
It seems pretty clear that storage systems will hit exascale a few years before compute infrastructure does, and there are two reasons for that. First, the amount of storage that organizations require is growing at a much faster pace than the compute that chews on that data, and not just because media is getting richer but because we are saving more types of data in the hopes of extracting insight from it. Second, applications are much harder to parallelize and scale than is a sophisticated parallel storage system. Storage will therefore not only hit exascale first because we need it to, but because it can.
Tier two archive storage will hit exascale before tier one primary storage does, and this makes sense because by its nature an archive has to be many times larger than production data. This second tier of storage, which is generally a hodge podge of different hardware and software at most companies, has to be a lot cheaper than primary storage, and if it is based on disks it has to offer bang for the bit that can compete with massive tape libraries that cost pennies per gigabyte to store data. Making any storage technology hit those budget parameters is a challenge, and making matters worse, the heat is on vendors to provide a mix of data addressing types – block, file, and object – as well as functions to allow the storage to be used in tier one or tier two.
Hyperscalers tend to build their own object storage, as the world’s largest search engine has done with its Google Storage or Facebook has done with its Haystack object storage and its cold storage backup. Yahoo originally created its own object storage, called Mobstor, but is now deploying a system that has hundreds of petabytes of capacity that is based on a gussied up version of the Ceph object store that is now controlled by Red Hat. While the elite hyperscalers can hire the software engineers and storage experts to create storage systems precisely tuned to their applications and data, and a few of the largest HPC centers have been able to foster the development of parallel file systems like Lustre and GPFS, any other organization has to rely on a commercial-grade storage array for their scale-out needs.
Erwan Menard, chief operating officer at object storage upstart Scality tells The Next Platform that the company is breaking out of its roots in the telecommunications and cable industries and is branching out to more mainstream customers in the enterprises. It also has not hurt the company’s prospects in the HPC arena when it bagged an archive storage deal with Los Alamos National Laboratories a year ago, a deal that could see up to 500 PB of capacity running on X86 servers being used as an archive for production supercomputer clusters, replacing tape libraries.
Scality was founded in 2009 in Paris, under the name Bizanga Store, and its founders – Jérôme Lecat, Serge Dugas, Giorgio Regni, Daniel Binsfeld, and Brad King – created a scale-out object storage system aimed specifically at satisfying the burgeoning storage needs of email hosting and other kinds of service providers. The company is still relatively small, but has seen its business grow by 500 percent in 2013 and 250 percent in 2014, and Menard tells The Next Platform that it had “double digit revenues last year” and now has 75 customers – all of whom operate at the petabyte scale and higher. Scality changed its name back in 2010 when it raised some funding, and moved its offices to San Francisco. The company has raised $35 million to date, and the premise of its business is to sell its RING fault tolerant clustered object storage on a wide variety of hardware picked out by its customers.
By moving to commodity hardware, Menard explains, Scality can deliver an object storage system with native and distributed file system interfaces (meaning that the file interfaces are not done by a gateway, but rather by all of the nodes in the RING and therefore do not present an I/O bottleneck to applications) that is somewhere between a 30 percent and a 50 percent lower price than an all-disk, scale-out NAS appliance setup from one of the big tier one storage vendors. Scality does not disclose its pricing, but says that licensing is based on the usable capacity, which is either tied to a specific box on a subscription or is perpetual and you can change the hardware underneath the license. Usable capacity means that Scality does not count replicas, which are done for data durability and protection, in the license fees. Generally speaking, the Scality software license represents about a third of the overall object storage cluster price built on top of X86 commodity servers with loads of disks and a sprinkle of flash. And obviously there is volume pricing on the software.
“The enterprise has been the growing force within the mix, because we have seen a boom from the media and entertainment area, but the cloud is still growing exponentially and is still strong and that is because they were aware of putting software on industry standard hardware way before enterprises. When it comes to hyperscale, several of them have developed their own object stores, and our value proposition is to bring to cloud and enterprises hyperscale-style object storage. When it comes to HPC, I think this is just the beginning of something promising.”
In general, given the nature of the workloads, customers use flash to accelerate the RING metadata, but Menard says that there is no reason why customers cannot use RING to create an all-flash object store and that a number of customers have done just that. In general, customers tend to store their hottest data on all-flash or hybrid flash-disk arrays, the tier one devices, and then once the data has cooled a bit, they shuffle it off to tier two storage that is much less expensive. Scality is aimed mostly at this latter bit, the tier two chunk, which represents about 80 percent of the data in most enterprises. (Another upstart that just uncloaked called Cohesity, founded by an ex-Googler and one of the founders of hyperconverged storage pioneer Nutanix, is similarly focusing on this tier two and archive problem.) This is why the RING software scales to hundreds of petabytes of capacity and can hold trillions of objects. “But the latency-sensitive and database workloads in tier one are not yet our targets,” says Menard.
