
Sponsored Moving more bits across a copper wire or optical cable at a lower cost per bit shifted has been the dominant driver of datacenter networking since distributed systems were first developed more than three decades ago.
For most of that time, InfiniBand networking has also been concerned with driving down latency well below what Ethernet or other protocols could deliver — through the use of Remote Direct Memory Access, or RDMA, technology — as well as providing additional capabilities such as full transport offload, adaptive routing, congestion control, and quality of service for workloads running across a network of compute engines.
This relentless pursuit of higher bandwidth and lower latency has served InfiniBand well, and must continue into the future, but its ongoing evolution depends on many other technologies working in concert to deliver more scale, the lowest possible application latency, and more flexible topologies. This stands in contrast to the first 15 years or so of InfiniBand technology, during which sufficient innovation was attained simply by driving down port-to-port hop latency within the switch or latency across a network interface card that links a server to the network.
As bandwidth rates increase, forward error correction needs to compensate for higher bit error rates during transmission and this means that latency across the switch will stay flat — at best — and will likely increase with each generation of technology; this holds true for any InfiniBand variant as well as for Ethernet and indeed any proprietary interconnect. So, latency improvements must be found elsewhere in the stack.
Furthermore, work that has traditionally been done on the host servers in a distributed computing system needs to be moved off the very expensive, general purpose CPU cores where application code runs (or manage the code offloaded to GPU accelerators) and onto network devices. The devices could be the switch ASIC itself, the network interface ASIC, or a full blown Data Processing Unit. That DPU is a new part of the InfiniBand stack, and it is important in that it can virtualize networking and storage for the host as well as running security software without putting that burden on the host CPUs.
The combination of all of these technologies and techniques will keep InfiniBand on the cutting edge of interconnects for HPC, AI, and other clustered systems.
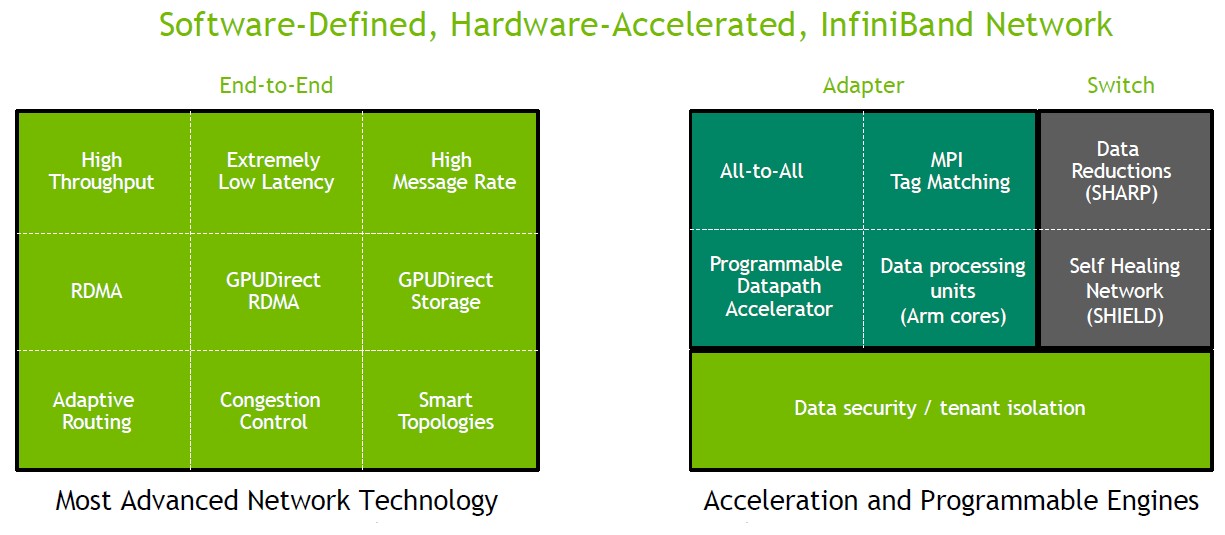
“If you look at InfiniBand, it gives us two kinds of services,” Gilad Shainer, senior vice president of networking at Nvidia’s Networking division, explained in an InfiniBand Birds of Feather session at the recent International Supercomputing Conference. “It gives us the networking services, which have the highest throughput out there, running at 200 Gb/sec for more than two years now, and moving to 400 Gb/sec later this year. In addition, it provides computing services via pre-configured and programable In-Network Computing engines.”
