

The fact that Google calls its massive-scale resource management framework “Borg” is, in itself, rather a brilliant thing. And now, with the unexpected addition of the follow-on mega-scale cluster manager Google has been developing, called Omega, into that fold, the hive mind of operations across Google datacenters is set to be more flexible, smarter, and gathering strength in numbers.
There are a few papers that cover the gritty details, but in essence (and in true Borg fashion) worker nodes, compelled by the bidding of master nodes across an unknown range of Google datacenters, swiftly gather and execute orders about what tasks to carry out across an allocated set of resources, the process of which is governed by a complex set of policies. These “rules” by which the master nodes dispatch jobs to the workers assign priority levels to various tasks and accordingly, there is a grand hierarchy that operates—and ensures you can open your Gmail, among other things.
This is a gross oversimplification of what Borg and Omega do, but for the sake of those who just stumbled this way, with tens of thousands of servers at each Google site, which must not only communicate with one another—but also with others in remote locations, the orchestration of those millions of compute cores, untold petabytes of data, and wide range of both internal applications and production workloads that underpin Google services, this is a huge task. One that took some of the best minds in computer science and systems software well over a decade to hash out and refine—even with baseline tools that had been developed for supercomputers to do similar things (Condor, for instance) as a starting line.
In a chat with The Next Platform, one of the kings of Google’s distributed computing systems and software, John Wilkes, said that high performance computing (supercomputing) is interesting to watch, but the design decisions that drive big scalability there are often not directly carried over to Google. Nonetheless, he says that the tools and ideas the supercomputing communities have developed over time, especially in the area of large-scale resource management, have a solid basis, and one that they considered carefully during the continued efforts to refine the Borg resource management framework and of course, for the extension of that project, called Omega.
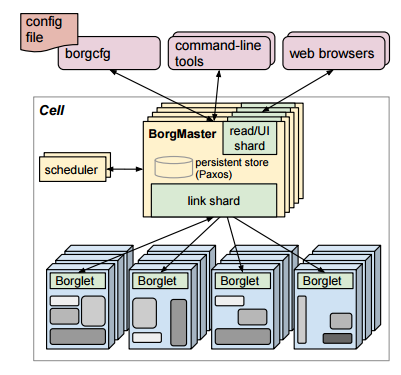
Wilkes is no stranger to conducting a symphony of compute and data movement across large distributed systems. He holds forty patents across a range of areas that touch both storage and resource management, with some work on interconnect fabrics, all of which were his focus areas at Hewlett-Packard Labs, where he spent 26 years before moving to Google.
While the massive resource management framework used across all of Google’s sites for critical applications was developed and put into practice a bit before his time at the search engine giant. Wilkes has been instrumental in honing it for further scale, functionality, and ease for the development and operations teams who rely on it.
A couple of years ago, further work on the resource manager in the form of a new set of tools, which was said to be the replacement for Borg, came into view. This new package, called Omega, was reported to be a replacement for the decade old Borg framework, but Wilkes said that Omega will folded into the existing Borg collective, which fills a few critical gaps for Google while allowing the teams to continue refining a system that has worked well at scale for so many years.
When news about Omega emerged, it appeared that Borg might have been hitting a wall, which prompted some to speculate that the scalability wall for robust Google-developed platforms had been hit, but Wilkes said Omega was more of a modernization—an addition onto an already stable platform, even if at the time the development team for Omega, including Wilkes, expected it to be standalone framework to replace Borg.
In what has become available about Omega, there was no doubt that Borg had some serious limitations as Google’s scale continued to mount. As the team said in a paper published about the Omega architecture, the monolithic scheduler had hit the end of its lifetime. “Increasing scale and the need for rapid response to changing requirements are hard to meet with current monolithic cluster scheduler architectures. This restricts the rate at which new features can be deployed, decreases efficiency and utilization, and will eventually limit cluster growth.” In other words, as Wilkes described, Borg had all of these problems, and even more as it evolved into a very complicated nest, making it difficult to alter, thus prompting the Omega “rewrite” of the scheduler.
Wilkes said that these issues led the team to see how this bottleneck was on the horizon to limit scalability in the future, but that magic tipping point had not happened quite yet. “We have always managed to scale Borg well,” Wilkes told The Next Platform. “We haven’t hit the scalability wall yet, so that is not the reason why we continued development with Omega. It was more about giving our developers more flexibility and also more manageability.” The flexibility factor, matched with the ever-prominent issue of reliability, is what drove the decision, says Wilkes. “Adding flexibility was the key factor that drove us to create Omega in the first place,” Wilkes says.
