
Just because the center of gravity for GenAI compute and other kinds of machine learning and data analytics has shifted from the CPU to the XPU accelerator – generally a GPU these days, but not universally – does not mean that the choice of the CPU for the system hosting those XPUs doesn’t matter.
In fact, the choice of the CPU in the system is critical, and the design of that CPU, its main memory capacity (which is used as a king of L4 cache for the XPUs to store model weights and embeddings), the interconnects that it has to link it to the XPUs and to the outside world, and the accelerators that it has onboard to help speed up certain system functions can make the difference between getting the most value possible out of those XPUs possible and throwing a hell of a lot of money up the cooling towers of the datacenter. These days, the worst thing in the world is a GPU that costs $40,000 or $50,000 and that is not working its cache off.
AMD and Intel have been hawking their high-end Epyc and Xeon CPUs as a means of driving more throughput in GPU hosts. Specifically, earlier this year, AMD has been showing how using its “Turin” Epyc 9575F processor with either its own “Antares” MI300X or Nvidia’s “Hopper” H100 GPU accelerators can drive just shy of 10 percent more AI inference performance than the top-end Xeon 5 processors. Intel has been making the same case for its high-end “Granite Rapids” Xeon 6 6900P processors to be a preferred CPU for XPU host servers. Nvidia designed its own “Grace” CG100 Arm server processors explicitly to be paired with its datacenter GPUs for both HPC and AI workloads, and of course every hyperscaler and major cloud builder in the United States and China and HPC centers in Europe and India are driving their own Arm server chip designs for a similar purpose.
NeuReality, a chip startup based in Israel that has been focused on inference, is now laying down the gauntlet and working with Arm to bring out a new Arm server chip focused solely on being the host processor for both AI inference and AI training workloads.
Up until now, NeuReality has been focused on AI inference, starting first with FPGAs running AI inference algorithms and then building a custom eight-core Arm host processor called the NR1, which it launched in November 2023, that had onboard accelerators for AI workloads to do much of the heavy lifting that other CPUs do not do well and that can be offloaded from the GPUs.
NeuReality was co-founded in September 2018 by Moshe Tanach (its chief executive officer), Yossi Kasus (vice president of chip design), and Tzvika Shmueli (vice president of operations), and the team of 80 people it has built has expertise from Marvell, Intel, Mellanox Technologies (part of Nvidia for a while now), and Habana Labs (also part of Intel for a while). Tanach was previously director of architecture for Marvell’s system-on-chip designs. Kasus was VLSI project manager at EZChip, the folks that made an Arm-based DPU engine that was eventually acquired by Mellanox in 2016 and which is the basis of the Nvidia “BlueField” DPUs. Shmueli was vice president of engineering at Habana Labs and worked up through the chip ranks at Mellanox over a decade and a half before that.
As best we can figure, NeuReality has raised around $70 million in seed funding and a following four rounds, including funding from SK Hynix and Samsung among a slew of private equity firms.
These days, PC makers carve out “AI PCs” distinct from regular PCs, and NeuReality is carving out “AI CPUs” in the datacenter as distinct from other CPUs, and was founded on the principle that an AI host had different needs from hosts doing other work in the datacenter. To be fair, AI inference before late 2022 put modest demands on a host CPU. But the advent of GenAI has made AI inference a much heavier workload, and now a host with a beefy CPU and its companion XPUs that might be good for running AI training will also probably work well for AI inference at a smaller host count. It is rather convenient that this has happened, but the hundreds of companies providing specialized AI inference gear as well as the homegrown products created by the hyperscalers and cloud builders for inference have probably been jeopardized.
But even if you do that, this is not the same thing as having a host CPU explicitly designs for AI inference and training, not just any high performance workload. The NR1 was an interesting first pass, and shows the architecture that will be coming with the much beefier NR2 chip that will be launched in 2026 and start shipping in volume in 2027.