Mellanox, which was acquired by Nvidia in April 2020, was the first significant commercial player to bring InfiniBand to the high performance computing sector. The InfiniBand roadmap at the company goes back to the early days of 2001, starting with Mellanox delivering 10 Gb/sec SDR InfiniBand silicon and boards for switches and network interface cards.
This was followed up with DDR InfiniBand, running at 20 Gb/sec, in 2004, also marking the first time Mellanox sold systems as well as silicon and boards. In 2008, the speeds doubled up again to 40 Gb/sec with QDR InfiniBand, which was also when Mellanox got into the cable business with its LinkX line.
In 2011, the speeds were boosted a bit with 56 Gb/sec FDR InfiniBand, and Mellanox expanded into fabric software. In 2015, 100 Gb/sec EDR InfiniBand debuted, followed by 200 Gb/sec HDR InfiniBand in 2018, which included in-switch HPC acceleration technologies for the first time. (The ConnectX adapter family had been doing network offload from host servers for a long time.)
Looking ahead, the speed bumps for the InfiniBand spec, and therefore for InfiniBand suppliers like Nvidia that implement the spec after they are released, are looking to be more regular than they had been in the middle years of the 2000s.
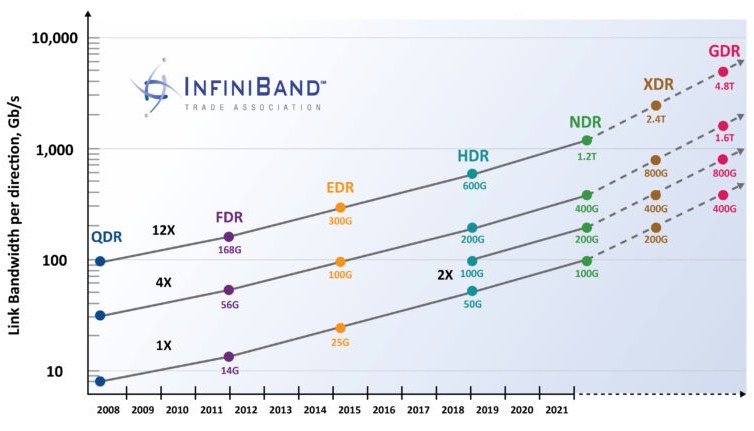
With HDR InfiniBand, customers are able to either increase the bandwidth on the ports to 200 Gb/sec by ganging up four lanes with an effective speed of 50 Gb/sec or to double the radix of the switch ASICs and run the ports with only two lanes and have each port remaining at the same 100 Gb/sec speed as EDR InfiniBand. (This is implemented by Nvidia in the Quantum InfiniBand ASICs, which were unveiled in late 2016 and which started shipping about a year later.) By doing this radix extension, customers who do not need higher bandwidth can flatten their networks, eliminating hops in their topologies, while at the same time eliminating some switching. (And it is interesting to think about how a 400 Gb/sec ASIC might have its radix doubled again to create an even higher radix switch as well as ports running at 200 Gb/sec and 400 Gb/sec speeds.)
The next stop on the InfiniBand train is NDR, with 400 Gb/sec ports using four lanes — and what Nvidia is implementing with its Quantum-2 ASICs. These Quantum-2 ASICs have 256 SerDes running at 51.6 GHz with PAM-4 encoding and have an aggregate bandwidth of 25.6 Tb/sec uni-directional or 51.2 Tb/sec bi-directional, able to process 66.5 billion packets per second and deliver 64 ports at 400 Gb/sec.
Following this on the InfiniBand roadmap is the XDR speed, delivering 800 Gb/sec per port, and the final stop projected out — there will undoubtedly be more — is 1.6 Tb/sec using four lanes per port. The latency will probably creep up a bit with each jump on the InfiniBand roadmap because of forward error correction, but Nvidia is adding other technologies that mitigate against that increasing latency. Equally importantly, Ethernet will be subjected to the same forward error correction and will see port latencies also increase, so the gaps in latency remain more or less the same between InfiniBand and Ethernet.
