

You know what the hardest thing about building an AI system is? No, it is not getting your hands on GPUs to do processing, and no it is not getting the budget together to do a GenAI project. If you can’t convince your company to spend at least a little incremental IT money on GenAI during this hypestorm, we don’t know quite what to say.
No, the hardest thing about AI in general and GenAI in particular is getting you data act together so you are not keeping track of datasets in the cloud or on premises using a spreadsheet and not massaging data for models by hand. The hardest thing about AI is automating how AI training sessions and inference applications can get access to all of the current data at rest and in motion that comprises the totality of your company – and access to data in a useful form – and therefore can be used to do new and useful things as well as improve existing operations.
Managing that data – building something that is now known as a feature store – is the mission of Tecton, which was founded by Kevin Stump and Michael Del Blaso back in 2019 and which dropped out of stealth in April 2020. It has been a while since we talked to Tecton, and we took the opportunity of the official 1.0 release of the Tecton platform to catch up with Del Blaso about what is happening at the data layer in AI applications and how their experiences among the hyperscalers in early AI efforts informed the creation of the Tecton platform.
Creature Feature
If Kubernetes is a controller for the containers that wrap around collections of microservices we call “applications,” then Tecton is a controller that converts streaming, relational, and real-time data sources into “features,” which are ways of taking this information and converting it to normalized and enumerated data that a machine learning algorithm might call “useful data.”
This sounds easy when you put it that way – or maybe it doesn’t. Data is a moving and ever-changing thing, and converting it to semi-structured or structured data that the AI model can chew on is difficult. Not only do sources and formats of data change, but the applications using it also keep proliferating, which necessitates yet another layer of abstraction in the IT stack to create the illusion of simplicity when things are really complex. (If there is one consistent trick in IT, that is it, and the products that conceal complexity and also deal with it are the ones that succeed.) So there is an abstraction aspect to Tecton. But automating the creation of feature stores – data that is batched up or streamed and is ready to be run through an AI model – is the real pain in the neck.
The hyperscalers all learned this the hard way years ago. And many of them built their own feature stores, although they were not called that at the time.
Del Blaso, who is the chief executive officer at Tecton, got his bachelor’s degree in electrical engineering at the University of Toronto, and while there worked on the Capston Project, which created an AI system that chewed on Twitter sentiment data and stock market data to find correlations. Del Blaso did a stint as a junior design engineer for Altera, and then joined Google and rose very quickly through the ranks to become the product manager of the machine learning teams for the Search Ads business, which had access to the best models and best iron (including early TPUs) the search engine giant had to offer.
Three years in, Del Blaso moved to ride hailer Uber to be senior product manager of machine learning, and specifically was put in charge of the development and deployment of the Michelangelo machine learning platform, arguably one of the first automated feature stores in the world and a platform that allowed Uber to deploy thousands of AI models in production, covering real-time pricing, estimated time of arrival, and fraud detection among many other services, in just a few years.
Del Blaso and Stumpf met at Uber, but Stumpf has been a code-slinger for longer. He got his bachelor’s degree in computer science and management sciences at FernUniversität in Germany in 2011 and an MBA from Stanford University in 2015. In fact, Stumpf was being paid as a C++ developer long before he entered university and worked for a string of companies and startups before co-founding Dispatcher, which he calls an Uber for long haul trucking, in November 2013 and becoming its chief technology officer. We are not sure if Dispatcher became Uber Freight or was knocked out by it, but we do know that Stumpf moved to Uber in 2016 as a senior software engineer and in within a year was the technical lead and manager for Michelangelo.
Stumpf and Del Blaso left Uber to make a commercial variant of Michelangelo, but they did not spin up an open source project to do it. Instead, after the Tecton uncloaking they agreed to make the Tecton feature store compatible with the open source variant that had emerged, called Feast, that was developed by Willem Pienaar when he was at Gojek, an Indonesian payment processing platform, in conjunction with Google Cloud. Pienaar worked for Tecton between November 2020 and March 2023, and left to start Cleric in August 2023. Cleric seeks to create a site reliability engineer (SRE) assistant based on AI, much like JARVIS is to Larry Ellison Tony Stark.
But this story is not about Cleric, it is about Tecton.
