
When the OpenPower Foundation was formed a year and a half ago, IBM had a number of reasons, driven by enlightened self-interest, for fostering a partnerships with Google, Nvidia, Mellanox Technologies, and Tyan. The first reason was to open up its processors chips to get more organizations interested in building hybrid systems based on the Power architecture. The second was a belief that it will take a hybrid approach to computing to satisfy the performance, cost, and energy efficiency needs of future high scale systems, whether they are aimed at traditional HPC, hyperscale, or enterprise workloads.
This second tenet of the OpenPower Foundation is driven by the fact that IBM and its partners believe that chip process scaling to increase the performance of systems along the Moore’s Law curve has run out of gas. As a coming out party for The Next Platform this week, we are attending the Rice University Oil and Gas Workshop in Houston, Texas, where all the bigwigs of the energy business came to hobnob and talk about high technology and how the dramatic fall in oil prices is affecting current budgets for clusters and storage. Brad McCredie, IBM Fellow and vice president Power Systems development at IBM and president of the OpenPower Foundation, gave one of the two opening keynotes at the event, during which he illustrated the limitations of Moore’s Law and how OpenPower partners are working together to build hybrid systems that can swing applications back on the Moore’s Law curve.
To make his point about how serious the OpenPower partners are about this hybrid approach to HPC, McCredie revealed a roadmap covering the five years between 2013 and 2017 that puts a stake in the ground for OpenPower – an important event for all of the OpenPower partners and their future customers.
McCredie started out his presentation with a series of charts that showed how process scaling in data processing predated the advent of the integrated circuit, and that even more importantly, as various data processing technologies came to the end of their technical and economic lives, it was always power consumption in the underlying technology that compelled a change to a different technology to get back on the Moore’s Law curve:
