
The compute business at graphics chip maker Nvidia is still dominated by the Tesla coprocessors that are used to accelerate simulations and models on workstations and clusters of servers. The company has been expanding into new markets, and the big focus this year is on deep learning – what we used to call machine learning – and has been working on improvements to its software stack that allow algorithms to be trained on larger data sets and run a lot faster on the same iron.
Deep learning is hardly a nascent field, but it is one that has become increasingly important as companies are wrestling with massing amounts of text, image, and video data that cannot be parsed and organized with any kind of speed by human beings. People may be good at classifying such data, but we are nowhere near as fast as some of the algorithmic techniques that have been developed in recent years by Google, Baidu, Yahoo, Facebook, and other titans of the Web that have been pushing the deep learning envelope.
For image recognition algorithms, people painstakingly classify a database of images such as ImageNet, and this database is then used to train deep learning algorithms, using what is called convolutional neural network software, to recognize what is in the images. Having trained an algorithm to know how to classify images, often using GPU accelerators, these are then set loose on a large set of images – perhaps an image library at a major hyperscaler – to classify them as part of a service. The concepts behind deep learning for image classification can be applied, in a general sense, to text, voice, and video data to improve the way that applications interact with our data and, therefore, with us. The deep learning techniques can also be used for search, fraud detection, and a slew of other applications where people are not so directly involved.
The rise of GPUs to train models for deep learning is perhaps best illustrated by the ImageNet Large Scale Visual Recognition Challenge, which has been running since 2010 and which has seen the error rate for image classification drop dramatically as the use of GPUs has risen.
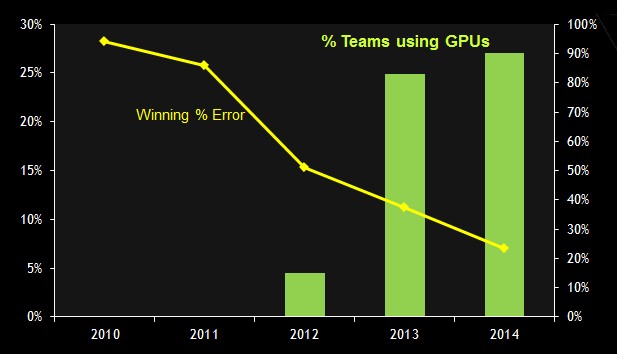
The first GPU-accelerated deep neural network to run the ImageNet challenge came in 2012 and as you can see there was a big drop in the error rate. Since that time, as algorithms have improved and the majority of teams competing in the ImageNet challenge had shifted to hybrid CPU-GPU machines to train their models, the error rate continues to go down.
Nvidia is obviously very keen on pointing this out because it will help sell its high-end GPU cards to those who want to train their deep learning algorithms. The expectation is that most companies will make use of image, video, and text recognition software on their datasets at some point, just like everyone believes that ultimately they will use a mix of operational, transactional, and other kinds of unstructured data and complex analytics software to help them find and retain customers or run their businesses better. It remains to be seen how pervasive deep learning and big data analytics workloads will become, but it is safe to say that the largest companies with the largest datasets are clearly pushing the envelope on both fronts. (See our discussion with deep learning pioneer Yann LeCun for more details on the issues they face.)
At the International Conference on Machine Learning this week in France, Nvidia rolled out improvements to its CUDA development environment for accelerating applications with GPUs that will substantially improve the performance of deep learning algorithms on a couple of fronts.
The first big change is that CUDA 7.5 supports mixed precision, which means it supports FP16 16-bit data as well as the normal 32-bit single precision and 64-bit double-precision floating point data types. “The change to 16-bits allows researchers to store twice as large of a network,” explains Ian Buck, vice president of accelerated computing at Nvidia, to The Next Platform. “And though you lose some precision with the 16-bit numbers, the larger model more than makes up for that and you actually end up getting better results.”
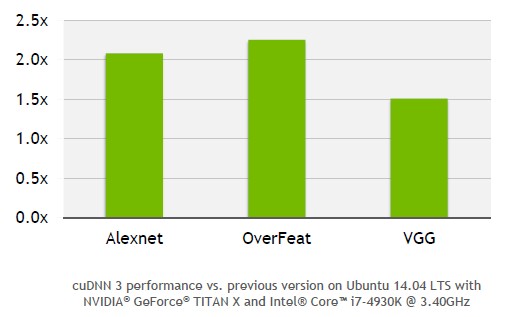
The FP16 support is in the base CUDA 7.5 and is also available to the CUDA Deep Neural Network Library, or cuDNN, software that Nvidia first rolled up last September when it started going after the deep learning market in a big way. The cuDNN software has hooks into popular deep learning frameworks such as Caffe, Minerva, Theano, and Torch and allows their algorithms to be parallelized and offloaded to GPUs so they can run in an accelerated fashion. With the cuDNN 3 software announced this week, not only can larger models be stored in the GDDR5 frame buffer memory of the GPU, but Nvidia has added support for fast Fourier transform (FFT) convolutions and has optimized 2D convolutions for neural nets that allow for deep learning training models to run roughly twice as fast. Here is what the speedup look like on some frameworks that Nvidia has put through the paces using its GeForce Titan X GPUs:
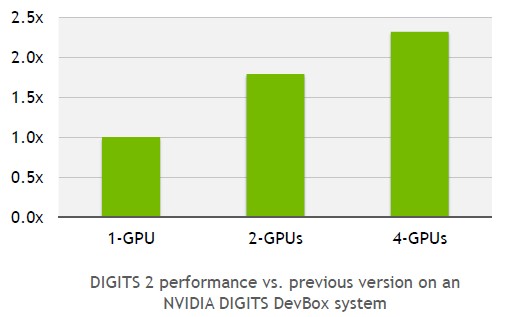
This is a kind of scale-in performance that is enabled through better training algorithms and larger deep neural network datasets. But Nvidia has a scale-out play it is announcing as well. Nvidia is updating its Deep Learning GPU Training System, or DIGITS for short, with automatic scaling across multiple GPUs within a single node.