Here is what the ML data massaging and application workflow looked like before feature stores:
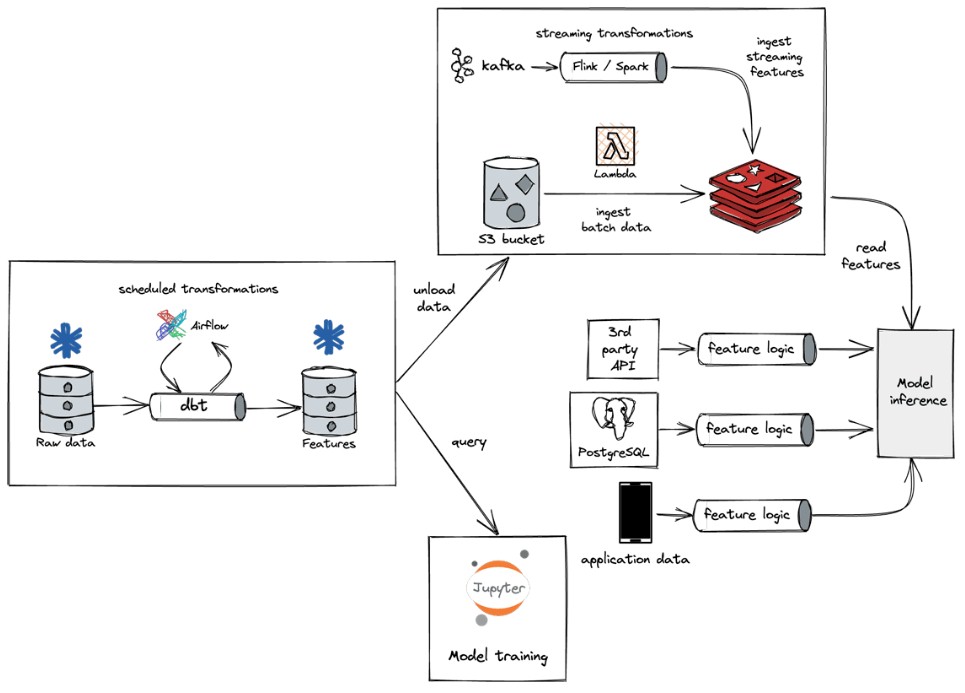
And here is what it looks like with Tecton:
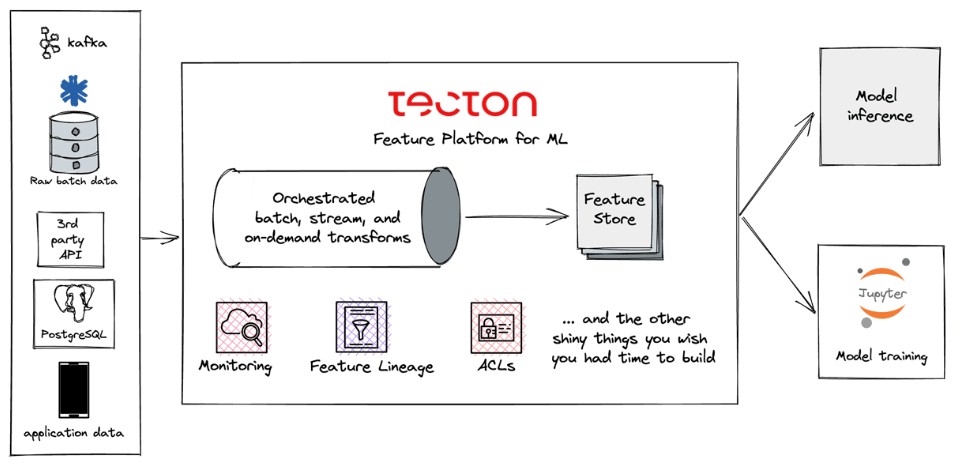
You get rid of a whole lot of arrows with Tecton, as you can see.
And with that, there is enough background to hear what Del Blaso has to say about the state of MLOps and how Tecton fits in it – and rises above it.
Timothy Prickett Morgan: You have been responsible for some pretty serious ML platforms over the years, and arguably the Google team you were on wrote one of the foundational papers describing MLOps. But from what I can see, the really interesting stuff you did was at Uber.
