

About a year ago, search engine giant Google put out a whitepaper about how it was using machine learning to increase the efficiency of its datacenters, and now, executives at the company tell The Next Platform that the system is being put into production. What Google did not say a year ago, and which makes the machine learning effort all the more important, is that the company’s efforts to boost the power usage effectiveness, or PUE, had hit a wall and that the side work of an intrepid engineer got the efficiency improvements moving in the right direction again.
And as Joe Kava, vice president of datacenter operations, explained on a recent trip to the Googleplex, as has happened so many times in the past with ideas that Google’s engineers have come up with, other datacenter operators are mimicking what Google has done based on the publication of a research paper describing the effort.
All of the major hyperscalers and cloud builders grew up with the idea that you measure everything and use that information as a means to enhance outcomes, be that more efficiency in operations or better sell-through on products. This is just the mentality. And while Google measures everything obsessively, particularly the efficiency of its datacenters, that doesn’t mean it is easy to make use of that data to try to run the datacenters better. There are physical limits to increasing the PUE of a datacenter, of course, but Google had become concerned that the efficiency gains had hit a plateau, as you can see in this chart:
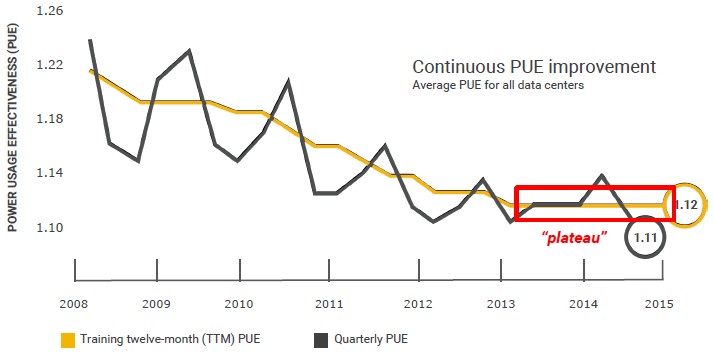
“Even though 1.12 is awesome already, it had been flat for several quarters,” Kava said. “So I put a challenge to the team and asked them what they could do about it. This gets back to that mentality that you continue to measure, implement, improve, and re-measure.”
Jim Gao, one of the engineers on the datacenter team came up with the idea to use machine learning to sift through the billions of points of data Google is gathering about the datacenters – cooling tower fan speeds, pump speeds, outside weather conditions, and so forth – which is very hard for any person to analyze. Here is a simplified model that has only four inputs:
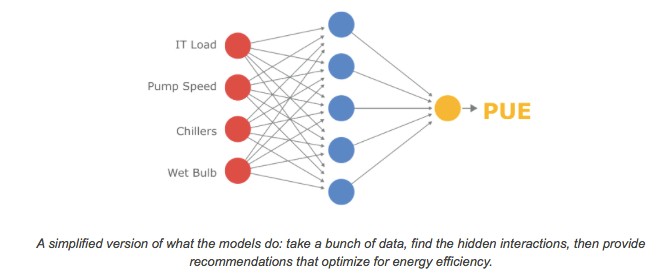
“We call him Boy Genius for a reason, and he went off and taught himself how to program and create machine learning algorithms, and trained the algorithm with billions of data points,” Kava recalled. “We found that there are roughly nineteen variables that are really important in the operating of the datacenter that would help to minimize that PUE. I don’t know about you, but I can’t visualize a nineteen variable matrix. That is why it is so hard to look at the data and know that it is clear that you have to do this or that to get a better PUE. But it is actually pretty trivial for a machine to run those millions of combinations and permutations.”
Here is a list of the nineteen important input variables, based on Google’s experience running its datacenters:

Gao built the machine learning model based on these variables, and Google went back and looked at the actual measured PUE for its datacenters and ran the model to see what it would have predicted. After being refined a bit, the model is now greater than 99.6 percent accurate in predicting the actual PUE of a datacenter based on those nineteen variables. (One of the lessons learned here is that for certain correlations only a certain subset of telemetry may be important, and figuring that out is something that is so tough that perhaps only a machine learning algorithm can do the trick. This is an important lesson for all of our job prospects in the future.)
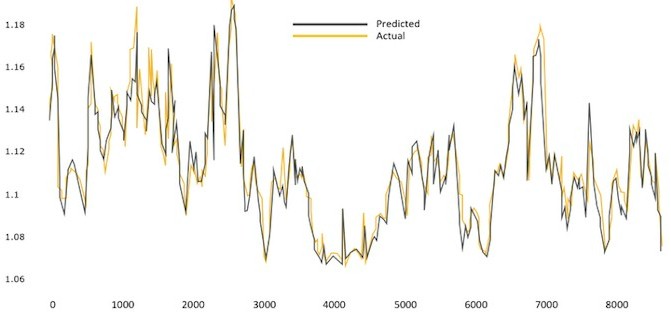
The machine learning tool created by Gao has moved from science project at Google to a forward-looking tool that is helping datacenter managers at the search giant run their facilities more efficiently.
“So now we have an actual tool we trust, it is highly accurate, and we give it to the datacenter operators as a way to get the best way to get the most efficiency on that specific day given the outside weather conditions and how much IT load is in the datacenter,” Kava said. “In the five sites that we have deployed this over the last nine months that we have been rolling it out, we have been seeing on average a 15 percent improvement in PUE, and as much as 25 percent in one site. When you are already at 1.12 PUE that may not sound like that big of a deal, but at Google scale this is literally millions and millions of kilowatt-hours a year. So it is a big deal, and it was simply taking the data we already have available – most datacenter operators already have this data because they have power monitoring systems and building systems that are already gathering the data. It is just that no one is doing anything with it.”
Kava adds that since Google published Gao’s research paper last May, which you can read here, several datacenter operators have reached out to Google and said they are in the process of developing their own machine learning models to do the same thing. Google is not about to open source its algorithms for this datacenter control system that is enhanced by machine learning, or give out the feeds and speeds of the system that it used to create those algorithms, because, as Kava put it, “we don’t release our know-how all that often, because it is a competitive advantage for Google.”
But as has happened so many times in the past, when Google hits a limit and tells people about that limit and how it broke through it, then the rest of the IT industry knows the barrier can be broken and reads the Google research very carefully and emulates what the search giant has done. This is how the world got the Hadoop analytics stack, the Mesos cluster management system, and custom servers, just to name a few examples.


OpenPower Puts Open Source Software Guru In Charge
If you want to build a successful hardware ecosystem around a chip architecture that has recently been open sourced, as the Power chip instruction set was last August, then it probably makes a lot of sense to put someone at the helm of the project who has deep and broad …

Hyperscalers Bringing Nvidia’s Grace-Blackwell Superchip To Their Clouds
At his company’s GTC 2024 Technical Conference this week, Nvidia co-founder and chief executive officer Jensen Huang, unveiled the chip maker’s massive Blackwell GPUs and accompanying NVLink networking systems, promising a future where hyperscale cloud providers, HPC centers, and other organizations of size and means can meet the rapidly increasing …

Google Chips Away at Problems at “Mega-Batch” Scale
As Google’s batch sizes for AI training continue to skyrocket, with some batch sizes ranging from over 100k to one million, the company’s research arm is looking at ways to improve everything from efficiency, scalability, and even privacy for those whose data is used in large-scale training runs. This week …
Be the first to comment