

With over 200 million users streaming its video services, the backend CDN servers, storage, and networks at Netflix have to balance performance and efficiency carefully. As one might imagine, I/O reigns supreme but having a balanced stable of compute is also critical.
The goal is to serve as many customers as possible out of a single box, says Drew Gallatin, who has helped lead efforts at Netflix to kick that rate from 200Gb/sec of TLS encrypted video out of a single box to 400Gb/sec. He says that there are even prototype efforts underway on the 800Gb/sec horizon.
The momentum toward that upper limit has been swift. It was only in 2020 that Gallatin and team were able to hit the 200Gb/sec mark but seeing four 100Gb/sec network ports open on their single-socket AMD EPYC Rome system got them thinking about what could be possible. What they put together is not just useful from a large-scale video streaming services point of view — this is something we might expect to see in other memory bandwidth-limited areas, including HPC, especially as similar nodes pop up in some of the largest supercomputing sites.
The backend serving systems being evaluated at Netflix for how well they’re pushing ultra-low latency and high bandwidth are based on 32-core (2.5GHz) AMD Rome CPUs with 256GB DDR-3200, granting eight channels with 150Gb/sec memory bandwidth. The systems provide 128 lanes of PCIe Gen-4 (250Gb/sec of IO bandwidth). Each system has two Mellanox ConnectX-6 NICs, (Gen-4 x 16). They have two full-speed 100GbE ports per NIC for a total of 4X 100GbE in total with support for critical elements, including kTLS offload on the NIC — something that is of the utmost importance for Netflix’s serving workflow. For these systems they also have eighteen WD NVMe drives (2TB) but because of when these were purchased they are Gen-3.
Gallatin says they looked at two other architectures to fit the video serving bill: Ampere’s Altra Arm Neoverse platform as well as Intel Ice Lake CPUs. For Ampere and Ice Lake both the issue of FreeBSD support was a limiting factor and there has not been ample time to optimize for Ice Lake either. There’s more detail here.
There is a nice workflow chart below highlighting what a big deal getting even 200Gb/sec means, not to mention anything beyond that. You select a movie — a client has an algorithm that fetches a few MBs ahead. NGINX gets the request and launches a sendfile request to satisfy it. That data is brought in from those NVMe drives on the lower left (aggregate 50Gb/sec) then that’s read into system memory.
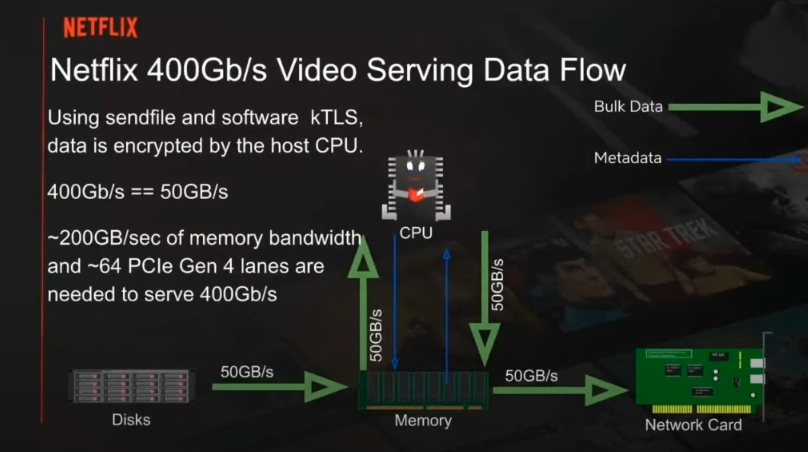
As a quick side note, Netflix runs FreeBSD, the NGINX web server and the sendfile protocol. They have kernel-level kTLS data encryption in the pipeline to avoid extra boundary crossings with all that pulling of data off disk to be written back. Gallatin says this one little feature saves around 60 percent CPU utilization.
The tough spot for Netflix is the encryption part. Doing crypto in the CPU requires an extra memory read (to read the plain text) and an extra memory write (to write the encrypted content). This doubles memory bandwidth.
In the above flow, the green arrows (reads and writes) they can remove one read and one write of data, effectively cutting memory bandwidth in half.
Luckily for Netflix, there is Drew Gallatin, who has worked for many years optimizing networks for large-scale problems and has NUMA’s potential down to a science. He started his career building the 10GbE device drivers for Myricom and after other experiences, wound up at Google in the platforms and networking division before moving to the video content giant, where he has spent over six years. All of those experiences led to a nuanced understanding of what NUMA might be able to provide, especially on a single-socket, I/O optimized platform with plenty of available I/O — assuming all the tricks in getting the various domains to talk without too much tripping and overstepping.
The NUMA aspect is interesting here. It’s all still single-socket but it’s taking advantage of the flat mode where four different chips in a package can be exposed as “quadrants” of the Rome chip. These quadrants are configured essentially as four NUMA domains.
“One thing NUMA does, when you run AMD machines in NUMA mode, is that you can make more efficient use of their memory controllers,” Gallatin says. “The strategy was to keep as much of our bulk data off the NUMA fabric as we can.” Netflix only has NICs on two of the four NUMA nodes in its setup and different numbers of NVMe for each node as well. It had to come up with some hacks to pretend a NIC was in all four NUMA domains and ended up, on average, seeing around 1.25 NUMA crossings, 75 percent of disk reads across NUMA, and 50 percent of NIC transmits across NUMA for a total of 62.5Gb/sec of data on the NUMA fabric.
This does get into the weeds — you can see the full setup here from Gallatin’s FreeBSD talk here. He also describes the Netflix (and mostly FreeBSD) limitations when it comes to Ampere and Ice Lake.
It is quite conceivable that Netflix might be able to double to 800Gb/sec with existing AMD dual-socket servers, or with future servers supporting increased memory bandwidth via DDR5 and more memory channels.

The Perfect AI Storage: Trino From Facebook And Iceberg From Netflix?
When it comes to solving data analytics problems at scale, it is tough to beat the hyperscalers. And that is why a combination of technologies that were originally developed at Facebook (now Meta Platforms) and Netflix could end up being the perfect pairing to create a “lakehouse” underpinning AI training …
Be the first to comment