

There is increasing competition coming at Nvidia in the AI training and inference market, and at the same time, researchers at Google, Cerebras, and SambaNova are showing off the benefits of porting sections of traditional HPC simulation and modeling code to their matrix math engines, and Intel is probably not far behind with its Habana Gaudi chips.
And yet, there seems little question that Nvidia will charge a premium for the compute capacity on the “Hopper” GPU accelerators that it previewed back in March and that will be available sometime in the third quarter of this year. We did our initial pass on the Hopper GPUs here and a deep dive on the architecture there, and have been working on a model to try to figure out what it might cost and to reckon what it might be worth based on its feeds and speeds relative to past GPU accelerators from Nvidia.
As we were working on this, there was one report out of a workstation and HPC reseller in Japan called GDep Advance that shows the single unit street price of the GH100 accelerator with the PCI-Express 5.0 interface will cost a stunning $32,995. (It is actually priced in Japanese yen at ¥4.313 million, so the US dollar price inferred from this will depend on the dollar-yen conversion rate.) That seems like a crazy high price to us, especially based on past pricing on GPU accelerators from the “Kepler” and “Pascal” and “Volta” and “Ampere” generations of devices.
Nvidia does not release suggested retail pricing on its GPU accelerators in the datacenter, which is a bad practice for any IT supplier because it gives neither a floor for products in short supply, and above which demand price premiums are added, or a ceiling for parts from which resellers and system integrators can discount from and still make some kind of margin over what Nvidia is actually charging them for the parts.
And so, we are left with doing math on the backs of drinks napkins and envelopes, and building models in Excel spreadsheets to help you do some financial planning not for your retirement, but for your next HPC/AI system.
Right off the bat, let’s start with the obvious. The performance metrics for both vector and matrix math in various precisions have come into being at different times as these devices have evolved to meet new workloads and algorithms, and the relative capacity of the type and precision of compute has been changing at different rates across all generations of Nvidia GPU accelerators. And that means what you think will be a fair price for a Hopper GPU will depend in large part on the pieces of the device you will give work most.
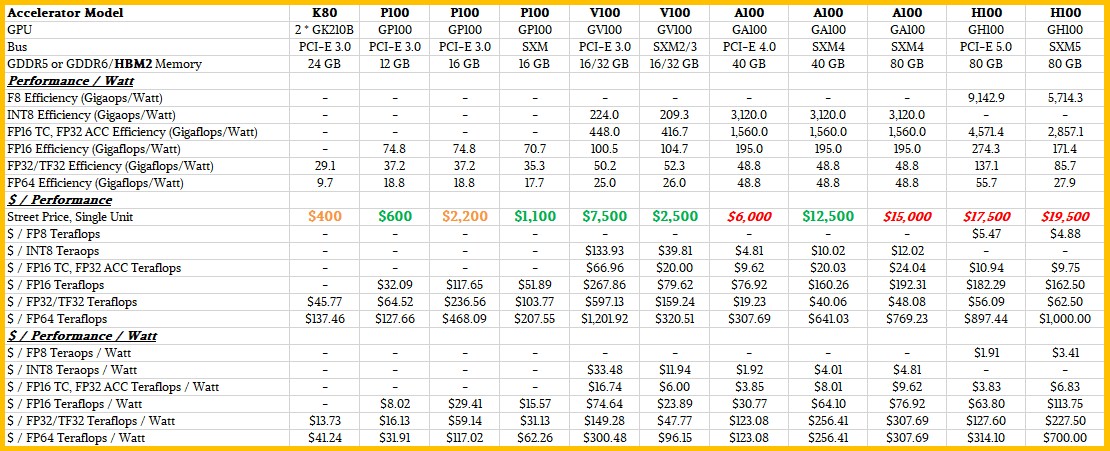
If memory capacity and memory bandwidth alone determined the price of the H100 GPU accelerator, the math would be easy. If memory capacity and I/O bandwidth were the main concern, then a PCI-Express 5.0 H100 card with 80 GB, which has twice as much memory and twice as much I/O bandwidth as an A100 card based on the PCI-Express 4.0 bus (but only 28.6 percent higher memory bandwidth at 1.95 TB/sec), and so it would be worth twice as much. Pricing is all over the place for all GPU accelerators these days, but we think the A100 with 40 GB with the PCI-Express 4.0 interface can be had for around $6,000, based on our casing of prices out there on the Internet last month when we started the pricing model. So, an H100 on the PCI-Express 5.0 bus would be, in theory, worth $12,000.
Similarly, with the same crude pricing model, an H100 SXM5 chips would, in theory, sell for about $25,000 because it has twice the memory as the original 40 GB implementation of the A100 using the SXM4 interface (but only 47.1 more memory bandwidth at 2.93 TB/sec).
Would that it could be this easy. It isn’t.
