right side of the server above, that has a total of fifteen 2.5-inch drives that can be stacked in it. It is reasonable to assume that the machine will support a mix of SAS and SATA drives in both disk and flash types. The system has three PCI-Express 3.0 slots, one x16 and two x8s. The system conforms to the Open Rack specification from the Open Compute Project and employed by Facebook for its various server and storage infrastructure and by Rackspace for its OnMetal bare metal cloud service. The way Rackspace will be stacking up the Barreleye machines is a dozen in the base of the rack, then two switches for linking nodes, two power shelves to feed all the gear, and then another dozen Barreleye servers on top of that. That’s a total of 24 servers for up to 24 TB of memory and 4,608 threads in a single rack.
Rackspace is not divulging where it intends to use the Barreleye server just yet, but clearly it can be used to support any virtualized or bare metal Linux workload provided it runs on a Power-enabled Linux distribution. Sullivan says that Rackspace is still pondering the Linux OS variants – Canonical, Red Hat, and SUSE Linux all have little-endian versions of Linux tweaked to run on Power8 chips, and the CentOS, Fedora, and Debian variants are also possibilities. One thing for sure is that Rackspace will be supporting KVM as the hypervisor on these machines, not the commercial-grade XenServer that it uses on the Rackspace Cloud public cloud. As for the software stack, Sullivan says that most of the Linux repos “just work,” adding that it was not clear if it would be necessary to provide customers with X86-to-Power porting tools. He added that Docker containers and other tools that are dependent on the Go programming language are not quite ready yet because Go is still being tuned on Power, but that basic infrastructure that is commonly used on Linux machines is easy to use on Barreleye.
Sullivan says that Rackspace got the first Barreleye machines from Ingrasys back in August and shipped them to its San Antonio lab and out to selected development partners so they could take them for a spin. It has created a special portable power supply that conforms to the Open Rack specs that allows a single machine to be tested outside of a rack.
As for its own internal use of Barreleye machines, Sullivan says that Rackspace expects to start doing field trials for non-revenue producing services early next year, and the production launch will come a few months after these field trials start. “It all depends on how those field trials go,” says Sullivan.

Rackspace Goes All In – Again – On OpenStack
Rackspace Technology has admittedly been relatively quiet in recent years when it’s come to OpenStack, the open source cloud infrastructure platform that was born in 2010 out of the collaboration between the cloud computing company and NASA. It’s not that Rackspace turned its back on OpenStack. It’s contributed more than …

Will Open Compute Backing Drive SIOV Adoption?
Virtualization has been an engine of efficiency in the IT industry over the past two decades, decoupling workloads from the underlying hardware and thus allowing multiple workloads to be consolidated into a single physical system as well as moved around relatively easily with live migration of virtual machines. It is …

How Facebook Might Find Nervana For Machine Learning Training
There is a rumor going around that a certain hyperscaler is going to be augmenting its GPU-based machine learning training and will be adopting Intel’s Nervana Neural Network Processor (NNP) for at least some of its workloads. Some of the chattering lends itself to hyperbole, claiming that Facebook, the operator …
Price please? And also between the line I am reading that IBM keeps the good stuff for themselves I always thought that would eventually become the achilles kneel in the whole OpenPower thing as IBM is not playing ball as it would be directly competing with its so-called partners.
As far as I know, Rackspace is not planning to resell these machines, but the specs will be there for others to build them and you might even be able to go to Ingrasys to get a bunch.
As for IBM keeping the “best” stuff for itself, the modifications to the Power8 by the hyperscalers–lowering the clockspeeds and thermals but using the real 12-core chip–can’t really be characterized as IBM keeping the best stuff for themselves. Yes, IBM uses the Centaur chips differently, and it provides more memory bandwidth and capacity, but at the cost of much higher manufacturing cost that the hyperscalers won’t stomach. They used the tech in slightly different ways to get the costs and thermals down without sacrificing too much performance. There’s room for both approaches, I think.
Just a correction: IBM Power LC line is based on Single Chip modules not DCMs as stated.
http://www-01.ibm.com/common/ssi/ShowDoc.wss?docURL=/common/ssi/rep_oc/a/649/ENUS8335-GCA/index.html&lang=en&request_locale=en