

The expansion of the computing capacity in Europe for both traditional HPC simulation as well as AI training and modeling continues apace, with the Leibniz-Rechenzentrum lab in Germany announcing late last week (when we took a day of holiday) that it would be shelling out €250 million – about $262.7 million at current exchange rates – to build a hybrid CPU-GPU cluster based on Nvidia compute engines to tackle both kinds of high performance computing.
LRZ is located in Garching outside of Munich in the German state of Bavaria, has been home to some of the largest supercomputers in Europe over the past few decades. A little more than two years from now, LRZ is going to be putting a machine nicknamed “Blue Lion” into the “twin cube” Leibniz Supercomputing Center that has housed the SuperMUC family of systems that, among other things, have been innovators in large memory processing and water-cooled systems.
LRZ has only dabbled in GPU acceleration in its flagship machines, with the SuperMUC-NG Phase 2 machine installed in 2023 being equipped with 960 of Intel’s “Ponte Vecchio” GPU Max 1550 accelerators. But with Blue Lion, LRZ is going to be employing future CPUs and GPUs, which we presume will be the future “Vera” Arm server CPU that Nvidia is working on now alongside of its future “Rubin” GPU accelerator.
The Blue Lion system will manufactured by Hewlett Packard Enterprise and use a future Cray EX design, and we know that it will be using the 400 Gb/sec “Rosetta 2” Slingshot 400 interconnect that HPE just started talking about a few weeks ago at the SC24 supercomputing conference. Slingshot 400 is expected to start shipping in Cray EX machine in the fall of 2025, and will be pretty mature by the early 2027 expected deployment date for the Blue Lion machine. HPE is not expected to push to “Rosetta 3” Slingshot 800 networking until the fall of 2027, about a year after when parts of the Blue Lion machine will start shipping to LRZ.
You can never wait for the next technology in HPC and AI. You have to go to war with the GPU Army and interconnect Navy you can deploy at the time.
LRZ and HPE did not give us a lot of information on the architecture of the Blue Lion system, but they did give us a few data points to play with. The Gauss Centre for Supercomputing at LRZ said in its statement that the Blue Lion machine “will have approximately 30 times the computing power of the center’s current flagship system SuperMUC-NG.” And the Bavarian prime minister, Markus Söder, said in the official statement from the Bavarian government that the Blue Lion machine “can handle 7 exaflops of computing power per second.” We also know that Federal Ministry of Education and Research (BMBF) and the Bavarian State Ministry of Science and the Arts are both kicking in half of the €250 million total budget for the machine, which includes operating costs between 2027 and 2032 inclusive.
It is very difficult to make all of those numbers square and plumb with each other without having more data, which is not forthcoming. But for fun, we took a stab at it. Given the high cost of electricity in Europe, it is not surprising that the machine will be 100 percent direct liquid cooling, using water at 40 degrees Celsius to extract heat from Blue Lion, which will be used to heat the LRZ offices as well as those of other organizations in Garching.
As far as we know, there is no need to build a new datacenter at LRZ to house Blue Lion, that that allows for more of the budget to be used for buying iron. Without knowing the machinery, we can’t be sure how much juice it will burn, but for fun we assumed pretty aggressive discounting on the CPUs and GPUs by Nvidia given that the competitive situation will be different in 2027 than it is today. We also assumed pretty aggressive energy efficiency when it comes to cooling of the Blue Lion system, and therefore less electricity usage than might be assumed. After making our assumptions, here is our first pass guess on that Blue Lion might look like compared to prior LRZ flagship systems and their add-ons over the past decade and a half:

As usual, items in the table above marked in bold red italics are estimates by The Next Platform.
We have plugged in HPCG benchmarks, which are the most aggressive tests in the HPC suite, since the official HPCG results are being used to gauge the relative performance of the Blue Lion machine compared to the existing SuperMUC-NG machine.
We assume that a future Vera CPU will have at least 144 cores compared to the 72 cores of the current Grace CG100 processor, but concede that 96 cores with only 768 GB of LPDDR5 main memory would probably be sufficient as a host for two future Rubin GPUs. Our numbers above assume 144 cores (2X that of Grace) against 768 GB of main memory (33 percent more than Grace).