The typical box that customers use to build RING clusters is a 4U storage server from the likes of Supermicro, SGI, Dell, Hewlett-Packard, or one of a number of original design manufacturers that crams 60 or 72 disk drives into a chassis – the kind of boxes that have been created for Hadoop clusters or high-density storage servers. (The difference is a bit moot.) Using 8 TB disks, a rack of such machines kisses 6 PB per rack. Scality’s largest customer has 60 billion objects in a RING cluster, and the largest customers tend to have dozens of petabytes of capacity per RING. A number of them have multiple RINGs, in fact, and the scalability limit is less about networks and nodes and more about the organization’s line of business structure.
The RING architecture has the access layer and the storage layers running on separate nodes, and both can scale independently to thousands of nodes. This is one way the system can scale to hundreds of petabytes and still maintain performance. The object storage software requires Linux and runs on X86 iron, and that is about it and it has a REST interface that is compatible with CDMI, OpenStack Swift, OpenStack Cinder, and Amazon S3 interfaces. File interfaces supported include FUSE, the POSIX-compliant Linux file system, NFS v3, and CIFS/SMB v2 and v3. Depending on the hardware configuration, the RING can deliver up to 1 GB/sec on very large objects and up to 700 MB/sec on very large file reads on the file system interfaces on each Scality Connector access node in the cluster. Menard says that the scalability is nearly linear on accesses across multiple connectors.
The combination of scalable throughput and capacity is why Scality won a bake-off with Caringo at Los Alamos National Laboratory last summer, but the main reason might have been Scality’s willingness to tweak its code to give it features and functions that the supercomputing center needed. For every 1 PB of scratch storage that is running adjacent to parallel supercomputers running either Lustre or GPFS, there is another 10 PB of archival storage for storing datasets and intermediate results from checkpointing as an application runs over the course of months for very large simulations and models. It mounts up, and that is why tape libraries have traditionally been used to keep costs low. But as object storage scales up and the costs come down, HPC centers – and indeed anyone in the media or entertainment business that has similar archiving issues – can contemplate moving to disk-based object storage backed by erasure coding instead of tape.
The addition of erasure coding, which comes out of the telecommunications industry and which has been picked up by hyperscalers, to the RING software back in Version 4.0 back in 2012 was probably a watershed event for Scality.
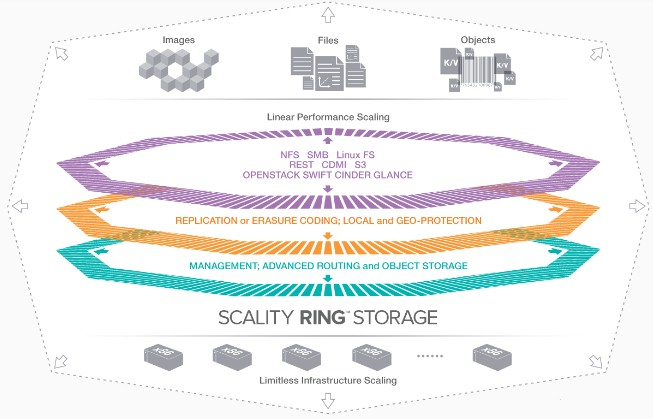
Scality uses an erasure coding method called 16/4, and that means it shards objects into 20 chunks and can tolerate the failure of four of those chunks and still guarantee the data is durable for six nines (99.9999 percent) of the time. The remote replication feature of the RING software allows data to be replicated across datacenters and into separate clusters, and that adds another seven 9s of durability protection.
About 18 months ago, nearly all of Scality’s sales were to customers in the cloud, telco, and cable networking segments. But business is picking up in the media and entertainment industry and among HPC shops such that those original roots that Scality hails from represent only 50 percent of the installed base.
“The enterprise has been the growing force within the mix, because we have seen a boom from the media and entertainment area, but the cloud is still growing exponentially and is still strong and that is because they were aware of putting software on industry standard hardware way before enterprises. When it comes to hyperscale, several of them have developed their own object stores, and our value proposition is to bring to cloud and enterprises hyperscale-style object storage. When it comes to HPC, I think this is just the beginning of something promising and we will be leveraging our partnerships with HP and Seagate to attack this scratch and home storage situation for supercomputers.”
Most recently, Scality was touting some of its media and entertainment wins. Phoenix, a service provider in the United Kingdom, has started an active archive service based on the RING that is backing up data for 300,000 employees at various companies already that has over 1 PB of data and will quickly scale to tens of petabytes, according to Menard. Dailymotion, which has a video serving platform that competes with YouTube, chose the RING to host its 40 million video titles on HP ProLiant SL4540 storage servers last June using 4 TB drives and in less than a year has doubled its capacity to 17 PB. Deluxe OnDemand, an online distribution company that has over 60,000 films and television programs in its archive has a multi-petabyte installation of RING machines, which displaced NAS appliances.
This scale-out, object-based market is growing fast, and has intense competition from the likes of DataDirect Networks’ Web Object Scaler, EMC’s Atmos, and a number of other smaller players including Scality, Caringo, CohoData, Cleversafe, Amplidata, Cloudian, Exablox, and about a handful of others. The $11.4 billion market in 2014, as reckoned by IDC, is expected to grow to $21.7 billion by 2017.


Middle Ground Emerging for Next Generation HPC Storage
In a series of articles over the last two weeks, we have taken a close look at how the storage stack might be changing for next-generation high performance computing sites—not to mention similarly sized installations for very large-scale enterprise. Specifically, these have focused on the potential advantages of object storage …

French Nuclear Agency Bolstering Supercomputing I/O Might
The French Atomic Energy agency (CEA) is one of the leading centers for nuclear weapons and energy research in Europe, and as such, is one of the top sources in Europe to watch for extreme scale computing trends. Like other national labs focused on nuclear simulation application areas, however, the …

A New Object of Supercomputing Storage Interest
Last week, in an article on the pending death of the parallel file system, a note was made about an effort out of Los Alamos National Lab (LANL) called MarFS, which will serve as the intermediary solution to allow very large centers to take advantage of cloud-style object storage using …
Be the first to comment