

Apache Hama is a distributed framework based on a bulk synchronous parallel computing approach that is designed to efficiently tackle select problems that Hadoop chokes on, including graph and matrix algorithms.
Although its Apache release was relatively recent (last March), Hama has been around since 2010 after capitalizing on some of the early successes of the Pregel graph computing approach developed by Google. At the high level, Hama sits on top of Hadoop and provides an opportunity for HPC centers with existing Hadoop clusters to move MapReduce jobs over a framework better suited for scientific computing applications. There are similarities between Hama and Hadoop, but for those with high performance computing applications, the most important difference is that with Hama, those all-important bulk synchronous parallel (BSP) parts of the job can communicate, which is something one would not ask MapReduce to do.
There are a few noteworthy sites and projects that leverage Apache Hama for high performance computing purposes, with users that include General Dynamics Mission Systems (details about their porting process here) and at Samsung, where the project’s founder is embedded in research and development. As development continues, one might expect to see more Hama for HPC, although there are still a few limitations that we will get to in a moment.
Hama’s creator, Edward Yoon, saw value in the ability for communication on BSP nodes early on. He joined the Korean electronics giant at about the same time the code went into Apache live preview state and still serves as CEO of of DataSayer, which is trying to commercialize some key work around Hama by adding MPI capabilities based on the core bulk synchronous parallel model that sets Hama apart. He has contributed a great deal of code to both the MRQL query processing system that sits on top of Hadoop and Hama and was also active in building out Apache BigTop. He worked with Hadoop and HBase in their infancy, developing the distributed computing system called Nebula for large-scale data analysis at NHN, then spent two years as a mentor at Google, further refining the Apache projects he helped spin out.
Much of Yoon’s work has fed into a recent upsurge in interest around Hama for HPC applications and while it is limited by nature of the relatively few HPC sites that have dedicated Hadoop clusters, there are some promising benchmarks. For instance, a research team in Beijing compared HAMA versus Hadoop on a modest four-node cluster using a Monte Carlo Pi algorithm to test performance.
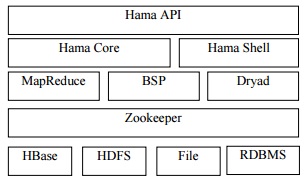 Before we get to their findings, it is useful to highlight where Hama sits in relation to Hadoop. As shown on the right, many of the standard elements of Hadoop sit beneath Hama—it’s the communication layer and approach that are unique. The technical explanation, as given by Yoon, is that Hama delivers a parallel matrix computational package, which provides an library of matrix operations for the large-scale processing development environment and Map/Reduce framework for the large-scale Numerical Analysis and Data Mining, which need the intensive computation power of matrix inversion (linear regression, PCA, SVM, for example).
Before we get to their findings, it is useful to highlight where Hama sits in relation to Hadoop. As shown on the right, many of the standard elements of Hadoop sit beneath Hama—it’s the communication layer and approach that are unique. The technical explanation, as given by Yoon, is that Hama delivers a parallel matrix computational package, which provides an library of matrix operations for the large-scale processing development environment and Map/Reduce framework for the large-scale Numerical Analysis and Data Mining, which need the intensive computation power of matrix inversion (linear regression, PCA, SVM, for example).
“Currently, several shared-memory based parallel matrix solutions can provide a scalable and high performance matrix operations, but matrix resources can not be scalable in the term of complexity. And, Hadoop HDFS Files and Map/Reduce can only used by 1D blocked algorithm. Hama approach proposes the use of 3-dimensional row and column (qualifier), Time space and multi-dimensional columnfamilies of HBase, which is able to store large sparse and various type of matrices (e.g. Triangular Matrix, 3D Matrix, and etc.) and utilize the 2D blocked algorithm. its auto-partitioned sparsity sub-structure will be efficiently managed and serviced by Hbase. Row and Column operations can be done in linear-time, where several algorithms, such as structured Gaussian elimination or iterative methods, run in O(the number of non-zero elements in the matrix / number of mappers) time on Hadoop Map/Reduce.”
The benchmark results from the comparison between Hadoop and Hama for the representative algorithm highlighted a few interesting points. First, the performance of Hama versus Hadoop was hands-down in favor of Hama, but there was a caveat—the more iterations meant far weaker performance. The BSP part of the process is where the logjam tends to happen, but according to this particular study, if the iterations are kept under a certain number (cannot be identified since it depends on an experiment’s data and requirements) the performance benefits are quite impressive.The Hama teams have built out a more developed approach to Hama over Infiniband as well bolstering Hama’s use with both Mesos and YARN and according to the roadmap that has been published, are seeking to address the BSP overhead.

The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
I think Hama sort of missed its chance, but it was always going to be difficult for it coming on to the scene when it did. Graph APIs exist now for tools that were always in memory, but emerged not long after Hama, like Spark (GraphX) and Flink (Gelly); and those give you similar functionality but well integrated into a framework which always supported in-memory iteration. It’s hard to see what Hama gives a new developer at this point.
Hi Jonathan,
I admit that the eco-system around Spark is really strong and right now it covers everything from massive datasets batch processing to streaming. By the way, I could be wrong, but from what I’m seeing, they started to use some external accessory frameworks, such as tachyon and parameter server. It means that Spark can’t cover everything efficiently. So, I still think, if communications among processors are unavoidable, BSP is always better.
Also, I found some interesting research paper:
“Both the disk based method, i.e., MR, and the memory based method, i.e., BSP and Spark, need to load the data into main memory and conduct the expensive computation. However, when processing top k joins, BSP is clearly the best method as it is the only one that is able to perform top-k joins on large datasets. This is because BSP supports the frequent synchronizations between workers when performing the joining procedure, which quickly lowers the joining threshold for a given k. The winner between the MR and the Spark algorithms change
from datasets to datasets: Spark is beaten by MR on A and B while beats MR on C.” -http://www.ruizhang.info/publications/TPDS2015-Heads_Join.pdf
Edward
You suggest that BSP communication in HAMA is better. The General Dynamics article referenced above seems to suggest that MPI communication is better than BSP communication. Can you comment?
Don
Don
To be more exact, BSP and Async algorithms should be compared. BSP is quite abstract concept. I mean, if communications among processors are unavoidable, BSP is better approach than Async. MPI provides fast message passing and flexible but does not support fault-tolerance well. and old version of Apache Hama seems used for GD’s experiments. 🙂