

Online retailing giant Amazon has so many “traveling salesman optimization” NP hard problems is it crazy. In fact, Amazon has nested, or chained, NP hard problems. Figuring out how to get an item from bin 23 in warehouse 42 across the country by myriad possible routes to your doorstep with the least time (or the least energy, if you want to optimize for that) – is enough to make your head explode.
The problem is so bad that Amazon’s cloud computing division, Amazon Web Services, invested in the AWS Center for Quantum Computing at the California Institute of Technology back in October 2021, and it is still so bad that AWS looked at the various solvers at the heart of many finite element analysis programs and electromagnetic simulators and decided to build one of its own, called Palace, which it has just open sourced on GitHub to try to build a community around it.
Palace is short for Parallel Large Scale Computational Electromagnetics – in that way that acronyms are tortured to make a real word. (PLSCEM doesn’t run off the tongue, so we get it.) The macroscopic form of “Maxwell’s Wonderful Equations,” as many of us were exposed to in college and as my own physics professor referred to the laws of electricity and magnetism created by James Clerk Maxwell in 1861 and 1862, are difficult enough; the microscopic equations that govern down at the atomic level can be very unwieldy, but are useful when designing a superconducting quantum chip, as AWS is doing precisely because it wants to solve its ultrascale – what is beyond hyperscale? – traveling salesman optimization problems and be more profitable.
(Interesting aside and possibly a physics joke: It doesn’t take quantum electrodynamics simulation to create a quantum computer. Weird, isn’t it?)
AWS offers a quantum computing service already, called Bracket, for companies to play around with existing machines from IonQ, OQC, Rigetti, Xanadu, QuEra (but oddly enough not D-Wave Systems). Parent company Amazon no doubt has played with these devices, and also no doubt encouraged AWS to offer them as a service so we all can help Amazon foot the bill for its quantum computing experimentation. But just like Amazon thinks correctly that it has to innovate at the CPU SoC level to advance server design, and has thus created Nitro DPUs and Graviton CPUs based on the Arm architecture even as it sells virtual slices of X86 compute engines on EC2, Amazon knows that to drive innovation in quantum computing by designing its own superconducting quantum computing chip.
More than that feature image at the top of this story showing an AWS quantum processor, the phrase “superconducting quantum computing chip” that one of the researchers, Sebastian Grimberg, said to us, and the establishing of the center at Caltech, no one knows very much about what AWS has accomplished in its quantum chip design, or what approaches it is taking. But what we do know is that the existing tools, as far as AWS was concerned, were too expensive and did not do the job right at scale.
“This is a really hard problem, especially when you get into error correction,” Ian Colle, general manager of HPC at AWS and a long-time user and creator of HPC systems, tells The Next Platform. “Our quantum computing team realized there’s this gap. There is some really expensive tooling around here. There is a little bit of open source, and we figured maybe if we applied a lot of our smarts to it, we could create a new tool that would essentially be a very performant, at scale solver in that effort to create that quantum computer.”
The resulting Palace solver is designed to run on Arm CPUs and X86 CPUs right now, but Grimberg, a senior research scientist at the Center for Quantum Computing, says that Palace is not limited to electromagnetic simulation, but also has applicability to computational fluid dynamics, which also have very complex partial differential equations. (Grimberg has a PhD in aeronautics and astronautics from Stanford University, and fellow applied scientist Hugh Carson, who also worked on Palace, has a PhD in computational science with an focus on CFD from MIT. Carson worked on the Amazon Prime Air drone program previously. So Amazon is interested in tools that improve CFD as well.)
In a blog showing what Palace does, the physics of the simulation of a transmon qubit and readout resonator in fine-mesh and coarse mesh models is quite hairy indeed, which is why you build a simulator. (Even Einstein had a mathematician.) What we care about is the interplay of wall clock time in the simulation versus the number of cores used to scale the simulation of the transmon qubit and its resonator, and how the Graviton3 (C7g) and Graviton2 (C6g) instances did against the X86-based instances on the simulation, and how scaling up degrees of freedom in the finite elements simulated requires more cores.
Here are the charts showing the wall clock time and speedup factor of adding more cores for the coarse grained model with 15.5 million degrees of freedom in the simulation:
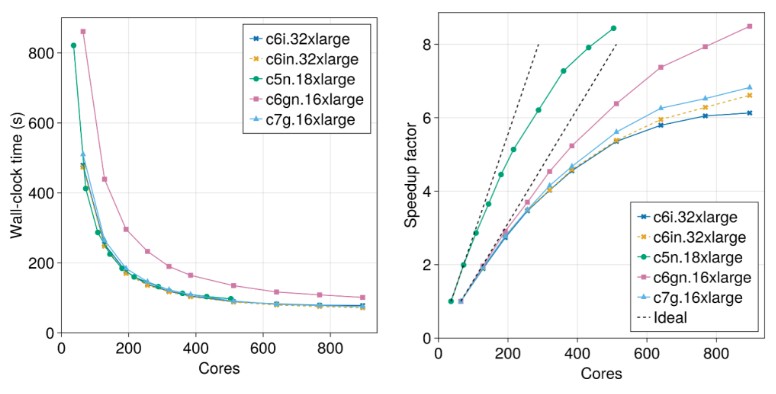
At least for this application using the Palace solver, the Graviton chips are holding their own against the most recent Xeon SPs, but it is not clear why the “Skylake” Xeon SPs in the C5n instances are doing so well. (Go figure.)
