

While many recognize Yann LeCun as the inventor of convolutional neural networks, the momentum of which has ignited artificial intelligence at companies like Google, Facebook, and beyond, LeCun has not been strictly rooted in algorithms. Like others who have developed completely new approaches to computing, he has an extensive background in hardware, specifically, chip design, and this recognition of specialization of hardware, movement of data around complex problems, and ultimately, core performance, has proven handy.
LeCun’s research work at Bell Labs, which is where his pioneering efforts in deep learning began in earnest, coupled both novel hardware and software co-designs and even today, he is known for looping in the server side of the machine learning and neural network story–something he did skillfully this week at the Hot Chips conference. In addition to his presentation on the evolution (hardware and software) of neural nets from his experiences at Bell Labs, Facebook Research, and New York University (among other institutions), LeCun found time to talk with The Next Platform about the future of convolutional neural networks in terms of co-design.
Ultimately, he paints an unexpected portrait of what future architectures sit between current deep learning capabilities and the next stage of far smarter, more vast neural nets. What is interesting about LeCun’s view is not surprising necessarily: current architectures are not offering enough in terms of performance to stand up to the next crop of deep learning algorithms as it overextends current acceleration tools and other programmatic limitations.
 As described back in May when we talked to LeCun about the role of GPU computing for deep learning, we walked away with the understanding that the GPU acceleration approach, while useful for training neural networks at massive scale, would have to evolve to tackle the other side of processing–of running the actual algorithms post-training. This week, LeCun extended that argument, explaining that most training models are run on server nodes with four to eight GPUs and that Google and Facebook are working on ways to run training algorithms in parallel across multiple nodes with this setup. He also notes that although the general guess about how many GPUs Google has is somewhere around 8,000, it is actually quite a bit larger than that–scaling as it likely does with growing photo, video, and other datasets.
As described back in May when we talked to LeCun about the role of GPU computing for deep learning, we walked away with the understanding that the GPU acceleration approach, while useful for training neural networks at massive scale, would have to evolve to tackle the other side of processing–of running the actual algorithms post-training. This week, LeCun extended that argument, explaining that most training models are run on server nodes with four to eight GPUs and that Google and Facebook are working on ways to run training algorithms in parallel across multiple nodes with this setup. He also notes that although the general guess about how many GPUs Google has is somewhere around 8,000, it is actually quite a bit larger than that–scaling as it likely does with growing photo, video, and other datasets.
But perhaps more interesting is the idea that FPGAs are the reconfigurable device that might next on the neural network agenda for processing the larger nets (while GPUs remain the high performance training mechanism). In a very interesting admission, LeCun told The Next Platform that Google is rumored to be building custom hardware to run its neural networks and that this hardware is said to be based on FPGAs. As we reported elsewhere this week at The Next Platform, Microsoft is testing out the idea of using FPGAs to accelerate its neural nets and is looking forward to the availability of much more powerful programmable logic devices.
The assumption here is that if Google is doing something and Microsoft is experimenting, chances are so is Facebook, along with several other companies that sit on the bleeding edge of neural networks at scale. Although little has helped us come close to understanding the $16.7 billion investment Intel made in purchasing Altera, statements like these do tend to switch on little lightbulbs. LeCun says that when it comes to the Google and Facebook scale, there is a wariness of using proprietary hardware. “They will actually use their own or use something that is programmable,” he noted, which pushes the FPGA door open a slight bit wider.
So just what does all of this mean in terms of the future of this particular hardware approach for next-generation neural net processing? To put all of this in some context, take a look at the slide below from LeCun’s presentation this week that shows just how deep the convolutional neural networks go for facial recognition. What began, at the early stages of LeCun’s career as a set of tasks to simply classify an image (plane versus car, for instance) has now become so sophisticated that Facebook, one of the most (publicly) extensive users of neural networks for image recognition, can search 800 million people to find a single face in 5 seconds.
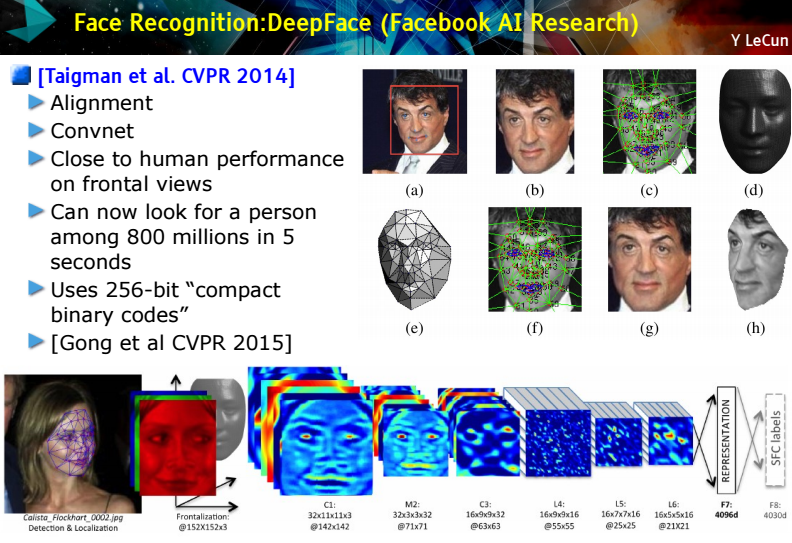
The software side of this problem has been tackled elsewhere, most recently in conversations about open source efforts like Torch, Caffee, and other frameworks. But when it comes to the next generation of hardware for both training neural networks and efficiently running them at scale, how is a balance struck, especially considering the relatively “basic” computational needs (fast training on massive datasets, followed by highly parallelizable add/multiply operations?).