The NR1 had eight Arm Neoverse N1 cores, sixteen general purpose DSP cores, sixteen audio DSP cores, and four video engines. These extra accelerators are designed specifically to do some of the host processing for handling visual, audio, and text data used by AI models. The NR1 had 20 channels of LPDDR5 memory (also used in the Nvidia Grace chip), delivering 160 GB of capacity and 256 GB/sec of memory bandwidth. (This was admittedly kind of small, but so were inference jobs when the NR1 was mapped out five years ago.) The chip has two 100 Gb/sec RoCE v2 Ethernet ports to talk to other CPUs in a chassis and to the outside world.
The special sauce in the NeuReality CPU design is something it calls the AI-Hypervisor, which is a hardware-based set of firmware that manages data movement inside the host GPU and to the XPU accelerators they manage as well as providing quality of service guarantees and hooks for a hierarchical programming model that makes using the kernel libraries that NeuReality has developed (or ones you might create yourself) easier to run on this host.
With the embiggening of AI inference thanks to GenAI, NeuReality knows it needs to get a beefier host CPU into the field, and it is working with Arm to make use of its Compute Sub System blocks to speed up development and get its NR2 chip out the door next year. Arm rolled out the next-gen CSS blocks in February 2024, which speed up the time it takes to
Specifically, Tanach tells The Next Platform, the NR2 will be based on Arm’s “Poseidon” V3 cores – the ones that has hefty SVE2 vector units in them and that are probably also going to be used in Nvidia’s “Vera” Arm CPUs that debut next year. NeuReality is licensing the “Voyager” CSS V3 package from Arm , which has a bunch of technology all wrapped around the cores and ready to go. Like this:
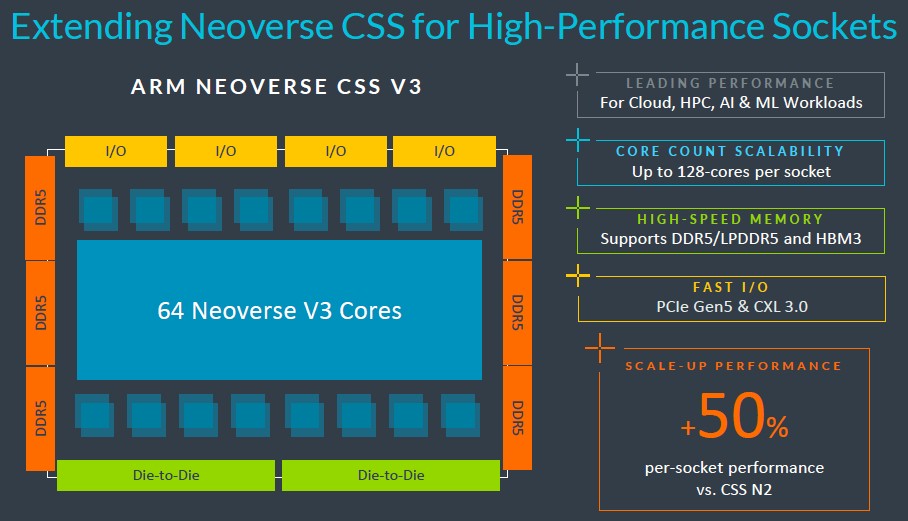
Tanach is not specific about what components of the CSS V3 package it will be using or what the accelerator counts will be that are integrated into the NR2 package, but he did say that it would offer a two chiplet option to boost an NR2 socket as high as 128 cores and that it would also be boosting the networking capabilities of the package – presumably meaning much faster ports but likely also meaning a lot more ports. The NR2 will, as you might expect given the heritage of the people designing it, have an integrated AI-tuned NIC that will have real-time model coordination, microservices-based disaggregation, token streaming, KV-cache optimizations, and inline orchestration. The networking stack will also include a fabric engine to streamline the dataflows between AI clients and servers and also within AI pipelines running on clusters built using NR2 processors and various XPUs.