What is immediately obvious is that if this turns out to be the case and the node count is around 2,200 with one Vera CPU for every two Rubin GPUs – a number we backed into for a quad-chiplet Rubin GPU with 1.8X the performance of a “Blackwell” B200 GPU, then those 4,400 Rubin GPUs will drive around 712.8 petaflops of peak 64-bit floating point performance. Assuming about 65 percent computational efficiency, then the Rubin GPUs, with 288 GB of HBM4 memory each, will deliver about 463.3 petaflops sustained on the High Performance LINPACK benchmark that is used to gauge the performance of supercomputers in the HPC space.
If you take the SuperMUC-NG Phase 1 machine, which is the only partition of SuperMUC-NG that has had the HPCG test run against it as the performance baseline, then just a tad bit more than 30X of 207.8 teraflops on HPCG for SuperMUC-NG Phase 1, you get an HPCG rating of over 6,300. Our raw performance for the GPUs (H100 times 2.25X gets you Blackwell times 1.8X gets you Rubin) comes in at 29.3X; call the extra but to 30.5X some performance tuning or a rounding error.
If you further assume that the compute engines and their attached memory represent about half of the budget for Blue Lion between 2027 and 2032, then that means a Vera-Rubin superchip in 1:2 ratio costs around $50,000. That number is closer to $80,000 for a B200 superchip today. If these numbers are right, either LRZ is getting a hell of a deal, or we budgeted too high for the Cray EX system and power and cooling for five years.
It is hard to say.
But we think that being able to deliver about the same number of CPU cores in Blue Lion as are in SuperMUC-NG Phase 1 is important for LRZ because that means it has roughly the same CPU-only oomph to run applications as they are waiting to be ported to GPUs. And it means that CPU-only codes that cannot be easily ported to GPUs will run no worse – and very likely better – on a Vera CPU than they do on a “Skylake” Xeon from Intel today. The fun bit is that the node code will actually go down from SuperMUC-NG Phase 1 at 3,240 nodes at 96 cores each across two Xeon processors to 2,200 nodes with 144 CPU cores each. A smaller number of nodes means fewer parts of all kinds.

The neat thing about the Blue Lion supercomputer as we have imagined it is that it has 2 percent higher core count that SuperMUC-NG Phase 1 in 32.1 percent fewer physical nodes, but the aggregate memory capacity across the CPU nodes will rise by 4.6X, the peak FP64 oomph on the tensor cores in the Rubin GPUs will rise by 26.5X, but HPL performance might only increase by 23.8X because of the shift to a GPU accelerated architecture and HPCG performance will increase by maybe 30.5X thanks to the high bandwidth memory, which only goes up by a factor of 10.1X compared to the SuperMUC-NG Phase 2 partitions (not used in the relative performance calculation) based on the Ponte Vecchio GPU from Intel.
These HPCG numbers for Blue Lion are consistent with the “Alps” machine at CSCS in Switzerland, which are based on GH200 superchips based on current Grace G100 Arm server CPUs and still current-ish “Hopper” H200 GPUs. Alps has 10.752 GPUs and a rating of 3,671 teraflops on the HPCG test (a truly abysmal number if you think about it in terms of how much computation you can get to chew on the HPCG test), and that works out to 0.341 teraflops per H100 GPU. If you assume you get 2.25X more HPCG performance moving from the Hopper GPU to the Blackwell B200 GPU and then another 1.8X moving from that Blackwell to a Rubin R100 GPU, an Alps machine as currently configured would deliver 1.382 HPCG teraflops per GPU, and if you multiply that by 4,400 GPUs, then you would get 6,085 teraflops on HPCG. That is within 4 percent of what we calculate LRZ expects from Blue Lion. (An R200 Rubin GPU will have more memory capacity and bandwidth and will be able to therefore do more work with the same GPU).
That leaves the 7 exaflops figure that the government of Bavaria was talking about for Blue Lion. Well, for one thing, that is certainly not an FP64 number. A Rubin R100, in our scenario, would deliver around 36 petaflops at FP4 precision on sparse matrices, and 18 petaflops on dense matrices. The Blackwell B100 and B200 do 10 petaflops on dense matrices and 20 petaflops on sparse matrices, and these estimates for Rubin are just 1.8X that of the Blackwell numbers on the tensor cores.