As far as Shainer is concerned, the right side of the block diagram above — the side that deals with network services — is more important than the left side dealing with the increasing capacities and capabilities of the raw InfiniBand transport and protocol.
“The more interesting thing is putting compute engines in the silicon of the InfiniBand network, either in the adapter or the switch, to allow the application to execute as the data moves within the network,” he says. “There are engines that are preconfigured to do something very specific, such as data reductions, which normally would be done on the host CPUs. Data reductions are going to take more and more time as you add more and more nodes — more data, more data in motion, and a lot of overhead. We can migrate all the data reduction operations into the network, enabling flat latency in a single digit microsecond regardless of system size, reducing data motion, reducing overhead, and delivering much better performance. We also have MPI tag matching engines and all-to-all engines performing at wire-speed for small messages at 200 Gb/sec and 400 Gb/sec speeds.”
These in-network accelerations began in the ConnectX adapter cards, accelerating certain portions of the MPI stack. And with the Switch-IB 2 ASICs for EDR 100 Gb/sec InfiniBand, a second generation chip running at that speed announced in November 2015, Mellanox added support for what it calls Scalable Hierarchical Aggregation Protocol, or SHARP for short, to do data reductions inside the network.
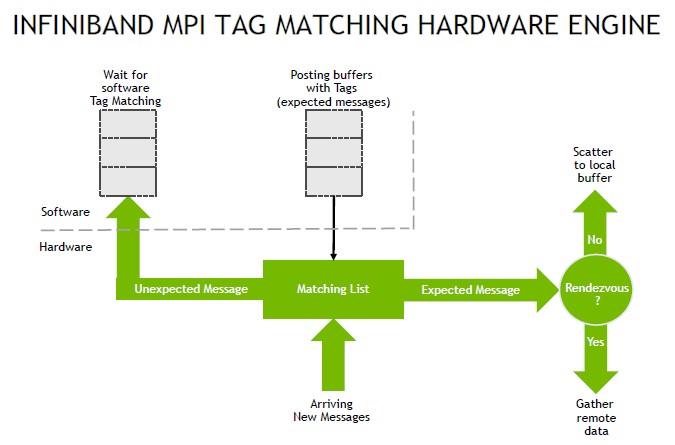
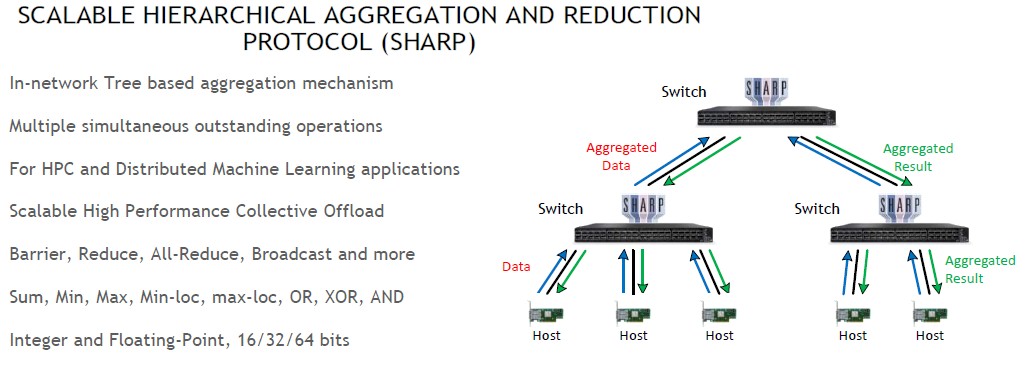 This capability was specifically developed for the “Summit” supercomputer at Oak Ridge National Laboratory and the “Sierra” supercomputer at Lawrence Livermore National Laboratory, which started going into the field in late 2017 and which were fully operational in 2018. Since that time, Mellanox (and now Nvidia) have been expanding the in-network functions adding all-to-all and MPI tag matching to the data reductions. Here is how MPI tag matching works:
This capability was specifically developed for the “Summit” supercomputer at Oak Ridge National Laboratory and the “Sierra” supercomputer at Lawrence Livermore National Laboratory, which started going into the field in late 2017 and which were fully operational in 2018. Since that time, Mellanox (and now Nvidia) have been expanding the in-network functions adding all-to-all and MPI tag matching to the data reductions. Here is how MPI tag matching works:
More and more functions are being accelerated in the InfiniBand switches, and with the NDR 400 Gb/sec Quantum 2 switches, the ConnectX-7 adapters, and the Nvidia SHARP 3.0 stack, even more in-network processing is being done. And with the advent of the Nvidia BlueField 3 DPU, which will itself have five times more compute capacity than the BlueField 2 DPU it replaces, Nvidia will be able to accelerate collective operations, and offload active message processing, smart MPI progression, data compression, and user-defined algorithms to the Arm cores on the BlueField 3 DPU, further unburdening the host systems.