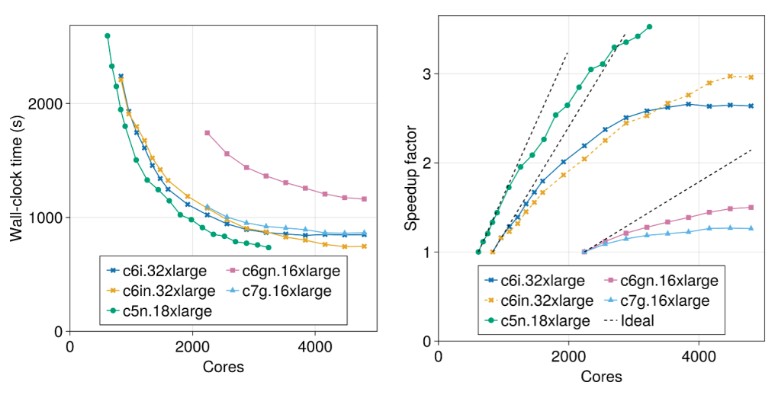
Here is the higher resolution simulation with 246.2 million degrees of freedom, which takes thousands of cores versus hundreds of cores to run and which take 12 minutes to run (more or less) compared to 1.4 minutes for the coarse grain model. That 15.8X increase in degrees of freedom is not free:
To push Palace even harder, the AWS quantum team did a simulation of a superconducting metamaterial waveguide based on a chain of lumped-element microwave resonators – and if you know what that is, Jeff Bezos wants to hire you. The idea is to predict the transmission properties of the waveguide in the range of 4 GHz to 8 GHz in 1 MHz increments, and the test scales from 242.2 million degrees of freedom with a single metamaterial unit-cell to 1.4 billion degrees of freedom with 21 metamaterial unit-cells. In this case, all of the simulations are run on the C6gn Graviton2 instances and range up to 200 instances running a maximum of 12,800 cores. Take a gander:
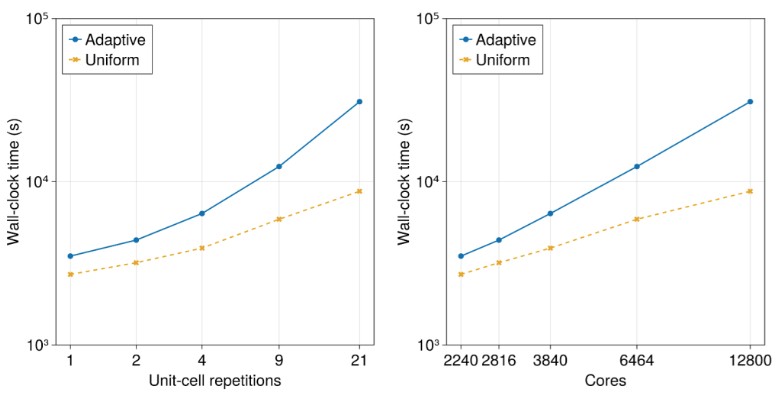
There are adaptive and uniform sampling modes shown in the chart above, but again, the interesting bit is showing that the Palace solver can scale across 12,800 Graviton2 cores. Presumably, AWS doesn’t have enough Graviton3 cores laying around to run the test on C7g instances, but if it did, we presume the wall clock time would come down quite a bit and the scale would go out as far and with about the same steepness.
Incidentally, the instances used in these tests are setup by the ParallelCluster tool created by AWS to easily stand up virtual MPI clusters to link nodes together running the Palace solver.
As for when AWS will have a homegrown quantum chip, that’s a secret for now, and probably for a while.
“We are dedicated to ensuring that we can develop a quantum computer,” says Colle. “That’s what I can tell you, and we will bring it to market as soon as we feel that it is viable.”


Amazon Gives Anthropic $2.75 Billion So It Can Spend It On AWS XPUs
If Microsoft has the half of OpenAI that didn’t leave, then Amazon and its Amazon Web Services cloud division needs the half of OpenAI that did leave – meaning Anthropic. And that means Amazon needs to pony up a lot more money than Google, which has also invested in Anthropic …
AWS Reaps The Benefits Of The Custom Silicon It Has Sown
When the hyperscalers and cloud builders were smaller and the Arm collective had failed to storm the datacenter and AMD was not yet on its path to resurgence, it was Intel that controlled the cadence of new compute engine introductions into the datacenter. Given this week, which started off with …
AWS Tunes Up Compute And Network For HPC
When it comes to hardware, there was not a lot of big news coming out of the Amazon Web Services re:Invent 2022 conference this week. And to be specific, there was not an announcement of a fourth-generation, honegrown Graviton4 processor that many had expected given that AWS, like other cloud …
The wall-clock time increases with the number of cores in the last image. Is that right? Interesting article, thank you.
Yes. It doesn’t scale perfectly. I don’t know anything that does.
It’s nice to see those ARM CPUs doing HPC with performance similar to Skylake Xeons, when solving Maxwell’s (non-demon) PDEs! I would have thought that solving for superposition and collapse of Schrodinger’s wavy probabilistic cat equations was central to designing quantum computers, but there seems to be many different layers of analysis needed to fully apprehend these novel machines (and the programs they may run). At any rate, getting NP-hard optimizations performed efficiently will be a great outcome of this tech. Just today, I was reading about how “Field-Programmable Qubit Arrays (FPQAs)” might become a thing … but given the uncertainty principles that govern the quantum world, we might never know, even if it does! ;^}
Nicely played, there.