However, with this performance and this number of GPUs that we expect on Blue Lion, we cannot get 7 exaflops any way we cut it. Here is the distribution of speeds for various precision levels:
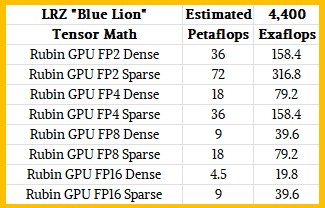
We have reached out to get clarification. This is a peculiar piece of data we cannot easily fit to. If the Blue Lion machine had 3,422 nodes and if the Bavaria politician was talking about FP16 performance on sparse matrix math, then you would get 7 exaflops of aggregate compute. But generally, when these hybrid HPC/AI machines are spoken about and AI workloads are specifically referenced, companies (starting with Nvidia and having everyone following because, well, this is where the marketing money in the IT sector comes from now excepting a tiny slice from AMD) go with the least dense and lowest precision math because it makes the exaflops number sound better. So we would have expected the press release to say “79 exaflops” at the very least, or brag it all the way up to “over 300 exaflops” if there was FP2 precision running on tensor cores with spare matrices.
There are a lot of assumptions in that table, and we know it. If you know something better, say something. This is just the first machine from 2027 that we have even heard anyone talk about, so we are excited to try to figure out what it might look like. From our point of view, it looks like performance will go up as we expect and price/performance is going to improve even faster thanks to competition. The HPC centers of the world are going to benefit in a backhanded way from the competition that the hyperscalers and cloud builders are bringing to bear with their homegrown AI accelerators.
Nvidia prices – and therefore profits – will have to come down from their stratospheric levels, and Big Green will have to make it up in volume. Or, this is just a special one-off deal with great pricing. We strongly suspect the former, not the latter. None of this Nvidia pricing can hold forever, especially in a world where the top eight buyers of AI acceleration in the world are all making their own devices as well as buying Nvidia GPUs for AI workloads.
The other important thing to note is that for flagship systems, LRZ has been an Intel shop since it installed a Linux cluster based on Intel Pentium 4 processors back in 2003 in the wake of the whole Beowulf and MPI clustering revolution. The lab had a few Fujitsu vector machines in the late 1990s and a few Hitachi vector machines in the early 2000s, but in 2006 it installed the first of a pair of SGI Altix 4700 shared memory X86 servers clustered up into a big fat NUMA box and it has used X86 processors – and only X86 processors – in its machines since that time with the exception of the SuperMUC-NG partition using Intel GPUs. So the move to Nvidia GPUs and Arm CPUs is noteworthy.
Yet another marking of an end of the end of the Intel era.
Blue Lion also represents a change away from IBM and Lenovo, which bought IBM’s X86 supercomputing business a decade ago and has been doing business at LRZ since then, and towards HPE, which has never had a big deal with LRZ before for a flagship machine. (The SGI machines from 2006 and 2007 do not count, since HPE didn’t own them at the time.) This might be a testament of the Cray EX design, but it also might have something to do with a trade war that might be ratcheting up between the US and China that LRZ does not want to get caught up in if Lenovo, which is half American and half Chinese, comes under some sort of pressure. It is hard to say, and no one will want to talk publicly about it.

Nvidia To Build DGX Complexes In Clouds To Better Capitalize On Generative AI
GPU computing platform maker Nvidia announced its financial results for its fiscal fourth quarter ended in January, which showed the same digestion of already acquired capacity by the hyperscalers and cloud builders and the same hesitation to spend by enterprises that other compute engine makers for datacenter computing are also …
VMware Partners Its Way Deeper into Cloud, Edge, And AI
Software maker VMware has always been about tight partnerships with other tech vendors. When you are middleware between hardware and operating systems, you sort of have no choice. You need to support a diverse set of hardware below and a rich of operating systems and applications above. During its early …
Google Covers Its Compute Engine Bases Because It Has To
The minute that search engine giant Google wanted to be a cloud, and the several years later that Google realized that companies were not ready to buy full-on platform services that masked the underlying hardware but wanted lower level infrastructure services that gave them more optionality as well as more …
If you assume HPL-MxP flops about 10 times faster than HPL would that fit the 7 exaflop marketing number?
Yes.
HPC contracts bid several years out in the future are a bit of a hedge in Nvidia’s sales pipeline, contrasted against all the AI business, which all seems to be “right now, as soon as I can have it”. Probably wise to get some future business on the books, even if the margin is lower than what they’re getting right now.
Good point, Paul. As always.