
DataStax, the driving force behind the ongoing development of and commercialization of the open source NoSQL Apache Cassandra database, had been in business for nine years in 2019 when it made a hard shift to the cloud.
The company had already been working with organizations whose businesses already stretched into hybrid and multicloud environments, but its “cloud first” strategy was designed to make it easier for the company to grow and easier for customers to consume Cassandra. This cloud first approach is shared by many established and startup software companies alike.
Back then, DataStax had just unveiled Constellation, a cloud data platform for developers to build newer application and operations teams to manage them, with the first offering on the platform being DataStax Apache Cassandra as a Service. A year later, the company announced its Astra database cloud service and in 2021 released a new version of Astra for serverless deployments.
The transition to the cloud was important in making it easier for enterprises to use Cassandra, according to Ed Anuff, chief product officer at DataStax.
“Cassandra has always had the power and scale that make it a choice for when you’re dealing with huge amounts of data, but operationally was always kind of challenging,” Anuff tells The Next Platform. “Making it something that is available turnkey in the cloud – elastic, scalable, serverless – so you don’t have to worry about how much data you have, it just automatically scales, that was a pretty big deal. It sounds pretty simple and straightforward, but the implementation and execution of it was non-trivial.”
The embrace of serverless furthered that, he says. Cassandra and other NoSQL databases – think Amazon Web Services DynamoDB and Google Cloud Firestore – handle and store large datasets in real-time scenarios and are designed to scale to grow with those datasets. With serverless, “it means that you don’t think about nodes, you don’t think about anything other than how many reads do I do, how many rates do I do, and how much data am I storing, which is a much more obviously natural and convenient way to do it. Cassandra used to give you that infinite scale, but it was very challenging to operate,” Anuff says.
With that in place, the next challenge became how to help organizations that are using DataStax and Cassandra-based technologies to collect massive amounts of data to then leverage those data streams to train artificial intelligence (AI) and machine learning (ML) models. There is a long list of major organizations that use Cassandra – either alone or via DataStax products – from Apple and Bloomberg to Saab, Federal Express, Visa, Uber, and T-Mobile. Netflix uses Cassandra to capture every piece of data that’s generated when a customer clicks on anything, he says. DataStax saw an opportunity in making this event-based data usable in machine learning use cases.
“The first challenge for people in succeeding with ML is they have to have the data,” Anuff says. “The good news is all of our customers have that data or they wouldn’t be using Cassandra. But there are gaps in how to leverage it so that you can use it to train models and use it so that you can feed those models in real time with prediction. Again, the thing about Cassandra is it’s the database that’s used to power applications. It’s not that database that you use for an app. It’s not a data warehouse. It’s not something that you use for after-the-fact analytics. Let me generate a report. It’s what you use for powering your applications in real time. That meant that as we thought about unlocking this data and using ML to do it, we needed a way that could function in that real-time setting.”
That’s where Kaskada comes in. The startup offers a platform aimed at making it easier for enterprises to use data in AI and ML operations. It’s now owned by DataStax, which this week announced it was buying the Seattle company for an undisclosed amount. The deal comes seven months after DataStax announced a $115 million financing round. Conversations between the two companies began in September. Kaskada’s co-founders, chief executive officer Davor Bonaci and chief technology officer Ben Chambers, came from Google, where they helped develop Google Cloud’s Dataflow managed streaming analytics service. DataStax itself, as it was putting its cloud initiative in place, brought in people from Google and other hyperscalers, Anuff says, including himself.
Kaskada’s focus was on the challenge of taking real-time data streams and using them to train machine learning models and to feed the models with data in real time to more quickly delivering insights and predictions. Such capabilities were what DataStax was looking for, he says. Organizations were collecting such large datasets in anticipation of using them in machine learning models, but had to take a do-it-yourself approach, according to Anuff. DataStax wanted to give them the tools to make it happen.