What matters is how this all comes together to boost overall application performance, and DK Panda of Ohio State University is, as usual, pushing the performance envelope with his MVAPICH2 hybrid MPI and PGAS libraries and is running performance tests on the “Frontera” all-CPU system at the Texas Advanced Computing Center at the University of Texas. For those who are unacquainted, here is the MVAPICH2 stack:
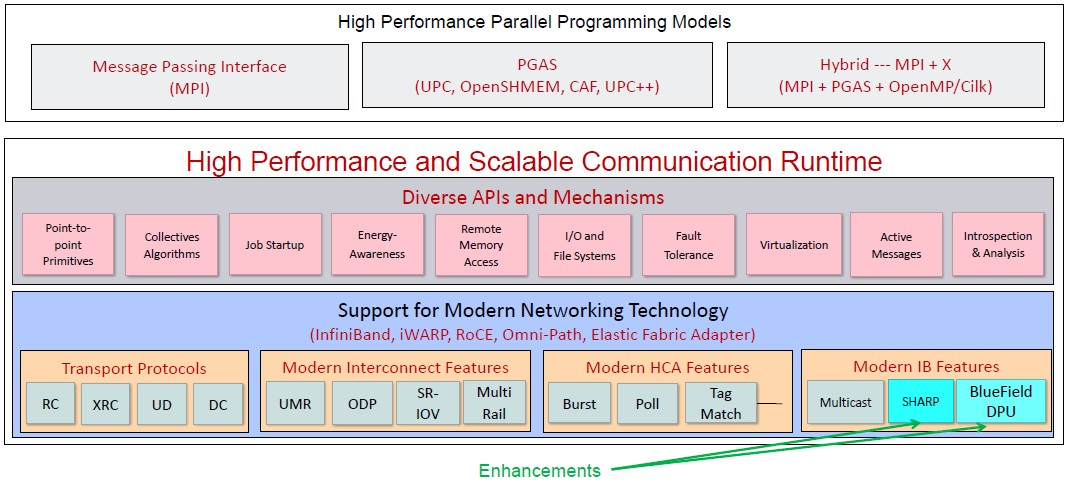 The performance increases with the Nvidia SHARP running in conjunction with the MVAPICH2 stack are significant. With SHARP running in conjunction with MVAPICH2 with the MPI_Barrier workload on the full Frontera system with one process per node (1ppn in the chart below), the scaling is nearly flat (meaning latency is not increasing as node counts go up) until the 4,096 node barrier is crossed, and even at the full system configuration of 7,861 nodes, the latency is still a factor of 9X lower. If you turn off SHARP on the same machine, the latency creeps up exponentially as the node counts rise. With 16 processes per node (16ppn), the latencies are smaller and the difference between having SHARP on and off is only a factor of 3.5X across 1,024 nodes. Take a look:
The performance increases with the Nvidia SHARP running in conjunction with the MVAPICH2 stack are significant. With SHARP running in conjunction with MVAPICH2 with the MPI_Barrier workload on the full Frontera system with one process per node (1ppn in the chart below), the scaling is nearly flat (meaning latency is not increasing as node counts go up) until the 4,096 node barrier is crossed, and even at the full system configuration of 7,861 nodes, the latency is still a factor of 9X lower. If you turn off SHARP on the same machine, the latency creeps up exponentially as the node counts rise. With 16 processes per node (16ppn), the latencies are smaller and the difference between having SHARP on and off is only a factor of 3.5X across 1,024 nodes. Take a look:
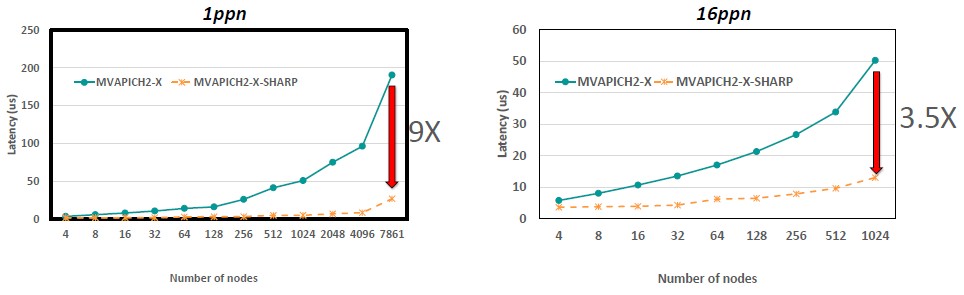
On MPI_Reduce operations, the performance benefits of SHARP range from a low of 2.2X to a high of 6.4X, depending on the node count and the processes per node. MPI_Allreduce operations range from 2.5X to 7.1X, again depending on the node counts and processes per node.
