

Chip design is as much of an art as it is an engineering feat. With all of the possible layouts of logic and memory blocks and the wires linking them, there are a seemingly infinite placement combinations and often, believe it or not, the best people at chip floorplans are working from experience and hunches and they can’t always give you a good answer as to why a particular pattern works and others don’t.
The stakes are high in chip design, and researchers have been trying to take the human guesswork out of this chip layout task and to drive toward more optimal designs. The task doesn’t go away as we move towards chiplet designs, either, since all of those chiplets on a compute engine will need to be interconnected to be a virtual monolithic chip and all of the latencies and power consumption will have to be taken into effect for such circuit complexes.
This is a natural job, it would seem, for AI techniques to help in chip design. It’s something that we talked about a couple of years ago with Google engineers. The cloud giant continues to pursue it: In March, scientists at Google Research introduced PRIME, a deep-learning approach that leverages existing data like blueprints and metrics around power and latency to create accelerator designs that are faster and smaller than chips designed using traditional tools.
“Perhaps the simplest possible way to use a database of previously designed accelerators for hardware design is to use supervised machine learning to train a prediction model that can predict the performance objective for a given accelerator as input,” they wrote in a report. “Then, one could potentially design new accelerators by optimizing the performance output of this learned model with respect to the input accelerator design.”
That came a year after Google used a technique called reinforcement learning (RL) to design layouts of its TPU AI accelerators. It’s not just Google doing all this. Chip design tool makers like Synopsys and Cadence are both implementing AI techniques into their portfolios.
Now comes Nvidia with an approach that three of its deep learning scientists recently wrote “uses AI to design smaller, faster, and more efficient circuits to deliver more performance with each chip generation. Vast arrays of arithmetic circuits have powered Nvidia GPUs to achieve unprecedented acceleration for AI, high-performance computing, and computer graphics. Thus, improving the design of these arithmetic circuits would be critical in improving the performance and efficiency of GPUs.”
The company made a run at RL with its own take, calling it PrefixRL and saying the technique proved that AI can not only learn to design circuits from scratch but that those circuits are smaller and faster than circuits designed using the latest EDA tools. Nvidia’s “Hopper” GPU architecture, introduced in March and expanding the company’s already expansive focus on AI, machine learning and neural networks, contains almost 13,000 instances of circuits designed using AI techniques.

In a six-page research paper about PrefixRL, the researchers said they focused on a class of arithmetic circuits called parallel-prefix circuits, which encompass such circuits as adders, incrementors and encoders, all of which can be defined at a higher level as prefix graphs. Nvidia wanted to fined out whether an AI agent could design good prefix graphs, adding that “the state-space of all prefix graphs is large O(2^n^n) and cannot be explored using brute force methods.”
“A prefix graph is converted into a circuit with wires and logic gates using a circuit generator,” they wrote. “These generated circuits are then further optimized by a physical synthesis tool using physical synthesis optimizations such as gate sizing, duplication, and buffer insertion.”
Arithmetic circuits are built using logic gates like NAND, NOR and XOR and a lot of wires, should be small so more can fit on a chip, fast to reduce any delay that can be a drag on performance and consume as little power as possible. With PrefixRL, the researchers’ focus was on the size of the circuit and the speed (for reducing delay), which they said tend to be competing properties. The challenge was finding designs that most effectively used tradeoffs between the two. “Put simply, we desire the minimum area circuit at every delay,” they wrote.