On the flexibility front, the Borg monolithic scheduler model made it difficult to add and change hard-set policies, which limited developer productivity. With another approach, a two-level scheduler, there is better flexibility and parallelism, but some tradeoffs in terms of making the engine smart enough to handle what the team describes as “picky” jobs. The Omega cluster manager and schedule uses a shared state model, which in very basic terms offers the best of both worlds.
“The most important thing for us to worry about is reliability. After that, in order, it’s efficiency, then flexibility. Our goal is to provide services internally and, of course, externally, so this is what drives our design parameters. Yes, we care about efficiency, it’s a big deal when it comes to so many machines. hen we’re talking about the things that consume between 70 percent to 80 percent of our cycles, reliability is key but small changes in efficiency can have really big absolute effects.”
Even with the improvements in flexibility and reliability, however, Wilkes was open about the fact that there are still challenges ahead with some bottlenecks that prove to be a source of continued development. For instance, as Wilkes highlights, “For the master controller nodes, the bottlenecks are things like whether we have enough memory, can we process jobs fast enough, can we respond to requests from other systems–each of these things have been issues in the past.”
While Wilkes and team have worked diligently with both Borg and Omega to overcome this set of “simple” but ever-pressing problems (which go far beyond scheduling and start/restart/kill for jobs) the “symphony” of so many virtual machines in so many locations, supporting such a wide range of services and production jobs, means that the policies become rigid and flexibility becomes an issue. While Omega was meant to help overcome this, leaving the Borg innovations over the decades on the ground in favor of a new paradigm would not be useful.
Massive Scale for Many Small Problems
What’s interesting here, and what brings us back to the opening point that at massive scale, there are some similar and dissimilar challenges for the hyperscale and supercomputing worlds. While the reliability and flexibility factors that are critical for Google to support and keep developing new services are not as significant at top-tier supercomputing sites, the bottlenecks Wilkes cites are consistent with what many big high performance computing (HPC) centers face, particularly on the memory and processing fronts. But ultimately, while HPC’s big problem is often around data movement, both within the node and between them, Google faces the huge challenge of negotiating big data movement, a ton of compute power, and distributed sites that have distinct allocations with multiple prioritization layers that can become tangled quickly, especially when a high-priority job kicks a slightly less priority one off the assigned resources and sends an avalanche of delay throughout the system.
For those who follow high-end computing, there are just a few centers that become the object of fascination, some because of their computational horsepower, and others because of sheer massive scale.
The national labs and research sites turn out their share of Top 500 supercomputers every few years, with some truly incredible machines coming in 2018, but at the other end of the big compute spectrum are the warehouse scale datacenters. At this peak are the big cloud providers like Amazon Web Services, the social giants like Facebook and LinkedIn, and of course, at the top of that web scale datacenter list, there is mighty Google.
As one might imagine, the requirements on both sides of this computing fence are distinctly different. The national labs are devoted to grand scale scientific challenges—often to monolithic applications with millions of lines of decades-old code—that can consume an entire supercomputer’s resources for one simulation. But for the web services giants, the requirements are far different, and so too are the ways the resources are managed.
Some of the same themes persist when it comes to orchestrating applications across so many machines, but unlike supercomputing centers, which are physically located in the same datacenter and might handle a handful of different workloads at a time (or one giant simulation), Google has to balance the resource demands of a wide range of user-facing applications across multiple sites while maintaining the kind of “always available” services (Gmail, Google Docs, etc.) that so many count on.
“The HPC community is trying to solve problems that can’t be solved in any other environment,” says Wilkes. “They have to push the envelope for large problems that we just don’t have to on specialized machines that have been optimized around those very problems. But that’s not to say we don’t follow what they do. We do interact and keep an eye out, just as they do on us to some degree, but the requirements are fundamentally different, so the design choices are fed by different things.”
The mind-bending papers on resource scheduling at massive scale can be found here for Borg and here for Omega.


Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …
Neural Networks Are Only As Good As The Data They Are Fed
Like other kinds of computing, if you put garbage data into a machine learning training run and then pour new data through it, what comes out as the answer is puréed garbage. There is a lot of truth in the at-times breathless talk of how artificial intelligence and machine learning …
SambaNova Pits LLM Collective Against Monolithic AI Models
There is more than one way to get to a large language model with over 1 trillion parameters that can do lots of different things and enterprises can use to create AI training and inference infrastructure to extend and enrich their thousands of applications. One is to take a big …
Be the first to comment