
When Microsoft says that it is embracing Linux as a peer to Windows, it is not kidding. The company has created its own Linux distribution for switches used to build the Azure cloud, and it has embraced Spark in-memory processing and Cassandra as its data store for its first major open source big data project – in this case to help improve the quality of its Office365 user experience. And now, Microsoft is embracing Cassandra, the NoSQL data store originally created by Facebook when it could no longer scale the MySQL relational database to suit its needs, on the Azure public cloud.
Billy Bosworth, CEO at DataStax, the entity that took over steering development of and providing commercial support for Cassandra, tells The Next Platform that the deal with Microsoft has a number of facets, all of which should help boost the adoption of the enterprise-grade version of Cassandra. But the key one is that the Global 2000 customers that DataStax wants to sell support and services to are already quite familiar with both Windows Server in their datacenters and they are looking to burst out to the Azure cloud on a global scale.
“We are seeing a rapidly increasing number of our customers who need hybrid cloud, keeping pieces of our DataStax Enterprise on premise in their own datacenters and they also want to take pieces of that same live transactional data – not replication, but live data – and in the Azure cloud as well,” says Bosworth. “They have some unique capabilities, and one of the major requirements of customers is that even if they use cloud infrastructure, it still has to be distributed by the cloud provider. They can’t just run Cassandra in one availability zone in one region. They have to span data across the globe, and Microsoft has done a tremendous job of investing in its datacenters.”
With the Microsoft agreement, DataStax is now running its wares on the three big clouds, with Amazon Web Services and Google Compute Engine already certified able to run the production-grade Cassandra. And interestingly enough, Microsoft is supporting the DataStax implementation of Cassandra on top of Linux, not Windows. Bosworth says that while Cassandra can be run on Windows servers, DataStax does not recommend putting DataStax Enterprise (DSE), the commercial release, on Windows. (It does have a few customers who do, nonetheless, and it supports them.) Bosworth adds that DataStax and the Cassandra community have been “working diligently” for the past year to get a Windows port of DSE completed and that there has been “zero pressure” for the Microsoft Azure team to run DSE on anything other than Linux.
It is important to make the distinction between running Cassandra and other elements of DSE on Windows and having optimized drivers for Cassandra for the .NET programming environment for Windows.
“All we are really talking about is the ability to run the back-end Cassandra on Linux or Windows, and to the developer, it is irrelevant on what that back end is running,” explains Bosworth. This takes away some of that friction, and what we find is that on the back end, we just don’t find religious conviction about whether it should run on Windows or Linux, and this is different from five years ago. We sell mostly to enterprises, and we have not had one customer raise their hand and say they can’t use DSE because it does not run on Windows.”
What is more important is the ability to seamless put Cassandra on public clouds and spread transactional data around for performance and resiliency reasons – the same reasons that Facebook created Cassandra for in the first place.
What Is In The Stack, Who Uses It, And How
The DataStax Enterprise distribution does not just include the Apache Cassandra data store, but has an integrated search engine that is API compatible with the open source Solr search engine and in-memory extensions that can speed up data accesses by anywhere from 30X to 100X compared to server clusters using flash SSDs or disk drives. The Cassandra data store can be used to underpin Hadoop, allowing it to be queried by MapReduce, Hive, Pig, and Mahout, and it can also underpin Spark and Spark Streaming as their data stores if customers decide to not go with the Hadoop Distributed File System that is commonly packaged with a Hadoop distribution.
It is hard to say for sure how many organizations are running Cassandra today, but Bosworth reckons that it is on the order of tens of thousands worldwide, based on a number of factors. DataStax does not do any tracking of its DataStax Community edition because it wants a “frictionless download” like many open source projects have. (Developers don’t want software companies to see what tools they are playing with, even though they might love open source code.) DataStax provides free training for Cassandra, however, where it does keep track, and developers are consuming over 10,000 units of this training per month, so that probably indicates that the Cassandra installed base (including tests, prototypes, and production) is in the five figures.
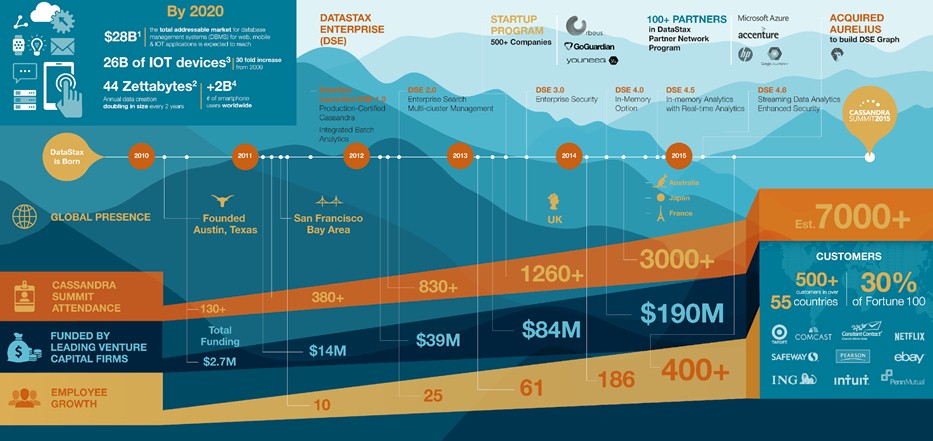
DataStax itself has over 500 paying customers – now including Microsoft after its partner tried to build its own Spark-Cassandra cluster using open source code and decided that the supported versions were better thanks to the extra goodies that DataStax puts into its distro. DataStax has 30 of the Fortune 100 using its distribution of Cassandra in one form or another, and it is always for transactional, rather than batch analytic, jobs and in most cases also for distributed data stores that make use of the “eventual consistency” features of Cassandra to replicate data across multiple clusters. The company has another 600 firms participating in its startup program, which gives young companies freebie support on the DSE distro until they hit a certain size and can afford to start kicking some cash into the kitty.
The largest installation of Cassandra is running at Apple, which as we previously reported has over 75,000 nodes, with clusters ranging in size from hundreds to over 1,000 nodes and with a total capacity in the petabytes range. Netflix, which used to employ the open source Cassandra, switched to DSE last May and had over 80 clusters with more than 2,500 nodes supporting various aspects of its video distribution business. In both cases, Cassandra is very likely housing user session state data as well as feeding product or play lists and recommendations or doing faceted search for their online customers.
We are always intrigued to learn how customers are actually deploying tools such as Cassandra in production and how they scale it. Bosworth says that it is not uncommon to run a prototype project on as few as ten nodes, and when the project goes into production, to see it grow to dozens to hundreds of nodes. The midrange DSE clusters range from maybe 500 to 1,000 nodes and there are some that get well over 1,000 nodes for large-scale workloads like those running at Apple.
In general, Cassandra does not, like Hadoop, run on disk-heavy nodes. Remember, the system was designed to support hot transactional data, not to become a lake with a mix of warm and cold data that would be sifted in batch mode as is still done with MapReduce running atop Hadoop.
The typical node configuration has changed as Cassandra has evolved and improved, says Robin Schumacher, vice president of products at DataStax. But before getting into feeds and speeds, Schumacher offered this advice. “There are two golden rules for Cassandra. First, get your data model right, and second, get your storage system right. If you get those two things right, you can do a lot wrong with your configuration or your hardware and Cassandra will still treat you right. Whenever we have to dive in and help someone out, it is because they have just moved over a relational data model or they have hooked their servers up to a NAS or a SAN or something like that, which is absolutely not recommended.”

