

Antonio Peña, senior researcher at the Barcelona Supercomputing Center, and his team in Spain have demonstrated how – without code modification – large data centers can increase application performance while saving megawatts of power per day plus run 100X to 10,000X larger AI inference jobs that can handle encrypted data.
“Our team is investigating how HPC applications and production computing environments can expand beyond the power and capacity limits of current DRAM technology,” says Peña. “Ideally, this means we have to achieve our results without modifying the application source code and even when running binary-only applications.”
The no code modification approach makes BSC framework extremely attractive because the reported runtime and power savings can be achieved by staff at individual cloud, enterprise, and HPC datacenters.
Intel Optane persistent memory, or PMEM for short, is based on 3D XPoint memory and is installed alongside DRAM DIMMs on the memory bus to create a two-level memory architecture. Using runtime library redirection, production HPC jobs can selectively allocate memory in hot-tier fast or warm-tier capacity memory:
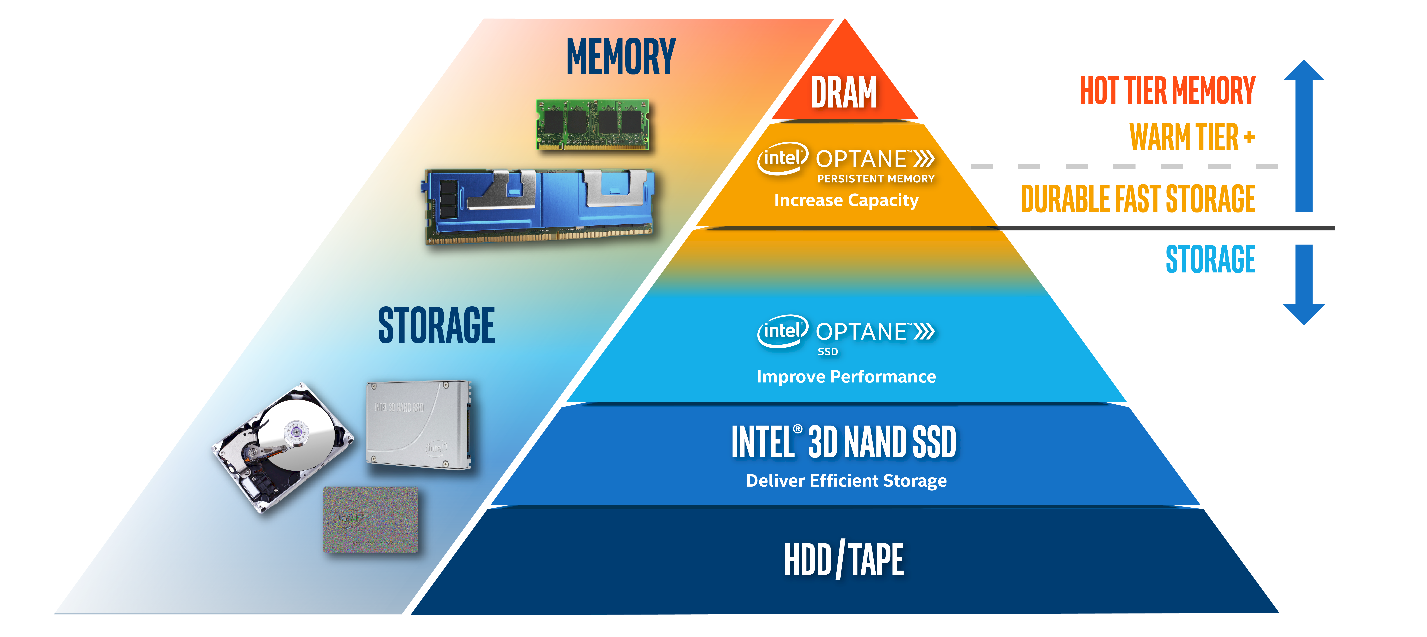
The fastest is the hot tier DRAM DIMMs. The persistent memory comprises the capacity tier which can be configured for use in two different modes: Memory Mode and App Direct Mode.
- In Memory Mode, applications only see the huge address space while DRAM acts as a cache for the most frequently-accessed data. Applications can run transparently as the cache management is handled automatically by the memory controller on the Intel Xeon Scalable processor.
- In App Direct Mode, the address spaces for the persistent memory and DRAM are separated allowing the software to decide which memory utilize. While this mode requires software changes, it also offers an opportunity for optimizing the placement of the data-objects according to their access patterns and frequencies.
App Direct Mode: Faster Application Performance And Power Savings
In a groundbreaking App Direct Mode study, the BSC team demonstrated they could increase application performance by intelligently placing memory objects for fast retrieval in the fast memory tier but keeping the not-so-frequently used memory objects in the warm-memory capacity tier. Specifically, they showed that a two-tier memory system using Intel Optane PMEM could achieve an 18 percent increase in OpenFOAM performance and a 10 percent increase in LAMMPS performance while also saving 3 watts of power per DIMM compared to DRAM.