The NR1 chip shows the differentiation that NeuReality brought to relatively light inference workloads and suggests the kind of impact the company wants to have with the NR2 follow-on.
“With the NR1, we built a heterogeneous CPU managed by the ARM cores running Linux and Kubernetes, but we made sure the data path was mostly offloaded to the GPU or the other processors,” Tanach says. “And we, coupled with Arm, showed 2X to 3X improvement on cost of AI operations in LLMs, and even 10X improvement when you are running computer vision ingestion pipelines and multi-modality pipelines that are the front end to LLMs.”
We look forward to seeing the feeds and speeds of the NR2 processor and how it will differentiate from X86 CPUs from AMD and Intel as well as the Arm-based CPUs that the hyperscalers and cloud builders are designing for their own workloads and to attract customers to their clouds with a price/performance sales pitch over X86.
“What’s specifically interesting about what NeuReality is doing around NR2 is that it puts the accelerator at the heart of the system, which is important, but also does so in a way that doesn’t neglect the fact that CPUs are critical to that AI compute infrastructure,” Mohamed Awad, general manager of the infrastructure business at Arm, tells us. “We are not talking about, you know, ‘wimpy CPUs’ here – NeuReality is putting our full on, CSS V3 in this chip, and they are talking about 64 cores and 128 cores. I think the point is this: this market is just starting to take off. There are going to be lots of different architectures that emerge.”
And there is going to be a lot of money to chase for AI host CPUs. Tanach says that of the $32 billion that Intel and AMD make selling X86 CPUs into the datacenter, only 20 percent of the revenue is coming from AI systems. And in the long run, a much higher percentage of CPU sales will be driven by AI platforms. And NeuReality is betting that a custom, highly tuned Arm processor that is explicitly made for AI training and AI inference can take a chunk of share away.
The hyperscalers and cloud builders believe this, obviously, since they are making their own Arm server chips. Nvidia believes this or it would not have bothered with Grace, and then Vera. But Grace has its limits in terms of memory capacity and core count, at 72 cores. And Vera is only going to have 88 cores. So there is a place for someone to put out a set of SKUs that range from maybe 32 cores to 128 cores in an AI CPU – and one that OEMs and ODMs can build systems around and add value in a way that is very tough for them to do with Nvidia’s Grace and Vera chips, which are part of a full and complete Nvidia stack.

Supermicro Racks Up The System Revenues
There is wracking up the money, and racking up the servers – and Supermicro, which is sometimes an OEM and sometimes an ODM as well as a motherboard and component supplier to those who want to be either, is doing both here at the beginning of its fiscal 2024 year. …
More Upward Revisions On AI Infrastructure Spending
Here is a question for you. What is more difficult: predicting the weather thirty days out or what global AI infrastructure spending will be out to the end of the decade? We don’t know, but it sure looks like someone is gonna spend a lot of money on infrastructure either …

HPE Uses AI To Drive The Business, Which Is Increasingly AI
Hewlett Packard Enterprise is going through yet another restructuring to reduce costs, something we have seen a lot of in the past two decades and a half decades since it acquired Compaq to become a volume server peddler as well as high end system supplier for enterprises. But this time …
Comments are closed.
Looks good! Bringing networking closer to the CPU and moving specialized processing steps from software to hardware (job orchestration, pre/post-processing, data forwarding, …) sounds like the way to go, especially if it yields 2X to 10X performance improvements at the NR2 scale of 128 Neoverse V3s (compared to 8 Neoverse N1 in NR1).
This approach of surrounding CPUs with job-specific hardware accelerators reminds me a bit of Intel’s “On Demand” DSA, IAA, QAT and DLB tech, but focused on AI inference, and always ON (iiuc) ( https://www.nextplatform.com/2023/03/31/the-age-of-acceleration-engines/ ). I wonder if those could end up being an IP option for others to integrate in their CSS designs?