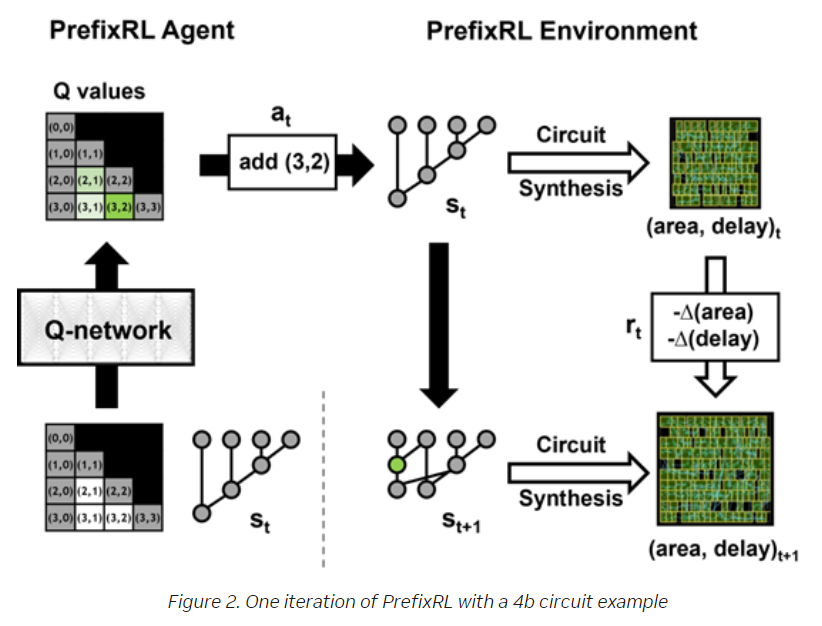
“The final circuit properties (delay, area, and power) do not directly translate from the original prefix graph properties, such as level and node count, due to these physical synthesis optimizations,” the researchers wrote. “This is why the AI agent learns to design prefix graphs but optimizes for the properties of the final circuit generated from the prefix graph. We pose arithmetic circuit design as a reinforcement learning (RL) task, where we train an agent to optimize the area and delay properties of arithmetic circuits. For prefix circuits, we design an environment where the RL agent can add or remove a node from the prefix graph.”
The design process then legalizes the prefix graph to ensure it always maintains a correct prefix sum computation and a circuit is then created from the legalized prefix graph. A physical synthesis tool then optimizes the circuit and the area and delay properties of the circuit are then measured. Throughout this process, the RL agent builds the prefix graph through a series of steps by adding or removing nodes.
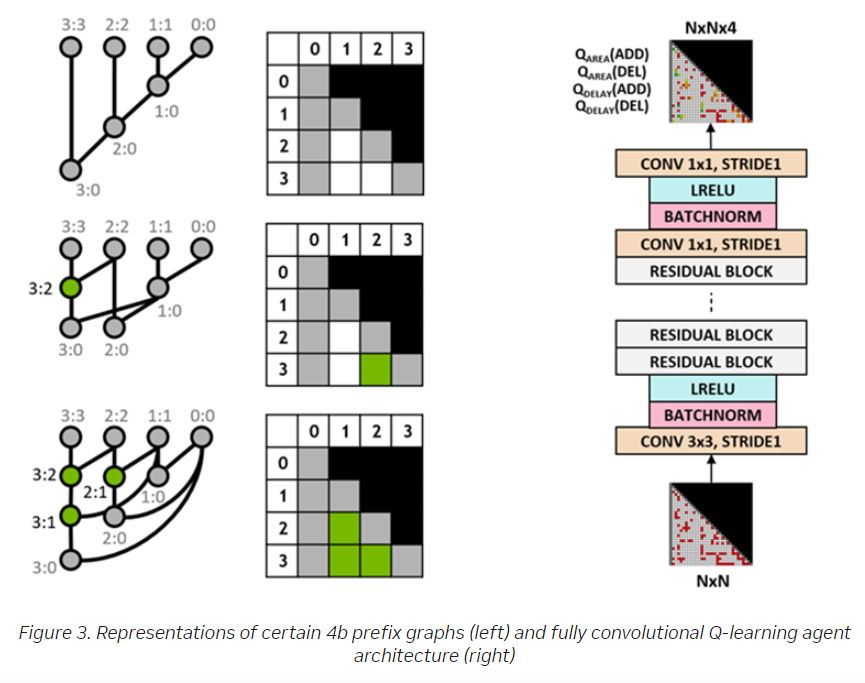
The Nvidia researchers used a fully convolutional neural network and the Q-learning algorithm – an RL algorithm – for their work. The algorithm trained the circuit design agent using a grid representation for prefix graphs, with each element in the grid mapping to a prefix node. The grid representation was used at both the input and output of the Q-network – with each element in the output grid representing Q-values for adding or removing a node – and the neural network predicted the Q-values for the area and delay properties.