Only four years ago, because of the limitations in Cassandra (which like Hadoop and many other analytics tools is coded in Java), the rule of thumb was to put no more than 512 GB of disk capacity onto a single node. (It is hard to imagine such small disk capacities these days, with 8 TB and 10 TB disks.) The typical Cassandra node has two processors, with somewhere between 12 and 24 cores, and has between 64 GB and 128 GB of main memory. Customers who want the best performance tend to go with flash SSDs, although you can do all-disk setups, too.
Fast forward to today, and Cassandra can make use of a server node with maybe 5 TB of capacity for a mix of reads and writes, and if you have a write intensive application, then you can push that up to 20 TB. (DataStax has done this in its labs, says Schumacher, without any performance degradation.) Pushing the capacity up is important because it helps reduce server node count for a given amount of storage, which cuts hardware and software licensing and support costs. Incidentally, only a quarter of DSE customers surveyed said they were using spinning disks, but disk drives are fine for certain kinds of log data. SSDs are used for most transactional data, but the bits that are most latency sensitive should use DSE to store data on PCI-Express flash cards, which have lower latency.
Schumacher says that in most cases, the commercial-grade DSE Cassandra is used for a Web or mobile application, and a DSE cluster is not set up for hosting multiple applications, but rather companies have a different cluster for each use case. (As you can see is the case with Apple and Netflix.) Most of the DSE shops to make use of the eventual consistency replication features of Cassandra to span multiple datacenters with their data stores, and span anywhere from eight to twelve datacenters with their transactional data.
Here’s where it gets interesting, and why Microsoft is relevant to DataStax. Only about 30 percent of the DSE installations are running on premises. The remaining 70 percent are running on public clouds. About half of DSE customers are running on Amazon Web Services, with the remaining 20 percent split more or less evenly between Google Compute Engine and Microsoft Azure. If DataStax wants to grow its business, the easiest way to do that is to grow along with AWS, Compute Engine, and Azure.
So Microsoft and DataStax are sharing their roadmaps and coordinating development of their respective wares, and will be doing product validation, benchmarking, and optimization. The two will be working on demand generation and marketing together, too, and aligning their compensation to sell DSE on top of Azure and, eventually, on top of Windows Server for those who want to run it on premises.
In addition to announcing the Microsoft partnership at the Cassandra Summit this week, DataStax is also releasing its DSE 4.8 stack, which includes certification for Cassandra to be used as the back end for the new Spark 1.4 in-memory analytics tool. DSE Search has a performance boosts for live indexing, and running DSE instances inside of Docker containers has been improved. The stack also includes Titan 1.0, the graph database overlay for Cassandra, HBase, and BerkeleyDB that DataStax got through its acquisition of Aurelius back in February. DataStax is also previewing Cassandra 3.0, which will include support for JSON documents, role-based access control, and a lot of little tweaks that will make the storage more efficient, DataStax says. It is expected to ship later this year.

Supercharging Cassandra NoSQL For Machine Learning
DataStax, the driving force behind the ongoing development of and commercialization of the open source NoSQL Apache Cassandra database, had been in business for nine years in 2019 when it made a hard shift to the cloud. The company had already been working with organizations whose businesses already stretched into …

The World Has Changed – Why Haven’t Database Designs?
It seems like a question a child would ask: “Why are things the way they are?” It is tempting to answer, “because that’s the way things have always been.” But that would be a mistake. Every tool, system, and practice we encounter was designed at some point in time. They …
Beefing Up A Cloudy NoSQL Database To Ride The AI Wave
To Andrew Davidson, senior vice president of products at MongoDB, the database business operates in an entirely different type of market than traditional software, where vendors might sell their products into one organization after another, eventually reaching a saturation point. They can grow fast, but it’s tough to keep that …
Be the first to comment