

Over the last eighteen months Hadoop distribution vendor, Hortonworks, has watched a stampede of users rush to the cloud, prompting the company to look for better ways to extend usability for first-time entrants to Hadoop territory and to accommodate the rush of test and dev workloads that prefer quick cloud deployments.
While there are still a large number of on-premises deployments, particularly for established Hadoop users, Hortonworks’ VP of Product Management, Tim Hall, told The Next Platform that many of the customers running proof of concept projects prefer to circumvent the on-site cluster and spin up nodes quickly on Amazon, Google, and Azure hardware. Accordingly, Hortonworks has rolled out some new features based on time-tested tools like Yarn and Ambari and with added hooks from this week’s acquisition of SequenceIQ to manage rapid deployments.
We will dig into the new technology in a moment, but it’s worth pointing out a few things we were able to glean about Hadoop adoption from our conversation with Hall, whose career includes, most recently, a long stint as product management at Oracle for their BPM suite. He likened the momentum around Hadoop adoption to what happened in the early days of the Java application server environment where the familiar elements, including dealing with a host of new business-critical applications and data processing frameworks, were all in place but with some key differences.
“The other big thing that shifted is that now we’re talking a data center of gravity versus an application center of gravity. Once you land the data, it’s there and you don’t move it all around. In the Java application server days, it was the application that had the gravity and the data moved in and out of relational databases. That’s a more significant difference than it may seem—especially now that we are adding scale to the mix.”
In those bygone days he speaks of, large scale meant forty to sixty nodes. Now, it means if a user wants to stand up a 500-node Hadoop cluster, that means, quite literally, standing up a 500-node machine and all that comes with it—from procurement to production to management. While most of their production customers running mission-critical Hadoop workloads easily have a thousand or more nodes, there are enough well under that mark that are just putting on their Hadoop boots (or are doing new test and dev projects off the company cluster) to warrant some major internal engineering and acquisition efforts.
All of these new pushes boil down to one concept—automation. And just as with so much automation these days, that means packaging up everything one needs from a cluster and dropping it where it needs to run. With that comes freedom from dragging Hadoop across too many nodes to count, but more important, being able to deploy those same images wherever one feels like it. Well, almost anywhere. Hortonworks, with its acquisition this week of SequenceIQ and the ability to containerize images of a configuration or environment (and map that to Ambari and Yarn) now includes the ability to drop a Hadoop image into Amazon Web Services, Google Compute Engine, and Microsoft Azure, with OpenStack currently in beta (relevant for the HP Helion and RedHat cloud-using folks).
Hall said that these and other new features were things that could have been developed in-house, but the tools developed organically as part of ongoing work with SequenceIQ that began last year. During that time, both companies were looking at ways to testing development projects and wanted a quick way to deploy onto cloud and other resources. At first, they looked to Docker to contain their images, but eventually found a cleaner way to deploy their images across remote resources, which the teams set to commercialize within this newest layer to the Hortonworks Data Platform (HDP), which is a 20+ tool suite that includes all the usual Hadoop suspects (HBase, Yarn, Hive, etc) and, as of today, the freshest incarnation of Spark to meet the demands of streaming and real-time data for in-memory processing.
The containerized approach to Hadoop deployments across clouds or on-premises hardware from SequenceIQ is described in detail here, but in essence, it leverages the Docker-like Cloudbreak technology that SequenceIQ developed to create an image of the deployment based on a user’s Ambari blueprint, which can then snap into existing cloud infrastructure from select providers–as well as on-prem gear.