It would similarly be easy if GPU ASICs followed some of the pricing that we see in other areas, such as network ASICs in the datacenter. In that market, if a switch doubles the capacity of the device (same number of ports at twice the bandwidth or twice the number of ports at the same bandwidth), the performance goes up by 2X but the price of the switch only goes up by between 1.3X and 1.5X. And that is because the hyperscalers and cloud builders insist – absolutely insist – that the cost of shifting a bit around the network go down with each generation of gear that they install. Their bandwidth needs are growing so fast that costs have to come down or the network will eat their datacenter budgets alive and ask for desert. And network ASIC chips are architected to meet this goal.
Nvidia is architecting GPU accelerators to take on ever-larger and ever-more-complex AI workloads, and in the classical HPC sense, it is in pursuit of performance at any cost, not the best cost at an acceptable and predictable level of performance in the hyperscaler and cloud sense. If AI models were more embarrassingly parallel and did not require fast and furious memory atomic networks, prices would be more reasonable.
We have our own ideas about what the Hopper GPU accelerators should cost, but that is not the point of this story. The point is to give you the tools to make your own guesstimates, and then to set the stage for when the H100 devices actually start shipping and we can plug in the prices to do the actual price/performance metrics.
So, let’s start with the feeds and speeds of the Kepler through Hopper GPU accelerators, focusing on the core compute engines in each line. The “Maxwell” lineup was pretty much designed just for AI inference and basically useless for HPC and AI training because it had minimal 64-bit floating point math capability. Our full model has these devices in the lineup, but we are taking them out for this story because there is enough data to try to interpret with the Kepler, Pascal, Volta, Ampere, and Hopper datacenter GPUs.
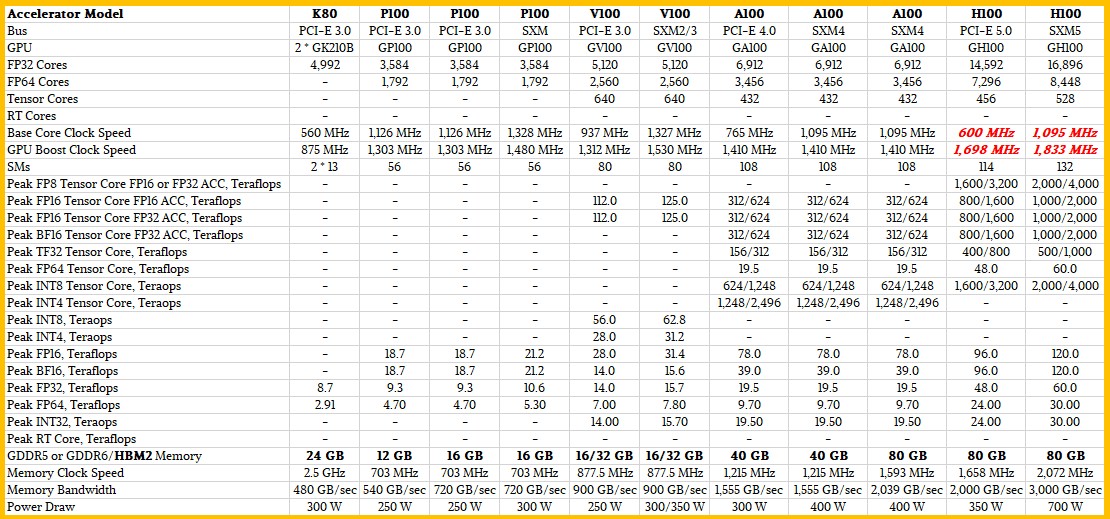
To make things simpler, we have taken out the base performance and only shown the peak performance with GPUBoost overclocking mode on at the various precisions across the vector and math units in the GPUs. Where you see two performance metrics, the first one is for the base math on a Tensor Core and the other one is for when sparsity matrix support is activated, effectively doubling the performance without sacrificing much in the way of accuracy.
Stacking up all of these performance metrics is tedious, but is relatively easy. The hard bit is trying to figure out what the pricing has been and then inferring – you know, in the way human beings are still allowed to do – what it might be.
