
Not all of the NoSQL and NewSQL databases that are created by hyperscale companies or by database experts trying to best them at the latency or scalability game are going to make it as commercial products over the long haul. But it looks like the Cassandra NoSQL database that came out of Facebook is getting some traction among other hyperscalers and large enterprises. And given the economics, the software could see even more uptake for specific uses if companies are willing to adopt new server technologies that are well suited to Cassandra.
Cassandra was created by the software engineers at the social network back in 2008 because search functions in the MySQL database that were used for the Facebook inbox were too slow. (One of its creators, Avinash Lakshman, worked on the Dynamo database at Amazon Web Services before working on Cassandra at Facebook and has just launched a startup called Hedvig, which is tackling a different set of storage problems.) Given Facebook’s scale, Cassandra was designed from the get-go to span multiple datacenters and to replicate information across clusters and datacenters. The software has also been tweaked to run as an alternative datastore underneath Hadoop and has been given its own SQL-like query language to make it more palatable to enterprise customers. The main thing that Facebook wanted in a datastore was scale and no single point of failure, so data is automatically replicated to ensure no data is lost. Ironically, Facebook no longer uses Cassandra, but other companies have picked it up and ran with it.
Like all open source projects, it is tough to find out who is using Cassandra, which is an Apache Project and therefore has its source code openly available for anyone to pull and use. And as best as Matt Pfeil, who is chief customer officer and co-founder of DataStax, the company that has commercialized Cassandra, there are thousands of companies that have put Cassandra into production.
Apple, which is super-secretive about its infrastructure, has admitted that it has a whopping 75,000 nodes running Cassandra, but it has not said what it is using it for. In a presentation last fall, Apple said that it had tens of petabytes of data stored in Cassandra, with its largest cluster having more than 1,000 nodes, and that collectively those Cassandra machines were fielding up millions of operations per second.
If Apple is like Netflix, then Cassandra is underpinning all of the user information for its various online services. At Netflix, everything you do in terms of picking movies and TV shows and playing them – and keeping track of where you are in those videos – is done with Cassandra as the back-end. Apple and Netflix have been rolling their own Cassandra, and they have the technical talent to do so.
Sometimes, a hyperscaler will flip from open source to commercial support, as Netflix did back in May last year, when it moved more than 80 clusters and more than 2,500 server nodes running the open source Cassandra to the commercial-grade DataStax Enterprise. Most large enterprises don’t want to roll their own databases, any more than they want to create their own Linux distribution. They do, however, like to have access to the source code so they can tune it or suggest tweaks to it among the community’s developers.
At DataStax, the target market for commercialized Cassandra, which is called DataStax Enterprise or DSE for short, is the Global 2000, explains Pfeil. Cable provider Comcast uses DSE as a back-end for its X1 virtual cable boxes, transforming its cable shows into something that has a look and feel that is more like Netflix. Rackspace hosting, where Pfeil and DataStax co-founder Jonathan Ellis hail from, use Cassandra to process server monitoring telemetry in real time, and it has a twelve-node cluster that can handle 990,000 writes per second. This, even though Rackspace is a big seller of the MongoDB NoSQL database. You need to pick the right tool for the job, and both MongoDB and Cassandra – and indeed a number of other databases and datastores – have their places in the modern datacenter. Cassandra is structured to append data rather than to update it, so it makes it very useful for data that has many people accessing and changing it; moreover, it is designed to scale reasonably linearly.
Pfeil tells The Next Platform that DataStax is targeting over 37 different vertical markets with its commercial distribution of Cassandra, but that its key customers are in the financial services and media and entertainment markets where applications have to juggle information for millions of users concurrently. (Reuters, USA Today, and the Wall Street Journal all use Cassandra as a back-end datastore for their content.) Recommendation engines for serving up content as well as for suggesting products to sell among retailers is another popular use case for Cassandra. (eBay and Target are users.) DataStax does not have a customer breakdown by industry for its commercial users, but Pfeil said that he did have a proxy, which is the industry sectors of startups who are working with Cassandra with the assistance of DataStax:
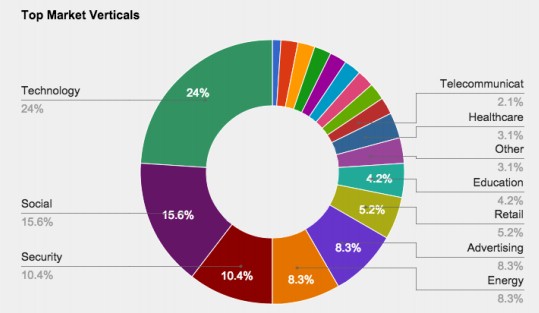
DataStax now has over 500 paying customers and 420 employees, and has raised $189.7 million in venture capital to fund its growth and its expansion into the enterprise. For commercial users who pay DataStax for tech support, Cassandra is finding its way into new mobile applications or telemetry applications collectively called the Internet of Things; some SaaS applications that are made to run at scale are also choosing Cassandra as one of their databases. Another emerging niche, says Pfeil, is as a replacement for Oracle databases and even Oracle RAC clusters.
“The number one motivation for choosing Cassandra is not related to cost,” Pfeil tells us. “It is usually driven by the fact that they want to do something with their application that can’t be supported by the relational database.” Just, as it turns out, happened with Facebook all those years ago. With commodity storage prices falling so fast in the past couple of years, companies can now contemplate keeping more data and doing more things with it than they would have in the past, and so they are experimenting as well as building new applications that are driven by all this data to help them better serve customers and therefore drive revenues and profits.
Pfeil says that the market is splitting, with Hadoop taking a big bite out of traditional data warehousing and analytics running on relational databases and tools like Cassandra, MongoDB, and Couchbase taking a bit out of transaction processing running on relational databases.
The typical DSE customer, says Pfeil, has clusters that use two-socket Xeon servers with maybe 12 to 24 cores, 128 GB of main memory, and somewhere in the low terabytes of disk capacity. Companies are increasingly using a mix of spinning disk and flash for their Cassandra databases, which can move the hot data to flash and the colder data to disk to improve performance.
Because Cassandra is not particularly compute intensive (even though it is written in Java), DataStax wants to push this the economics as hard as it can and has just finished up some benchmark tests that pit DSE running on a cluster of Hewlett-Packard ProLiant DL380 servers against an Moonshot hyperscale system with m710 nodes. The DL380s are rack machines based on Xeon E5 v3 processors, while the m710s are microservers based on Xeon E3 v3 processors.