The BSC study is game changing as it is the first to show how an innovative set of tools can enable large, production HPC applications to use App Direct mode without program modification and without paying a performance penalty. The caveat is that the binary executable has to contain the debugging symbol table as these power and runtime savings are achieved in software through the use of library redirection and call stack information to precisely identify memory objects during runtime.
The HPC community now has a proof point that establishes that the controlled placement of data object on Intel Optane persistent memory is a desirable general-purpose production capability.
The BSC results are based on first generation Optane 100 series DIMMs. Peña believes: “The next generation of Intel Optane PMEM devices promise to deliver even better performance and greater power savings.”
In particular, Intel reports that it has optimized the performance of the second generation Optane 200 series for the third generation of Xeon SP processors. According to Intel, the Optane 200 series now delivers on average 25 percent more memory bandwidth and operates with a 12 watt to 15 watt TDP compared to the 15 watt to 18 watt TDP of the earlier devices.
The impact of the BSC study will be seen in how it affects the provisioning of Intel Optane PMem devices relative to DRAM in future hardware procurements.
From all appearances, and acknowledging that this is an early study, this approach should receive widespread adoption by the HPC community because the reported runtime and power savings can be achieved by datacenter staff without modifying the application source code and even when running binary-only applications! This makes the BSC software framework a valuable cost savings tool that can be applied internally by individual datacenters on a case-by-case basis.
The execution flow of the BSC profiling and library interposition approach to intelligently allocate objects in the two memory tiers is illustrated below:
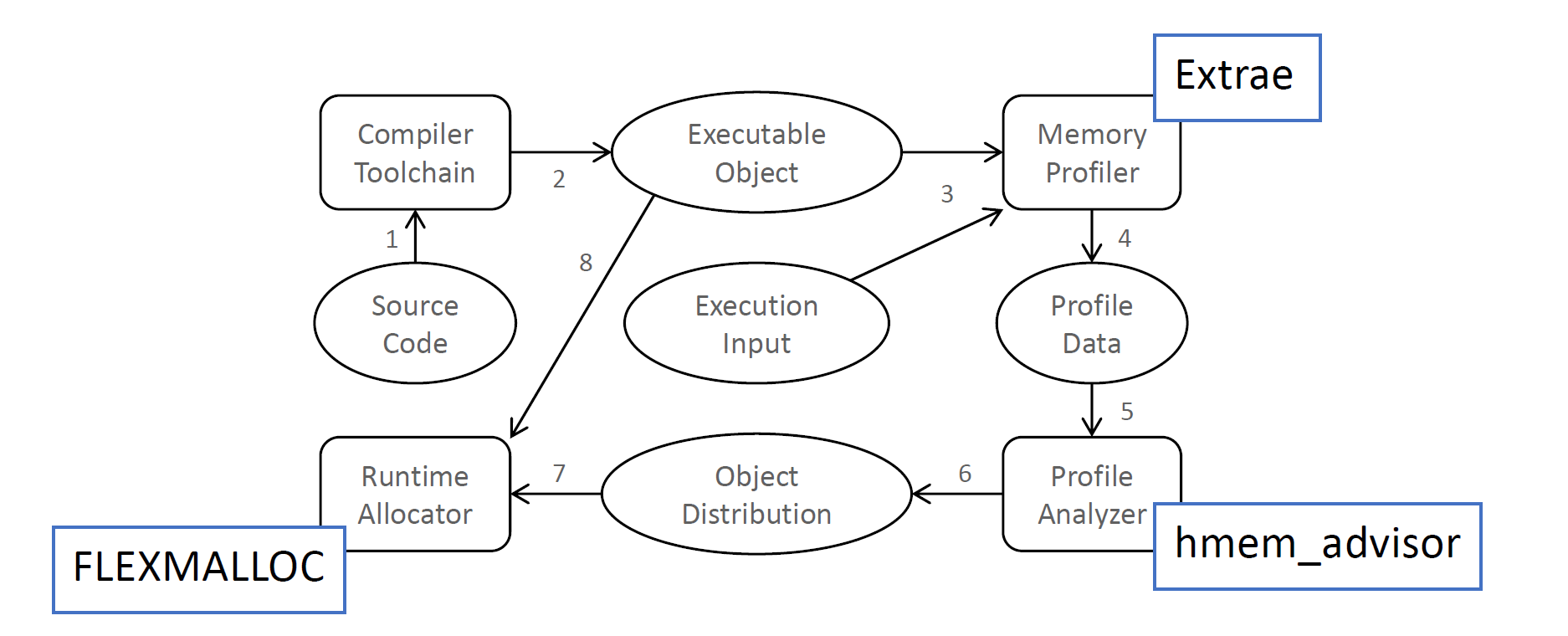
The key steps in the methodology are:
- Profile to determine per-object last-level cache misses and average access times.
- Assess the optimal distribution of the objects between the two memory tiers.