On a separate set of benchmark tests, adding a BlueField-2 DPU to the system nodes and having it help with MPI offload on a 32-node system with either 16 or 32 processes per node, the performance benefit ranged from 17 percent to 23 percent on a range of message sizes from 64K to 512K, like this:
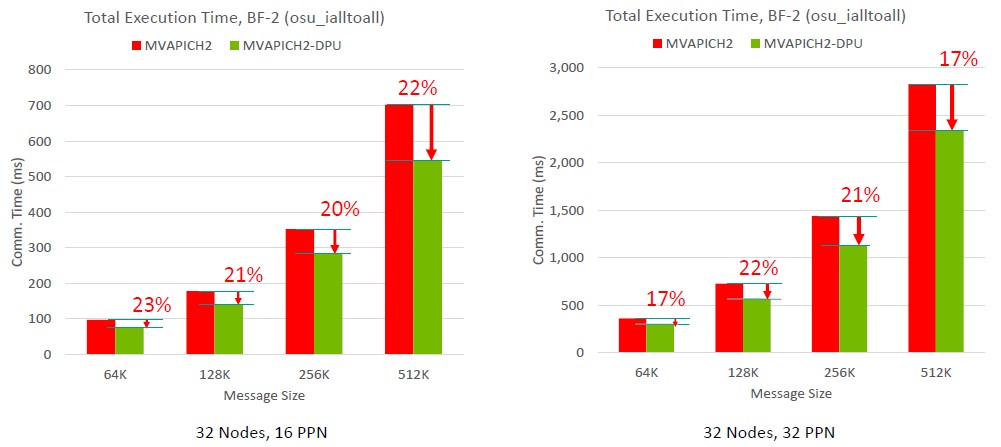 These performance benefits — in the adapters and in the switches and in the DPUs where they are present —are cumulative and should significantly improve the performance of HPC and even AI applications that depend on MPI operations.
These performance benefits — in the adapters and in the switches and in the DPUs where they are present —are cumulative and should significantly improve the performance of HPC and even AI applications that depend on MPI operations.
And that is why, when you add it all up, it is reasonable to assume that InfiniBand will have a long and prosperous life ahead in HPC and AI systems.
This article is sponsored by Nvidia.


Dell Tackles AI Infrastructure With Disaggregated Servers And Storage
It is funny how companies can find money – lots of money – when they think IT infrastructure spending can save them money, make them money, or do both at the same time. This is the hope with AI, and everyone is trying to benefit from it in those ways. …
Supermicro Hiccups On Hopper, Pulls $40 Billion Guidance For Fiscal 2026
Nvidia co-founder and chief executive officer Jensen Huang did not do his OEM and ODM partners, who are the company’s main route to bring the infrastructure underpinning GPU systems to market, any favors when he suggested its “Hopper” GPU platforms would be blown away by their “Blackwell” kickers. But, Huang …
Building The Perfect Memory Bandwidth Beast
If memory bandwidth is holding back the performance of some of your applications, and there is something that you can do about it other than to just suffer. You can tune the CPU core to memory bandwidth ratios by picking your chips wisely, and you can lean on chip makers …
Infiniband, for all intents and purposes is as proprietary as and other protocol which is supported by one and only one vendor