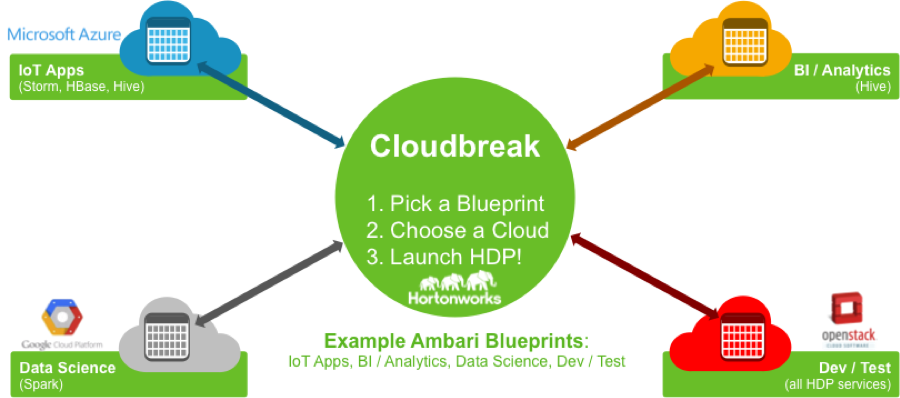
The goal of this ability to quickly deploy in the cloud is central to Hortonworks’ strategy, which appears largely cloud centered to meet the needs of growing user base. “There are two dynamics in play in this cloud transition,” says Hall. “First, the acceptance of infrastructure as a service being available to companies and those companies getting comfortable in other investments they’ve made in that context. Second, the shift in the market from the early adopter crowd to the next wave of folks who are looking at what they need to get rolling with Hadoop—if the answer is they can stand up a small cluster and see what they see, that’s a great starting point.”
Hortonworks increased the pricing across their enterprise tiers with their last update, which helped to pay for this and other key acquisitions, Hall told The Next Platform when asked about how these new features will factor into their business strategy. “We could have built this ourselves, but what we are getting aside from the technology is a group of talented engineers that we can bring on board and walk them through our process of moving a new technology into a community.”
Beyond pushing into the open source community through software contributions, Hortonworks is trying to gather enterprise support for Hadoop via projects like the Data Governance Initiative, which aims to bolster the business-critical appeal of Hadoop by showcasing large-scale users and how their requirements for data quality and management are met. Among new members announced this week are JPMorgan Chase, oil and gas giant, Schlumberger, who join existing members including Target, Merck and Aetna. A new Apache project around this has been proposed as well. Called Atlas, this will hone in how the above users have sought to handle data classification, auditing, search, and other functions in the context of broader security protocols and policies.
These are all progressive steps toward making Hadoop more accessible and usable, but more important, for demonstrating how Hadoop can be used at scale and in business-critical environments, Hall says.
“At the end of the day, Hadoop is not a solve-all proposition,” Hall says. “I think people got burnt trying to do that with previous generations of technology. Users are now saying they want to take specific use case examples and see the value firsthand. They might have an idea for a new analytical application that they just can’t handle with existing technology. And there are some datasets that don’t fit nicely in a relational database, or require ETL work their systems just can’t handle. This is where we are seeing a lot of momentum.”
Specifically, the real experimentation with new kinds of applications that are a good fit for Hadoop, and now Spark, Storm, and other ecosystem additions, are happening in an ad hoc fashion. Users are getting rough ideas and want to spin up test clusters to try those on for size before committing. The cloud is where this is happening so, as Hall says, “as someone who is heading Hortonworks product management, it’s my job to make sure this is as easy to deploy and use as possible. We want to make it as seamless as picking a blueprint, picking a cloud, and deploying—plain and simple.”


Cloud Builders Navigate A Sea Of Economic Uncertainty
In recent years, when the economy became unstable, enterprises tended to look to the cloud as a safe haven. It happed during the COVID-19 pandemic, with the dramatic shift to remote work as organizations looked to slow the spread of the highly contagious virus by sending employees home. They accelerated …

Microsoft Does The Math On Azure Datacenter Switch Failures
As supercomputer centers have long known and as hyperscalers and cloud builders eventually learned, the larger the cluster, the greater the chance that one of the many components in the system will fail at any particular time. And when you operate one of the largest public clouds on Earth, as …

AI Steady, Cloud Accelerating Gives Microsoft A Big Datacenter Boost
Wall Street has been looking for some good news, and Microsoft came through with its financial results for the third quarter of its fiscal 2025 as its cloud business – and to be specific, its non-AI cloud business – grew much more strongly than expected. In the quarter ended in …
Be the first to comment