Luckily, Nvidia’s launch cadence is amazingly regular. Every two years in the spring to early summer, Nvidia did a major GPU accelerator launch at the GPU Technology Conference and we cased the market for prior GPUs to compare prices for the new GPUs. And thus we have prices over time for the core PCI-Express cards here:
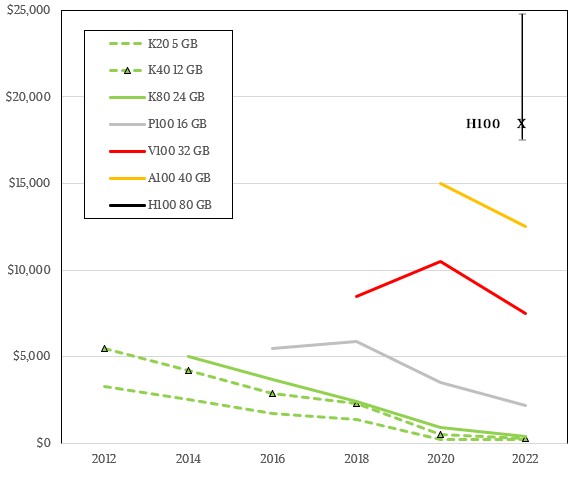
And for SXM sockets here:

The prices shown above show the prevailing costs after the devices had been launched and shipping, and it is important to remember that due to shortages, sometimes the prevailing price is higher than when the devices were first announced and orders were coming in. For instance, when the Ampere lineup came out, The 40 GB SXM4 version of the A100 had a street price at several OEM vendors of $10,000, but due to heavy demand and product shortages, the price rose to $15,000 pretty quickly. Ditto for the 80 GB version of this card that came out in late 2020, which was selling for around $12,000 at the OEMs, and then quickly spiked to $17,500. We show the top price for the year in each the chart above. And do not have enough data to do monthly wiggles. The data is too thin and all over the place depending on tight supplies at various vendors anyway. These charts are meant to be illustrative.
Based on all of these trends, and eyeballing it, we think that there is a psychological barrier above $25,000 for an H100, and we think Nvidia would prefer to have the price below $20,000. But as we have pointed out, depending on the metric used, we could argue for a price on these devices between $15,000 to $30,000 pretty easily. The actual price will depend on the much lower price that hyperscalers and cloud builders are paying and how much profit Nvidia wants to get from other service providers, governments, academia, and enterprises.
If you put a gun to our head, and based on past trends and the desire to keep the price per unit of compute steady moving between the A100 to the H100, we think the PCI-Express version of the H100 should sell for around $17,500 and the SXM5 version of the H100 should sell for around $19,500. Based on history and assuming very strong demand and limited supply, we think people will pay more at the front end of shipments and there is going to be a lot of opportunistic pricing – like at the Japanese reseller mentioned at the top of this story. We put error bars on the pricing for this reason. But you can see there is a pattern, and each generation of the PCI-Express cards costs roughly $5,000 more than the prior generation. And ignoring some weirdness with the V100 GPU accelerators because the A100s were in short supply, there is a similar, but less predictable, pattern with pricing jumps of around $4,000 per generational leap.
But as we said, with so much competition coming, Nvidia will be tempted to charge a higher price now and cut prices later when that competition gets heated. Make the money while you can. Sun Microsystems did that with the UltraSparc-III servers during the dot-com boom, VMware did it with ESXi hypervisors and tools after the Great Recession, and Nvidia will do it now because even if it doesn’t have the cheapest flops and ints, it has the best and most complete platform compared to GPU rivals AMD and Intel.
We have two thoughts when pondering pricing. First, when that competition does start, what Nvidia could do is start allocating revenue for its software stack and stop bundling it into its hardware. It would be best to start doing this now, which would allow it to show hardware pricing competitiveness with whatever AMD and Intel and their partners put into the field for datacenter compute. And second, Nvidia devotes an enormous amount of money to software development and this should be a revenue stream that has its own profit and loss statement. (Remember, 75 percent of the company’s employees are writing software.)
Our second thought is that Nvidia needs to launch a Hopper-Hopper superchip. You could call it an H80, or more accurately an H180, for fun. Making a Hopper-Hopper package would have the same thermals as the Hopper SXM5 module, and it would have 25 percent more memory bandwidth across the device, 2X the memory capacity across the device, and have 60 percent more performance across the device. To be more precise, such a device would have 160 GB of HBM3 memory, 4 TB/sec of memory bandwidth, and 120 teraflops of FP64 compute on the Tensor Cores with sparsity on and 60 teraflops of vector FP64 on a single card.
Sometime in the future, we think we will in fact see a twofer Hopper card from Nvidia. Supply shortages for GH100 parts is probably the reason it didn’t happen, and if supply ever opens up – which is questionable considering fab capacity at Taiwan Semiconductor Manufacturing Co – then maybe it can happen. In the meantime, if demand is higher than supply and the competition is still relatively weak at a full stack level, Nvidia can – and will – charge a premium for Hopper GPUs.

Energy Giant Eni Boosts Its HPC Oomph By An Order Of Magnitude
The big oil and gas companies of the world were among the earliest and most enthusiastic users of advanced machinery to do HPC simulation and modeling. The reason for these decades of experimentation and investment was simple: If you can figure out where the oil and gas is – and …
Cadence Sells Custom GPU Supercomputers To Run New CFD Code
If money and time were no object, every workload in every datacenter of the world would have hardware co-designed to optimally run it. But that is obviously not technically or economically feasible. Just the same, sometimes a workload is so important that it warrants a highly tailored system to run …

Taking A Superhybrid Approach To HPC/AI Convergence
AMD has been on such a run with its future server CPUs and server GPUs in the supercomputer market, taking down big deals for big machines coming later this year and out into 2023, that we might forget sometimes that there are many more deals to be done and that …
Be the first to comment