

As supercomputer centers have long known and as hyperscalers and cloud builders eventually learned, the larger the cluster, the greater the chance that one of the many components in the system will fail at any particular time.
And when you operate one of the largest public clouds on Earth, as Microsoft does with Azure, the telemetry gathered from the Microsoft network can provide some insight into what causes failures in switches and routers and what can be done to mitigate inevitable failures so applications can heal around those failures.
In a recent paper, which you can read here and which is still out for peer review, researchers at Microsoft compiled data from over 180,000 switches running in its datacenters, which spanned 130 different geographical locations, for three months, quantifying and qualifying the sources of network crashes and then offering some advice on how to survive network failures.
Speaking very generally, datacenter networks at Microsoft seem to be pretty reliable, which is remarkable in a sense because its network is comprised of gear from a number of different vendors. We know for sure that the Azure cloud gets switch gear from Arista Networks and Nvidia (formerly Mellanox) at the very least because these companies have said so, and it no doubt has other ASIC and switch suppliers. In most cases, we believe that Azure switches are all using the Switch Abstraction Interface (SAI) layer, which Microsoft donated to the Open Compute Project way back in 2015 and which presents a kind of hypervisor for switch ASICs that sits between the silicon and a mix of operating systems. In many cases, Microsoft uses its own SONiC operating system, which is a variant of Linux tweaked for networking that it has also open sourced, but also, we presume, Arista’s EOS and Nvidia’s MLNX-OS for InfiniBand switches and Onyx for Ethernet switches. There are probably other switches and NOSes in the mix, and Microsoft conceded in the paper that it culled data from three different vendors for the switch study in the Azure datacenters.
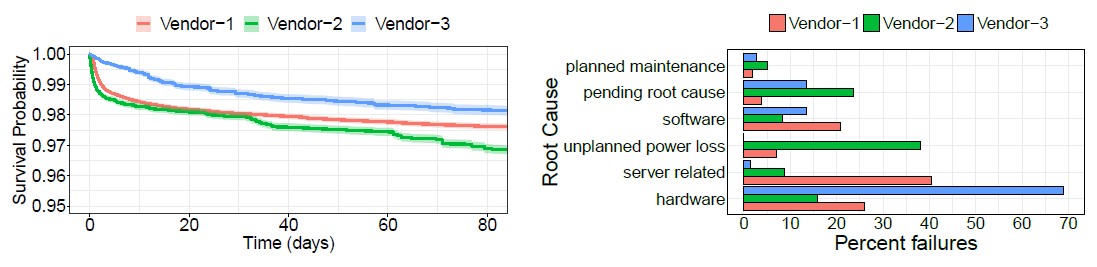
The paper does not get into these details because vendor choices are regarded as state secrets by all the hyperscalers and big cloud builders, but the authors of the Microsoft paper did say that there is “significant heterogeneity in switch survival rates with respect to their hardware and software” and brackets the reliability this way. One vendor’s switches were twice as likely to fail as another – we presume this was the best and worst case scenario – and thatswitching from proprietary NOSes on this gear to SONiC boosted the reliability of the switches.
It is a strange new world, far distant from the 1980s through the 2000s, when Microsoft is bragging about the reliability of its software. (And to be fair, Windows has generally been pretty good since Windows 7 and Windows 10 has caused us no grief at all.)
Estimating the time between crashes is a bit difficult for the switching infrastructure, as it is for compute, since switches have their firmware and operating systems patched frequently for new features, bug fixes, and security fixes – just like servers do. You have to distinguish between planned and unplanned downtime, therefore, but it is also important to not just keep track of the unplanned downtime. If one switch needs more care and feeding, even if it is planned, than another switch, that is a strike against it when operating at hyperscale. The switch failure data that Microsoft gathers is used not only to steer future purchases – it looks like Arista Networks is doing alright, given that Microsoft represented 21.5 percent of the company’s $2.32 billion in revenues in 2020 – but also to inform the architectural decisions about where to place data and applications in the Azure network.
Over the three months that the Microsoft researchers looked at switch uptime and polled all of the machines every six hours to gather their vital stats. There were 4,681 switch failures. Almost half of these failures were for only six minutes or less, and a small number of failures ate hours of time to fix and usually meant a device had died and had to be replaced. It happens. The other way of looking at this is that in the aggregate, the switches in the Azure network had a 98 percent uptime during those three months, and if Microsoft moved to SONiC on all of its machines, that would boost that to around 99 percent. And if Microsoft is not doing that, we suspect that SONiC has some scale and performance issues. In the future we may be writing about how Microsoft tossed out all other NOSes, but that is not what is happening now, and we suspect for good reasons.
The root cause analysis shows that across the three switch vendors and their various hardware and software releases, 32 percent of switch failures were caused by hardware faults and 27 percent were caused by unplanned power outages. Another 17 percent of failures were caused by bugs in the NOSes provided by switch vendors as well as the SONiC releases Microsoft puts on some of its switches.
Here is the uptime probability distribution over time in the Azure network and the distribution of root causes for switch failures:
And here is the chart that shows the benefit of using SONiC instead of the proprietary OSes:
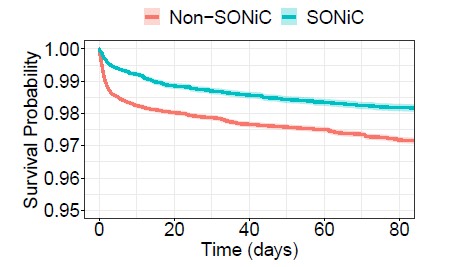
This is truly the benefit of open source software. Your stuff is publicly laundered, which can be harsh, but it is also publicly cleaned, which can be much faster than a vendor fix because a bug is public in nature and there is enlightened self-interest at work, not just a desire to hide a problem and work on it secretly.
By the way, this SONiC versus non-SONiC data comes from the aggregation layer in the Azure network within its datacenters, which all come from one vendor – hmmmm, I wonder who that could be? – with 75 percent of these aggregation switches running SONiC and 25 percent running the vendor NOS.

Broadcom Secures The Edge By Beefing Up The Network Core
A lot of compute is moving to the edge, and that means that networking and storage has to follow it. In many cases, that means bringing advanced functionality for all three – albeit in smaller capacities – out to the edge. But in other cases, it doesn’t make either technical …

Nvidia Will Be The Next IT Giant To Break $100 Billion In Sales
Here is a history question for you: How many IT suppliers who do a reasonable portion of their business in the commercial IT sector – and a lot of that in the datacenter – have ever broken through the $100 billion barrier? Three. To be precise: IBM broke $100 billion …
Ethernet Doesn’t Defy The Recession, It Denies It
If there is a recession underway – and we are not convinced that there is even a little bit – then the Ethernet switch market did not get the memo. And the Ethernet router market has stopped checking its email just in case. Don’t get us wrong. The global economy …
What do they consider a failure? Those failure rates seem extremely high, unless it’s something like one bad packet during a 6 minute period is considered a failure…
Very interesting. I’m curious why “unplanned power loss” impacts vendor-2 so much, but not vendor-1 or -3. Maybe vendor-2 should include velco straps to keep the power cables in!
Given that virtually all ransom ware events in some way start in Microsoft software I am amazed at the following statement. And to be fair, Windows has generally been pretty good since Windows 7 and Windows 10 has caused us no grief at all.)