These are not new questions for LeCun. During his time at Bell Labs in the 1980s and early 1990s, LeCun and colleagues embarked down an early path toward custom hardware for convolutional neural nets. Among the developments in this area was the ANNA chip, which never found its way into commercial applications for Bell Labs (or elsewhere) but did signify how specialty hardware, in this case a “simple” analog multiplier, could be fine-tuned to chew through neural nets far better than existing general purposes processors. In fact, at the time, the ANNA chip was capable of some impressive feats, including the ability to perform four billion operations per second—quite an accomplishment in 1991, especially for a class of problems that was still emerging.
And if you take a close look at the ANNA chip, it might become apparent that the goals haven’t changed much. For instance, the benefit of the chip to circuit design of ANNA is that it could limit traffic with the external memory, which meant the speed of the chip was not limited by how much computation could be put on the processor—rather, it was affected far more by how much bandwidth was available to talk to the outside. That design concept is coming full circle in the multicore world, but what it had in performance it lacked in complexity. And by design, of course. After all, what is the use of having an extensive array of capabilities that aren’t needed? And here that “configurability” term raises its head again.
 There has already been a fair bit of work done on FPGAs for convolutional neural networks, LeCun says. For instance, he points to an early experiment in scene parsing and labelling in the early 2000s where the team was able to achieve reasonable accuracy at 50 milliseconds per frame using a Virtex-6 FPGA. While this was an ideal processing framework that involved no post-processing of the data, the inherent limitation of Ethernet at the time limited overall system performance. (Similarly, there were other limitations when the next iteration of this idea on Virtex FPGA was rolled out in the NetFlow architecture, which never made it into production due to fab problems—but this was quite a bit later).
There has already been a fair bit of work done on FPGAs for convolutional neural networks, LeCun says. For instance, he points to an early experiment in scene parsing and labelling in the early 2000s where the team was able to achieve reasonable accuracy at 50 milliseconds per frame using a Virtex-6 FPGA. While this was an ideal processing framework that involved no post-processing of the data, the inherent limitation of Ethernet at the time limited overall system performance. (Similarly, there were other limitations when the next iteration of this idea on Virtex FPGA was rolled out in the NetFlow architecture, which never made it into production due to fab problems—but this was quite a bit later).
Right around the time of the first Virtex-6 work, however, GPU computing was entering the scene, which proved useful for LeCun’s continued work. He points to this, coupled with other developments to push image recognition in particular, including the release of the 1.2 million training samples in 1000 categories that were part of the ImageNet dataset as revolutionary new capabilities. The opportunities to train and classify were exponentially increased and the performance of an Nvidia GPU, which at the time was able to process the data at over one trillion operations per second, created an entirely new playing field.
If what is needed to build an ideal hardware platform for deep neural networks is ultra-fast add/multiply capabilities for the actual processing on the neural network algorithm, it stands to reason that something “programmable” (possibly an FPGA) might serve as that base while the the mighty GPU should own the training space. To some extent, it has for some time, with new crops of deep learning use cases from Nvidia and a wealth of examples of large companies that are leveraging GPUs for extensive model training, although not as many for actually handling the processing of the network itself.

LeCun provided a great slide that shows what the hardware options are for deep learning. While GPUs dominate on the large-scale training side, there are also a number of other emerging technologies that have yet to hit full primetime and await an ecosystem.


“No Quick Fixes” As Intel Losses And Restructurings Continue
Intel’s new chief executive officer, Lip-Bu Tan, has his work cut out for him, just like his predecessor, Pat Gelsinger, did several years ago. And given the even worse state that Intel is in – generating less cash on lower sales and therefore making it that much harder to raise …
Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …

How Much Of A Premium Will Nvidia Charge For Hopper GPUs?
There is increasing competition coming at Nvidia in the AI training and inference market, and at the same time, researchers at Google, Cerebras, and SambaNova are showing off the benefits of porting sections of traditional HPC simulation and modeling code to their matrix math engines, and Intel is probably not …
But ConvNets are just the tip of the iceberg what you really want are the more general RNNs mixed with evolutionary / genetic algorithms as they can learn by themselves and do not need human supervision as ConvNet does.