

Imagine what it would take to ship over one petabyte per week from one datacenter to another. The matter of time and cost is only one angle, it takes manual intervention to assemble and manage large transfers.
Massive data transfers have always been a challenge for the national labs, especially since some grand-scale scientific computing problems are often divvied up between facilities or moved to be closer to unique HPC resources. However, with the exascale age dawning and data volumes continuing to grow, getting data between the labs has become a priority.
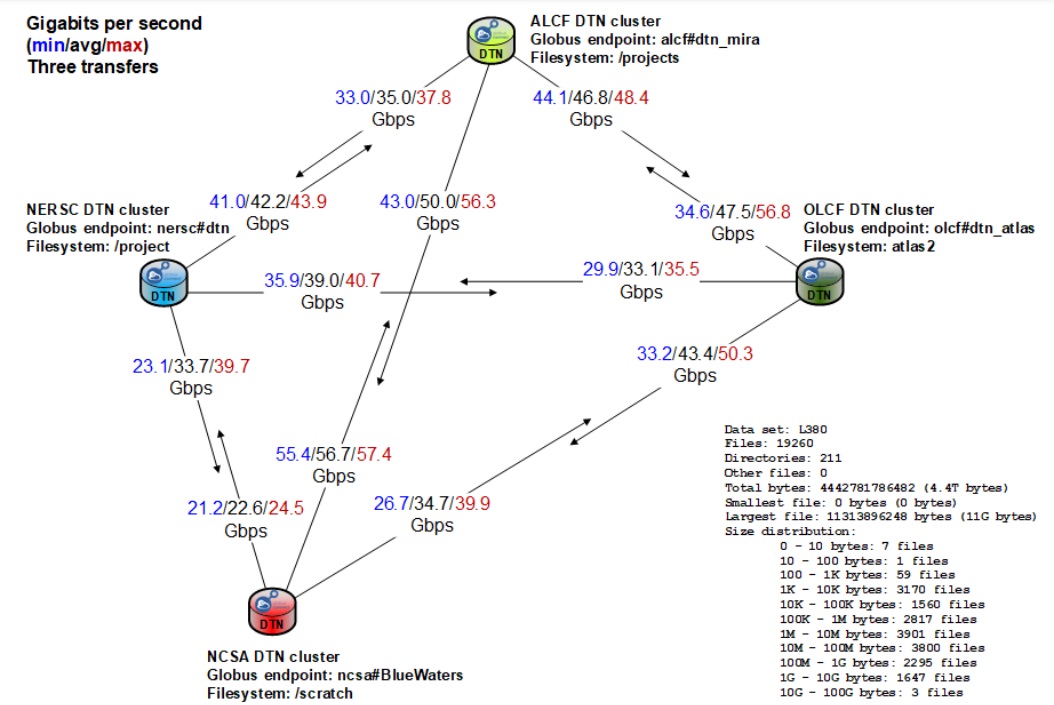
Currently, the 100Gb/s ESnet has been the backbone for shuttling multi-terabyte data between the labs via direct connections but for the largest simulations in cosmology and other data-intensive HPC areas, even this network would be stretched. A collaboration emerged to try to get to the petabyte-per-week target, called the Petascale DTN Project, driven by Lawrence Berkley, Argonne, and Oak Ridge National labs and the National Center for Supercomputing Applications (NCSA).
Roughly speaking, the collaborators say moving one petabyte per week requires around 13.2Gb/s of throughput for a week. The starting point was to achieve persistent, production-level 15Gb/s without heavy manual intervention. The key to hitting this mark was through uniquely configured data transfer nodes (DTNs) within the wider site networks along with an eye on how those interface with parallel file systems.
“For large HPC facilities it is incredibly valuable to deploy a cluster of DTNs in a way that allows a single scalable data transfer tool to manage transfers across multiple DTNs in the cluster. By explicitly incorporating parallel capabilities (e.g. the simultaneous use of multiple DTNs for a single job) into the design, the external interface to the HPC facility storage system can be scaled up as needed by adding additional DTNs, without changing the underlying tool. This combination of a scalable tool and a scalable architecture is critical as the HPC community moves towards the Exascale era while at the same time increasing the number of research projects that have large-scale data analysis needs.”
What is particularly interesting about what the labs have done is that it is generalizable. The same approach can be transferred to smaller centers to allow faster, less demanding large-scale data transfers and further, would allow them tighter connection with the largest national labs.
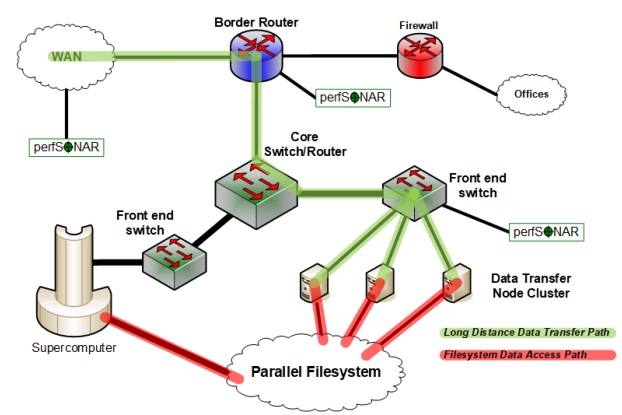
DTNs are the hub point where the data transfers happen (in other words, they don’t move directly to/from the file system). These servers are the external interface to the file system and read/write then move files to/from the network at high speed. DTNs have their own file system connected to the storage fabric which keeps the biggest objects on the parallel file system.
When making huge transfers with the target one petabyte per week rate, the only manual handling happens with the DTNs, which runs the data transfer application and moves data between facilities. All of this takes the complexity out of moving directly into the parallel file system and no HPC compute nodes need to be tuned or optimized for the transfers. The DTNs handle it all and can be configured per user or workload.
“Tuning individual components (e.g. filesystem mount performance, long-distance network performance) is necessary but not sufficient. Ultimately everything must work together – filesystem, DTNs, network, and data transfer tool – in a way that consistently achieves high performance for the user community, in production operation, without constant troubleshooting,” the Petascale DTN team explains.
It sounds simple when put this way but it’s taken the labs a long time to get to more seamless high-speed transfer rates for large datasets. Manual tuning and configuration to meet different environments, including Ethernet to Infiniband, for instance, is much easier. The real trick was getting the DTNs to play nice with file systems, which is where much of the real value is in the Petascale DTN project. Many of the sites have different parallel file systems in addition to a mix of Ethernet and Infiniband. This still takes some manual tuning but it’s a far cry from the labor-intensive work of configuring for each new transfer.
“While it is critical to have a system design that can scale to the levels required to meet the science mission, human time and attention are precious resources – the tools presented to users must make them more productive, not less. The ability to easily initiate a transfer and then allow the tools to manage the transfer without direct human intervention is incredibly valuable, and is a key contributor to the scale at which scientists will be able to do data analysis as data sets grow ever larger.”
More details about the Petascale DTN effort as well as benchmarks and experimental transfers can be found here.

Be the first to comment