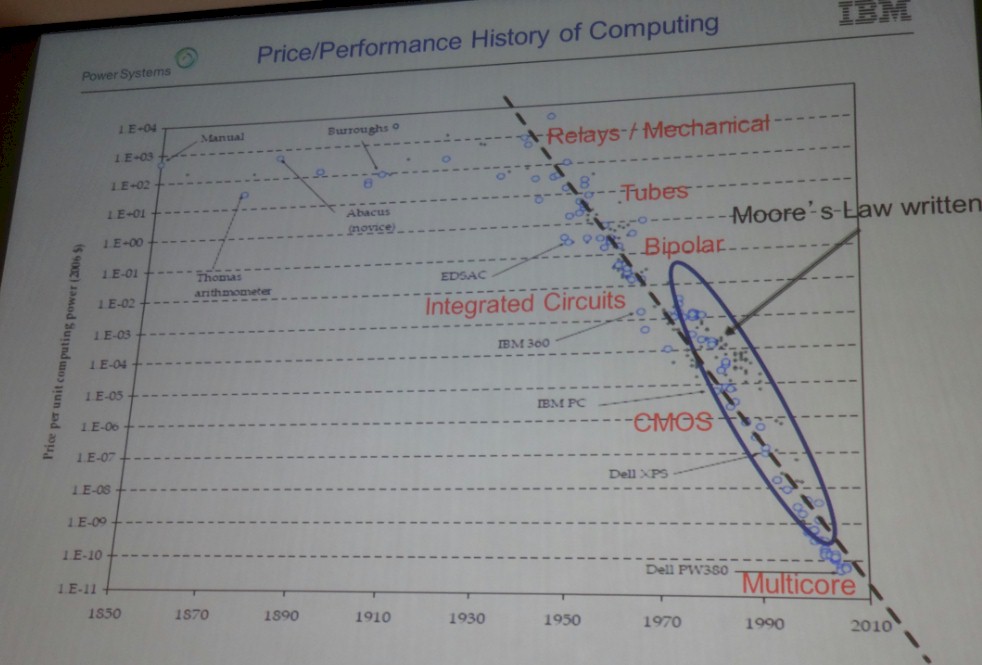
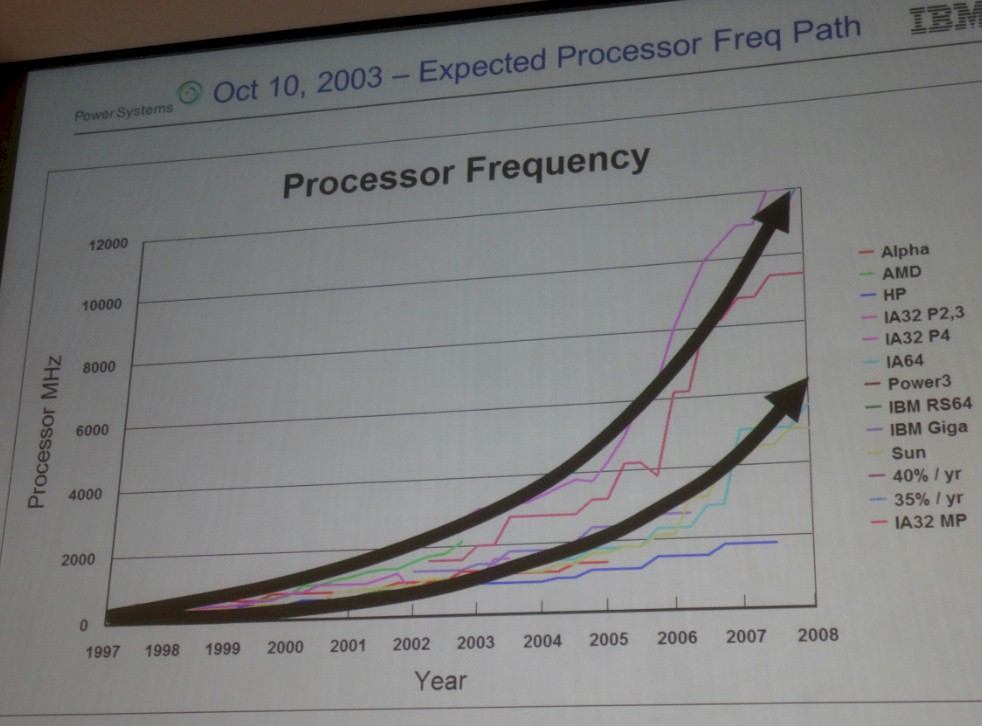
The chart above shows how the price of a unit of computing power, expressed in inflation adjusted dollars, has fallen in an exponential fashion ( linear on the log scale), as we expected for the past 65 years or so and through several different major technology shifts. A little more than a decade ago, however, the forecasts for the future of computing were quite a bit different from where we have ended up, with chip process technologies being used to add more computing elements to chips rather than speeding up cores to do more work. McCredie said he dug through some old presentations to find a chart from October 2003 that showed how clock speeds on all of the major chips in the market at the time – and there were a lot more of them back then – would just scale their performance by boosting their clock speeds up into the 6 GHz range at the low end and the 12 GHz range at the high end by 2008.
As we well know, the ever-shrinking CMOS chip making processes could not allow clock speeds to rise anywhere near those heights, which seem like folly now in retrospect. But all chip makers were confident now that they could solve the technical problems associated with ever-higher clock speeds. Only a little more than a year later, IBM took another stab at forecasting the clock speeds on processors, and it was clear than that CMOS scaling and clock speed cranks as we knew then were on the wane:
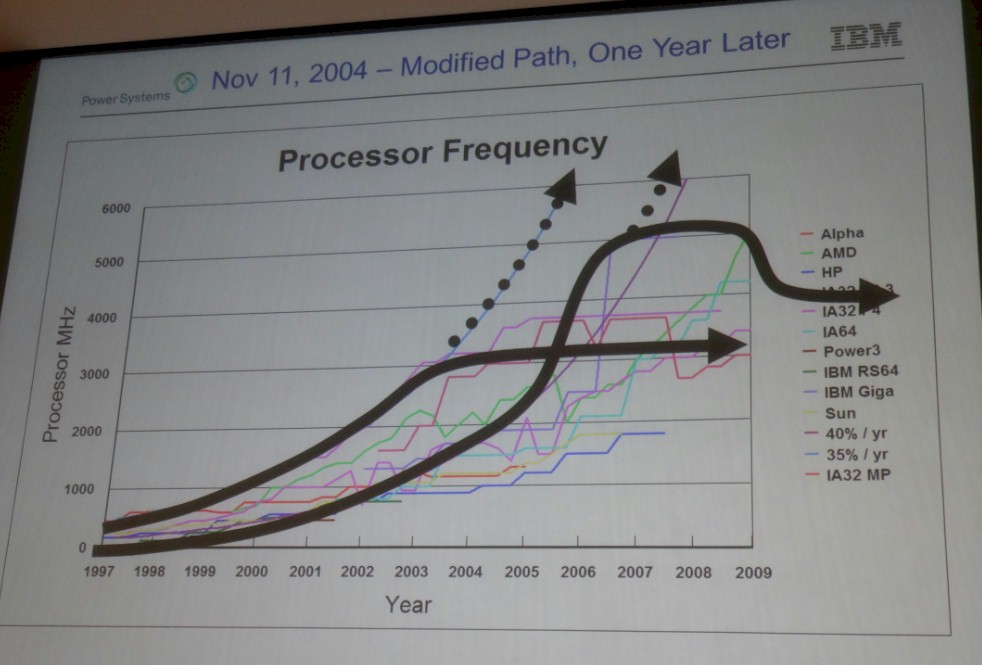
As McCredie put it, the IBM Power architecture went up to 5 GHz and settled down at around 4 GHz by 2009, and the X86 architecture in its various incarnations has settled down to around 3 GHz at around the same time. Six years later, and the clock speeds have not changed all that much, which is a terrible thing for single-threaded workloads that depend on higher clocks to boost performance.