The DIGITS software allows data scientists to use a graphical user interface to design their deep neural networks and to monitor how the training of those networks is going in real time. Some models can take anywhere from days to weeks to run, so keeping an eye on it to tweak the algorithm or being able to run training sessions on multiple networks at the same time in parallel on multi-GPU machines can help researchers end up with better models in less time.
While the largest server nodes out there have as many as eight GPUs lashed to a two-socket Xeon server, the DIGITS automatic scaling is limited to four GPUs. (It is not clear how many deep learning researchers are getting their hands on systems with eight GPU accelerators, but they are probably the lucky few.)
Up until now, if researchers wanted to scale their neural network training across multiple GPUs, they had to do this by hand, says Buck. But with the DIGITS 2, which is available now, this scaling is automatic, much like a Windows or Linux operating system can automatically see multiple GPUs for graphics and use them to drive a large high resolution screen. (This is not a perfect analogy, we realize.)
The speedup from the multi-GPU support is significant, as you can see from the chart above, at a little less than 2X for two GPUs and a little more than 2X for four GPUs. Depending on how much customers want that extra bit of performance, it seems likely that dual-GPU model training will predominate. But maybe not. The Flickr photo site of Yahoo deployed DIGITS 2 to accelerate its automatic image tagging algorithms for its vast photo library, and says that with a single Titan X card it took sixteen days to train the neural network, but with four Titan X cards that time dropped down to five days.
We also assume that the performance improvements that Nvidia has announced this week for deep learning are additive, meaning that the combination of larger, lower-resolution models, single-GPU training speed improvements, and multi-GPU scale-out can result in larger neural networks to be trained in a much shorter time. By our math, it looks like the speedup using a mix of these technologies could be on the order of 4X to 5X, depending on the number of Titan X GPUs deployed in the system and the nature of the deep learning algorithms.
What is interesting to contemplate is how much performance improvement the future “Pascal” GPUs from Nvidia, coupled with the NVLink interconnect, will deliver on deep learning training algorithms. Back in March, Nvidia co-founder and CEO Jen Jen-Hsun Huang went through some “CEO math” as he called it to show that the combination of mixed precision (FP16) floating point plus 3D high bandwidth memory on the Pascal GPU card (with up to 1 TB/sec of memory bandwidth) plus NVLink interconnects between the GPUs would allow for Pascal GPUs to offer at least a 10X improvement in performance over the Maxwell GPUs used in the Titan X. (There is no Maxwell GPU available in the Tesla compute coprocessors, and as far as we know there will not be one, although Nvidia has never confirmed this.)
The Pascal GPUs are expected to come to market in 2016 along with CUDA 8 and the NVLink interconnect, which will tightly couple multiple GPUs directly together so they can share data seamlessly. The NVLink ports will run at 20 GB/sec, compared to a top speed of 16 GB/sec for a PCI-Express 3.0 x16 slot, and it will be possible to has four NVLink ports hook together two Pascal GPUs for a maximum of 80 GB/sec between them. There will be enough NVLink ports to have 40 GB/sec between three GPUs in a single node (two ports per GPU) and with four GPUs customers will be able to use a mix of NVLink ports to cross-couple the devices together with a mix of 40 GB/sec and 20 GB/sec links. Depending on how tightly the memories are coupled, such a cluster of GPUs could, in effect, look like one single GPU to any simulation or deep learning training framework, further simplifying the programming model and, we presume, providing a significant performance boost, too.

After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …
Nvidia Speeds Up Large Language Modeling
Natural language processing has been an easy fit for these relatively early days of artificial intelligence. Teaching computers how humans speak and write has broad applications, from customer service chatbots and voice-controlled assistants (think Amazon’s Alexa or Apple’s Siri) to the – at times frustrating – autocorrect capability on smartphones …

Dell Tackles AI Infrastructure With Disaggregated Servers And Storage
It is funny how companies can find money – lots of money – when they think IT infrastructure spending can save them money, make them money, or do both at the same time. This is the hope with AI, and everyone is trying to benefit from it in those ways. …
Be the first to comment