Pfeil says that on a workload that was a mix of four reads for every write, 45 single-socket ProLiant m710 cartridges were able to do the same work as 77 two-socket ProLiant DL380 rack servers. The Moonshot chassis took up 4.3U of rack space, while the ProLiant DL380s took up a total of 154U across multiple racks. Over a three-year term, the Moonshot setup had a 66 percent lower total cost of ownership and consumed 90 percent less power. Savings also came through 98 percent less cabling and 75 percent less floor space in the datacenter. Mind you, we realize that there are denser machines that a standard 2U rack server with two processor sockets. But it does illustrate the benefit of microservers for massively distributed workloads that can scale out across boxes as well as within boxes – and Cassandra is one of those such workloads.

AMD Gets Inside Facebook’s Latest – And Most Powerful – Microserver
Sometimes, you do put new wine in old bottles. This is what it looks like Meta – well, really its Facebook social network group – is doing as it adds a microserver node based on a custom AMD “Milan” Epyc 7003 processor to its datacenter infrastructure. Facebook has been one …

Presto Is The Third Time Charm For Federated Databases
Users of relational database management systems are accustomed to sub-second response for relatively simple online transaction processing, and have been able to enjoy those zippy responses for decades. The big caveat there is relatively simple transactions – looking up data or processing an order – and against fairly modest databases …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …
Be the first to comment