While all processor makers have been adding cores to their chips and various levels of every-fattening caches to keep them all fed with data, the price/performance of processors have not been on the Moore’s Law curve that we expect since about 2009. But McCredie made the argument that through a collection of coupling and acceleration technologies like those being developed by the OpenPower Foundation, it would be possible to get back onto the Moore’s Law curve:
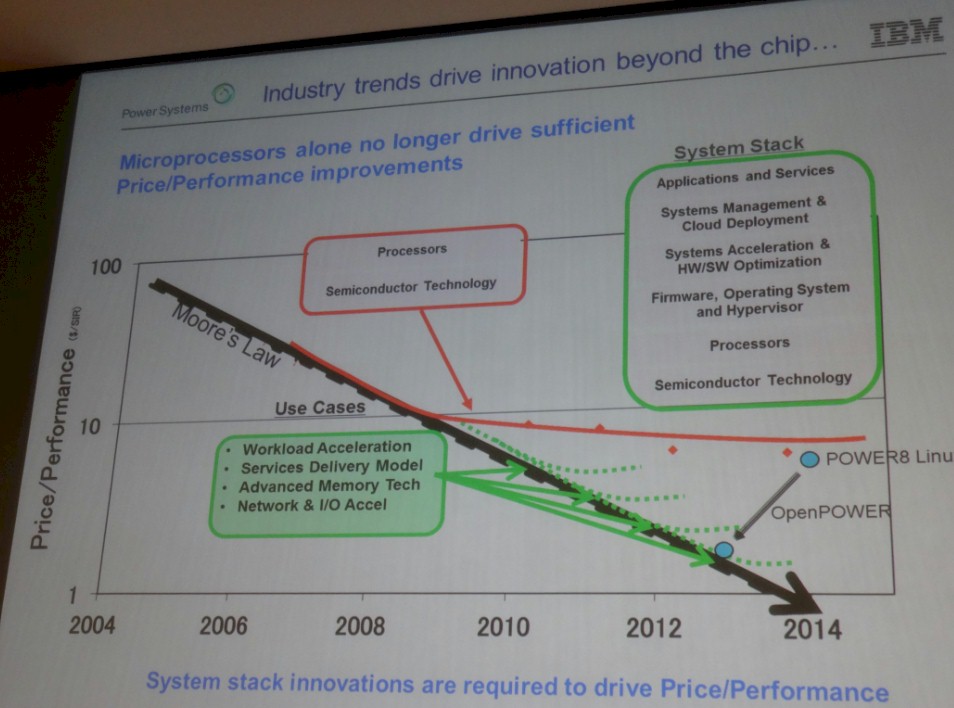
“GPUs and FPGAs are going to very important to us in keeping that cost of performance coming down,” McCredie said. “Clearly programming has been a big problem, but this takes care of a whole lot of address space as the hardware takes care of moving copies of data back and forth.” Specifically, McCredie is talking about the NVLink technology that it is working with Nvidia to create, which will couple multiple GPU coprocessors to each other to share memory and also will link GPUs to future Power processors. He is also referring to the Coherent Accelerator Processor Interface, or CAPI, which allows for various coprocessors linking to the Power8 and future Power processors to hook into the memory complex of the Power8 chip, making FPGA cards, network cards, and other devices look like what IBM calls “a hollow” core to the main memory on the Power8. That means the memory between these devices is virtualized and allows for easier programming, with the hardware managing the movement of data between the Power8 chip and external accelerators linked to it over CAPI.
These are themes that the OpenPower partners have been espousing since the organization was founded, but McCredie went a bit further in the details by actually showing an HPC roadmap that extends out to 2017 involving key partners Mellanox for networking and Nvidia for coprocessing.