Michael Del Blaso: Uber was a little bit different. They were just getting started with machine learning. They brought all of this data together and were using it to do business intelligence – like making charts and PowerPoint slides. When I joined the mission became: How do we do something more with this data? How do we affect the customer experience? And you do that by automating decisions with that data, which is effectively what machine learning is.
So I was given a task by Uber’s CEO in my first week on the job to democratize machine learning in that company. And so we built an ML platform called Michelangelo that allowed all of the different data science teams and the different engineering teams to actually have a way to productionize machine learning and integrate it into the business.
This was at a time when there wasn’t there wasn’t like a playbook for this. We had to invent a lot of this infrastructure, but it was we went through this amazing journey where Uber went from a handful of models in production to literally tens of thousands of production models making real-time decisions. And that was a pretty big deal.
That’s the journey that every company wants to go through – they want AI powering every little part of their business. And you can, and I can understand why, because there’s so much opportunity for little pieces of customer experience to be made more intelligent and all of that adds up to a qualitatively better user experience. Uber would be totally different if it didn’t have surge pricing, ETA prediction, fraud detection, and all this stuff. The service couldn’t work if it didn’t have AI in a million different places.
TPM: Tell me more about the feature store issue, because this is something that all enterprises will have to wrestle with.
Michael Del Blaso: At Uber, every team had the same problem. It was all this data engineering stuff. The serving of models was kind of commoditized, but how do we connect it to the data so we can make the right decisions, so the models know what to do? This was really hard, and it was a separate engineering project every single time.
So we centralized that and automated it. We put that into the Michelangelo platform, and called it a feature store. And Tecton expanded upon it to create a feature platform, to reflect that the problem and the solution is much broader than just storing values created from raw data.
We started Tecton around this foundational insight that the path to better models is better data, and then asked how can we bridge your business’s data to your AI systems to allow you to have way higher quality user experiences?
TPM: Tecton is still a startup in as much as most enterprises are only now starting to build operational AI platforms, and it is understandable that Tecton only has dozens of customers because companies have to move beyond one AI project with a few data scientists to hit the problem you are addressing.
But we think that companies are not going to deploy a giant AI mixture of experts models that takes hundreds to thousands of GPUs to do inference at a reasonable rate and response time, but rather lots of smaller models scattered all over the place where inference can be done on more modest hardware, possibly even inside of CPUs.
So my question to you is this: What are you seeing enterprises actually do with AI? Are they doing the former or the latter?
Michael Del Blaso: It’s a good question. I think generally people don’t know how to start. So fair observation: what they want to do is often different than what we guide them to do to at first. We try to teach people to have a fast win, let’s start with the simple thing.
TPM: Like every application modernization effort should be. But people often try to do a blockbuster – and often budget-buster – project.
Michael Del Blaso: Another way to think about it is that there are two dimensions. There’s the requirements: I need everything to run in real -time and at a massive scale, immediately. And that’s hard. You got to build up to that. And if you just take on the most insane requirements from the beginning, it’s just going to be a longer journey.
And so we help people focus on just one problem. It’s not trying to solve ten problems at the same time, choose your one business case. I’m highlighting this because I think it’s actually a benefit of working with Tecton. We provide not just the technology, the platform, but when you work with us, you get a team that’s helping you figure out how to do things properly. And this really reduces the risk of any AI project that your company takes on, because you’re getting a team of experts who have done this before.
TPM: Give me a couple examples.
Michael Del Blaso: When we talk to a bank, they say we need to have recommendations on our website. We need credit decisioning. We need fraud detection models and then their intuition often to do all of these. We say: Just get one of these things up and running, and then we know that we have a path to success within your company. And then we can repeat the playbook – we don’t want to hit the same bottleneck across all of these projects at the same time. That doesn’t lead anybody to success.
Often, there’s already some system for an important use case that’s delivering value to the business; it is already a solved problem, in a sense. And they will want to tear this whole thing down and start a whole new thing based on AI – and it’s going to be this gigantic project. We recommend to customers to develop the new thing in parallel. At first, let the technology prove itself, and then they will see with Tecton it’s so much easier to do this. And then they will slowly build all of their new signals, and slowly move things over time to this system. It’ll be more efficient, it’ll be faster. It’ll result in a better quality models. But you don’t need to set an artificially high barrier to entry or scope of project by planting your flag on the notion of killing off something that you have already been using for years.