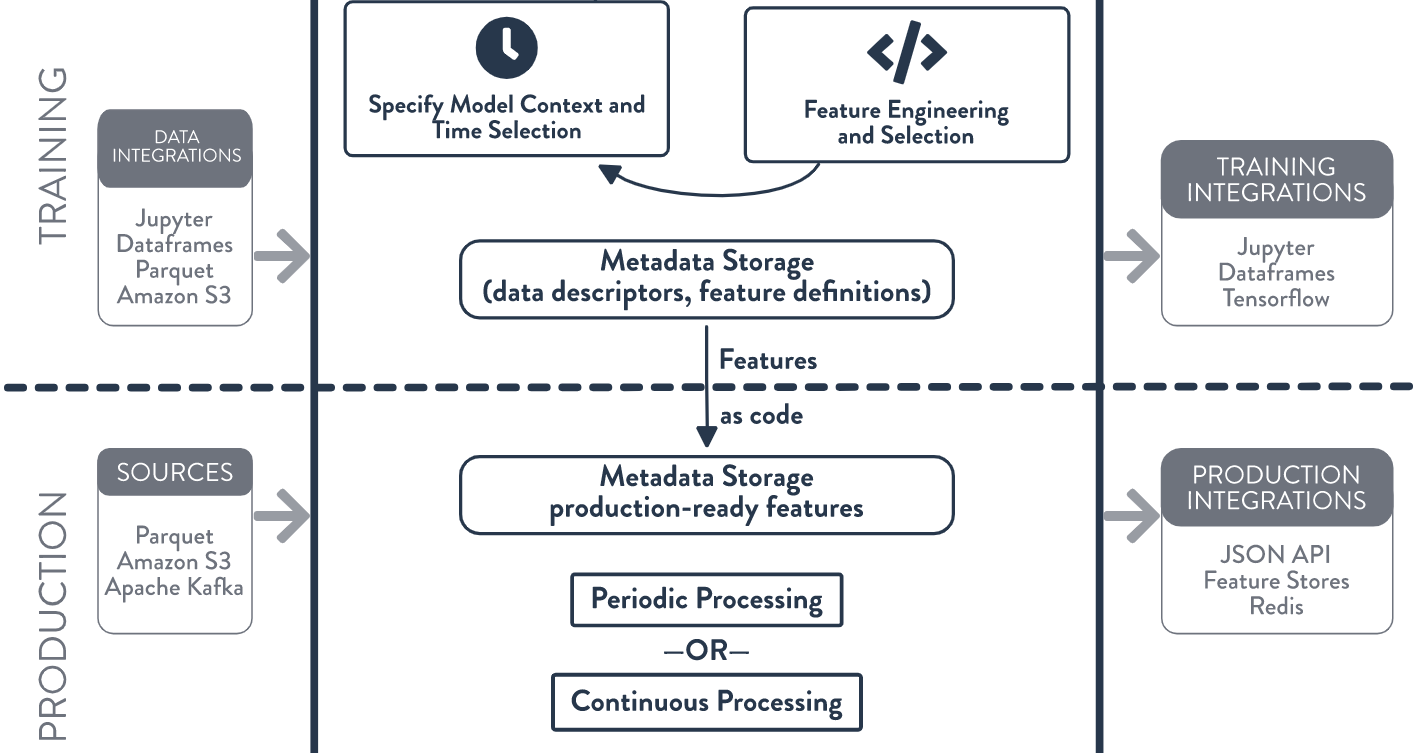
“We had the strategy. It was always part of what we wanted to do with the company, to take it in this direction, and what we found was that you had this last-mile problem in being able to extract this data,” he says. “What the term for this specifically is called ‘feature engineering’ and what Kaskada is a feature engine. When you combine the feature engine with the cloud data store, you now have this intense system for taking this data, being able to use it within your models and feeding it and serving it back into the applications. That’s why we’re able to move very quickly because it’s a in many ways what we’re doing. We’re paving the footpaths that people have been doing on top of Cassandra for a while. … What we knew was that real-time ML was going to be the place that we play.”
Kaskada was able to address a key hurdle to using these streams of event data for machine learning operations. It’s important when training a machine learning model to ensure that the in structure and shape, and within its components, to be precisely the same each time, Anuff says. The data now tends to be “somewhat choppy” as people go in and out of the data, which makes it more difficult to feed it into services like TensorFlow or PyTorch. They may offer different capabilities, but they all want the data in structured formats, he says. Companies now typically have data scientists and engineers handle this with Jupyter notebooks and tools like Spark. The job can get done, but it difficult and time-consuming, taking weeks.
“What the Kaskada team’s insight was to go and say, ‘The majority of this work is stuff that we can express in a very concise form of query,’ so that’s what they did,” Anuff says. “They came up with a way that you could describe this data format that you want to extract from the event streams to feed it into the model and made it in such a way that a data engineer can go and do it in a very short amount of time. It turns what might have been a two-week process into a two-hour process. It’s a major-step function in productivity. We looked at that and we said, ‘This is exactly what our users who have this data, who are struggling to unlock it within ML, would benefit from.’ That’s the idea.”
DataStax is looking to more quickly now that Kaskada is in the fold. The company plans to open source the core Kaskada technology as soon as it can and will launch a new machine learning service based on the startup’s technology later this year. In a blog post, DataStax chairman and chief executive officer Chet Kapoor wrote that companies like Google, Netflix, and Uber are able to embed their machine learning models in their applications using real-time data, with the data being expose to the models via streaming services. Kaskada’s technology will help DataStax bring such capabilities to other companies, Kapoor wrote.


The World Has Changed – Why Haven’t Database Designs?
It seems like a question a child would ask: “Why are things the way they are?” It is tempting to answer, “because that’s the way things have always been.” But that would be a mistake. Every tool, system, and practice we encounter was designed at some point in time. They …
Nvidia’s Next Major Wave Of AI Revenues
It is a good thing for Nvidia that most of the hyperscalers in the world – or at least the ones that matter – also have substantial public cloud businesses. While the hyperscalers can do anything they want to run their own applications, on any hardware that they want to …
Oracle Takes The Whole Nvidia AI Stack For Its Cloud
The top hyperscalers and clouds are rich enough to build out infrastructure on a global scale and create just about any kind of platform they feel like. They are just that rich, and by using their services at massive scale, all of us collectively pay for the many degrees of …
Be the first to comment