All three companies are, of course, working together to build two massive hybrid supercomputers for the US Department of Energy to the tune of $325 million. The larger of the two is called Summit, which will weigh in at 150 petaflops and will be based on IBM’s Power9 processors and Nvidia’s future “Volta” Tesla coprocessor. The Summit machine, which will be installed at Oak Ridge National Laboratory, could be expanded to 300 petaflops over time. The smaller of the two machines is called Sierra, which will go into Lawrence Livermore National Lab and come in at around 150 petaflops. Significantly, about 90 percent of the floating point performance of these two systems, which are expected to be installed in 2017 or 2018, will be coming from the Tesla coprocessors, not the Power9 processors. (This is why we believe that IBM could go so far as to remove vector units from future Power9 chips. If IBM believes in coprocessors, why bother with integrated vector units?)
According to a presentation at the SC14 conference last fall by Jeff Nichols, associate laboratory director at Oak Ridge, the Summit machine will have around 3,400 server nodes, each with multiple Power9 processors and multiple Volta generation Nvidia GPU coprocessors. The Power9 chips will support DDR4 memory and the Nvidia GPUs will support High-Bandwidth Memory (HBM) 3D stacked memory, which was developed by Hynix and Advanced Micro Devices. The combined HBM on the GPU and DDR main memory on the CPU will amount to 512 GB per node, and importantly, all of the GPUs and CPUs in the node will be able to address all of this memory as a single entity. Nichols said that each node will have 800 GB of non-volatile memory – precisely what kind has not yet been revealed. This memory can be set up as a burst buffer between the server nodes and any outside storage or as an extension to main memory from the CPUs. This suggests that the burst buffer will link to the Power9 processors through CAPI. The Volta GPUs will link to each other and to the Power9 processors in the Summit system through Nvidia’s NVLink point-to-point interconnect. The nodes in the Summit and Sierra systems will link to each other using 100 Gb/sec EDR InfiniBand, which is just coming to market now.
These specs for Summit jibe with the roadmap that McCredie revealed above. The Nvidia GP100 coprocessor is one that is code-named “Pascal,” which is due to come to market next year, while the GV100 is the Volta coprocessor. The Power Next chip in the roadmap is also sometimes called the Power8’ (that is an apostrophe, and it means “prime” which means something short of a “plus” variant of a Power processor design, if history is any guide). The NVLink connections run at 20 GB/sec, and presumably the enhanced NVLink ports above will either run faster, have more links between devices, or both.
“IBM is creating a new roadmap on our path to exascale. We have IBM, Mellanox, and Nvidia all working together, and we are putting a whole roadmap together to supply this technology to you guys in a bunch of increments,” McCredie said, referring to the audience of oil and gas executives in the audience of 500 on site at the Rice University event, the untold number watching the event from the web, and indeed the HPC community overall. “We are going to go for roughly one release per year, and with each release we will be better than the past.”
The revelation of a complete OpenPower roadmap to the HPC community is an important step for IBM, Nvidia, and Mellanox individually and as partners in the OpenPower Foundation. Customers who want to invest in systems based on this technology make their decisions many years in advance and they need to see such roadmaps and believe that the companies that create them are behind that. The Summit and Sierra systems that are part of the CORAL system procurement by the Department of Energy were important, but that roadmap is important for other customers who do not want to invest in one-off designs for the supercomputing elite. IBM, Nvidia, and Mellanox all want for their investments to go more mainstream than two big deals that capture some big headlines, and by revealing the roadmap, the members of the OpenPower Foundation is doing their part to show they are in it for the long haul.


Betting On Mass Customization In A Post Moore’s Law World
If you wanted to wrest control of datacenter compute as embodied mainly in the Xeon SP processor away from Intel, there are a number of approaches that you might take. You could take Intel head on in the core of its market, as AMD has done with the Epyc line …
With Blackwell GPUs, AI Gets Cheaper And Easier, Competing With Nvidia Gets Harder
If you want to take on Nvidia on its home turf of AI processing, then you had better bring more than your A game. You better bring your A++ game, several vaults of money, and a few bags of good luck. Maybe a genie in a bottle would help, too. …

Server Budgets On The Mend As Pandemic Tries To End
Businesses are judged quarter on quarter and year on year, but you have to look at the long haul and the flow of all business over time to really judge properly. That’s why we are data wonks here at The Next Platform. And it is also why we are relieved …
The chart above shows how the price of a unit of computing power, expressed in inflation adjusted dollars, has fallen in a linear fashion
Umm, that graph has a logarithmic Y-axis, so it’s falling exponentially, not linearly.
Absolutely right. Just moving too fast.