TPM: How many companies, with teams like the ones you both worked on at Google and Uber, are trying to build an MLOps platform and will there be a winnowing of that herd? Is a Red Hat going to emerge from the crowd? Or maybe the real question is when does Red Hat – I mean IBM – buy you? What’s the landscape for MLOps right now?
Michael Del Blaso: So I think MLOps is becoming a lot more of a solved problem. And what I mean by that is there are so many open source tools. Most of those things are good for the problems that they solve. But what I would clarify, though, is that there’s a lot of solutions to problems that have already been solved, but there’s not a lot of solutions to the layers of problems, the domain of problems, that we really tackle.
If you are putting an AI application into production, there two parts. You got to get your model trained and served, and that’s much more of a commodity now, but you also need to connect that model to the data, and this is the domain of running AI specific data pipelines, data serving in real-time for the model to retrieve training data. And so this AI data platform, or feature platform, is our layer. And there’s no one who’s really at our level of maturity in this space.
We have the most mature product, and the only other folks that kind of like play in this space is when they when they have a lightweight version of this in a much broader platform. So you can say, like, like a like a SageMaker has a thing called a feature store, but we have regularly have companies come to us tell us that the SageMaker feature store didn’t work for them. They had more sophisticated needs, or they need to run at a certain level of availability, or they want a more best-of-breed solution.
Interestingly, people who understand that they need this feature platform layer, they don’t go to the AI platforms built by the big clouds. We typically don’t compete against AWS SageMaker or Google Vertex because if you just care about this specific layer, you come to us.
TPM: Do you offer your software on premises as well as on the cloud?
Michael Del Blaso: We only make use of cloud, so you could not run Tecton within your datacenter, for example.
TPM: Will you ever change your mind about that when people start building their own AI infrastructure in the enterprise?
Michael Del Blaso: I think it’s good that people try to build their own. Do you know why? Because it’s so hard. People try it, and then they discover it’s going to take us so many engineers and they just want to use Tecton.
TPM: How big of a deal is the Tecton 1.0 release?
Michael Del Blaso: It represents a big maturation of a platform, which may not be a sexy thing to talk about, but also an expansion into a whole new domain of AI use cases.
But more importantly, people are struggling. People are at different layers of the software or at different stages of maturity. I think we’re seeing the market grow, but we’re also seeing the complexity of the problem grow as well as new types of AI being applied in different places. This is a real, major opportunity we’re excited about.
TPM: That’s my last question: How is it that someone’s not going to snap you up, whether it’s AWS or Google or Microsoft or IBM?
Michael Del Blaso: We’ve got a pretty solid business opportunity in front of us.
TPM: That never stopped anybody from taking a billion dollars. [Laughter]

The Pure Unification Of Block And File Storage
Companies have been working for years to pull together block, file, and object storage under a single umbrella, giving enterprises that are at times dealing with petabytes of data spread across datacenters, the cloud, and the edge a simpler way to manage, organize, and access all that information. We have …
AI Powerhouses Choose The Nuclear Option
When you need to provide electricity to power and cool 100,000 accelerators, or maybe even 1 million of them in a few years, in a single location to run an AI model, you have to start thinking about the unthinkable if you also want to use carbon-free juice to power …
The Appetite For Datacenter Compute Is Ravenous
It has been an invaluable asset for AMD as it re-engaged in the datacenter in the past decade to have Forrest Norrod as the general manager of its datacenter business. Norrod ran the custom server business at Dell for many years after working on X86 processors at Cyrix and being …
Swell interview, on a topic I hadn’t quite thought about beyond graph and vector databases! It looks like Tecton has a solid and important niche setup for itself, focusing on heterogeneous data orchestration (control, normalization, enumeration, streaming, …) for AI modeling (training and inference), with a precise expertise and focus, that prevents the “jack of all trades, master of none” syndrome which could affect competing “overly ambitious” frameworks (a bit like the “Do One Thing And Do It Well” design philosophy that is behind UNIX programs).
I like De Blaso’s advices to “start with the simple thing”, and “Just get one of these things up and running, and then we know that we have a path to success”, especially with the idea of having multiple small AI models each doing something rather specialized, and doing it well, from a common orchestrated heterogeneous data pool. The main challenge I guess is ensuring security, privacy, and maybe secrecy as well, when the system is cloud-based vs on-prem or co-located.