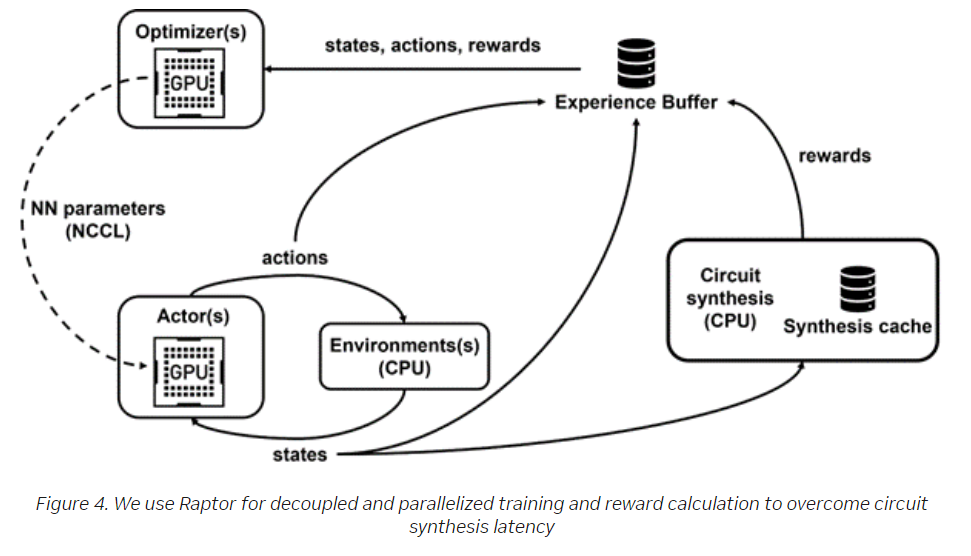
The compute demands for running PrefixRL were significant. The physical simulation required 256 CPUs for each GPU and training too more than 32,000 GPU hours, according to the researchers. To address the demands, Nvidia created a distributed reinforcement learning platform dubbed “Raptor” that leveraged Nvidia hardware specifically for this level of reinforcement learning.
“Raptor has several features that enhance scalability and training speed such as job scheduling, custom networking, and GPU-aware data structures,” they wrote. “In the context of PrefixRL, Raptor makes the distribution of work across a mix of CPUs, GPUs, and Spot instances possible. Networking in this reinforcement learning application is diverse and benefits from … Raptor’s ability to switch between NCCL [Nvidia Collective Communications Library] for point-to-point transfer to transfer model parameters directly from the learner GPU to an inference GPU.”
The network also benefited from the Redis store used for asynchronous and smaller messages like rewards and statistics and a JIT-compiled RPC for high-volume and low-latency requests such as uploading experience data. Raptor also included GPU-aware data structures for such tasks as batching data in parallel and prefetching it onto the GPU.
The researchers said that the RL agents were able to design circuits based only on learning with feedback from synthesized circuit properties, with results that use 64b adder circuits designed by PrefixRL. The best such adder delivered 25 percent lower area than the EDA tool adder and the same delay.
“To the best of our knowledge, this is the first method using a deep reinforcement learning agent to design arithmetic circuits,” the researchers wrote. “We hope that this method can be a blueprint for applying AI to real-world circuit design problems: constructing action spaces, state representations, RL agent models, optimizing for multiple competing objectives, and overcoming slow reward computation processes such as physical synthesis.”


Datacenter Becomes Nvidia’s Largest Business
Something that we have been waiting for a decade and a half to see has just happened: The datacenter is now the biggest business at Nvidia. Bigger even than the gaming business for which it was founded almost three decades ago. The rise of the datacenter business has been no …
Balancing Performance, Capacity, And Budget For AI Training
If the world was not a complex place, and if all machine learning training looked more or less the same, then there would only be one accelerator to goose training workloads. Nvidia sometimes talks that way, as if all anyone needed to do was to buy a bunch of A100 …

A Second Opinion On Future GenAI Spending
Two weeks ago, before we began our nightmare travels to get to the 2025 edition of Nvidia’s GPU Technology Conference in San Jose, we put together an analysis of the AI server and storage spending forecasts put out by the good folks at IDC. Now, we have a similar, and …
Be the first to comment