- Execute the binary calling the interposition library (via library redirection) to automatically place objects in the appropriate memory tiers.
The profiling phase consists in two parts. First, symbol interposition is used during runtime to intercept calls to memory allocation routines such as malloc(), realloc() and free() in order to identify memory objects through their call-stack. Second, PEBS sampling (Precise Event Based Sampling) is used to identify which memory addresses are being requested by the application. After matching the memory objects and quantifying their references, this information is analyzed by hmem_advisor which identifies which memory objects should be placed on which memory tier. The results from hmem_advisor are passed to FlexMalloc so it allocates memory objects in the specified memory tiers in subsequent runs.
The BSC team used the BSC Extrae profiler and Paraver analysis in the study. Harald Servat, an application engineer at Intel, notes that Intel VTune can also provide the input for the memory analysis but at this time hmem_advisor needs to be updated to read the Intel VTune data.
FlexMalloc, created by by Servat, is an interposition library that forwards heap memory operations based on the hmem_advisor distribution on a hybrid memory tier system. “The advantage of FlexMalloc using App Direct Mode is that data can be placed in specific memory tiers, such as Optane PMEM, without any application change,” Servat says.
This initial study focused on the static analysis of large, complex HPC applications such as OpenFOAM and LAMMPS although the BSC approach also worked with smaller applications such as the Intel Distribution for HPCG, Lulesh, miniFE, and SNAP. Servat observes: “Extending the whole framework with dynamic analysis is possible and slated for future work.”
Megawatts Per Day Power Savings
Peña estimates that DRAM memory currently consume 25 percent of the power in a large supercomputer, which means the power savings reported by the BSC team can be huge, potentially be measured in megawatt-hours on a large exascale system.
This assertion will be put to the test on Aurora, the US exascale supercomputer to be located at Argonne National Laboratory.
Specifically, Aurora has a power budget of 13 megawatts that will run more than 50,000 servers containing an aggregate memory capacity of more than 7 petabytes that will consist of a mix of DRAM and persistent memory. Shifting the provisioning of even one pair of DRAM DIMMs to Intel Optane PMEM modules across 50,000 servers will enable a power savings of 0.3 megawatts per hour (that is, 2 DIMMS x 50,000 servers x 3 watts saved per hour = 300,000 watts saved per hour). This will result in a savings of 7.2 megawatts of power over each 24 hours of operation. The reduction in cooling load should provide additional savings.
Similar savings are also possible given the scale of modern HPC and hyperscale data centers plus newer persistent memory modules should deliver an even greater power savings.
Memory Mode: Orders Of Magnitude Larger AI Inference Codes
In a related study, Peña was able to “break the DRAM size wall for DNN Interference” using the memory mode of Intel Optane PMem DIMMs to address privacy concerns in the data center.
The approach uses homomorphic encryption, a form of encryption that allows one to perform calculations such as neural network inference operations on encrypted data. Eliminating need for decryption provides an extra level of security as hackers never have the opportunity to access decrypted data, or the keys to decrypt the data, even if they succeed in breaking into the datacenter. The BSC team will present this work during the October 13-16 online Texas Advanced Computing Center (TACC) IXPUG annual meeting.
Peña’s work shows that inference operations with large models are possible using homomorphic encrypted data, but doing so can incur a 100X to 10,000X runtime and memory overhead.
To overcome the memory capacity limitations, Peña used persistent memory operating in memory mode. This meant that the application saw the extra memory capacity, but unlike App Direct Mode, the application had no control over where data resided in the two memory tiers. Peña notes he is not certain an application will realize any power savings from the Intel Optane PMem memory tier when using Memory Mode.
To determine the performance impact, Peña compared the runtime of the largest variant of the MobileNetV2 and ResNet-50 DNNs using encrypted data on a DRAM-only baseline system and a Memory Mode configuration that populates two of the six DIMM slots on their Intel Xeon SP motherboard with the Optane persistent memory DIMMs. He found that the DRAM-only system was only able to run the MobileNetV2 inference operations 11 percent faster than the hybrid memory system in spite of the capacity tier’s lower memory bandwidth. He concluded that in this preliminary study, homomorphic encryption inference yields memory access patterns that perform well on Intel’s implementation of Memory Mode for Optane persistent memory.
The study also found that only some of the smallest tests fit within the 192 GB of DRAM memory in the fully populated DRAM-only system. Meanwhile, the extra memory capacity allowed the first ever demonstration of ResNet-50 using homomorphic encryption. The run required in 900 GB of Optane PMEM. Peña did not perform a full analysis, but observes: “Performance tools are not ready for such huge runs. Our team did a full analysis of the biggest variant of MobileNetV2, which is already a novel cased for homomorphic encryption.” Even so, he concluded that convolution-dominated models like ResNet-50 can leverage their PMEM-based systems as efficiently as their MobileNetV2 DNN example.
To perform the work, Peña used the HE-Transformer for nGraph from Intel as the HE backend to the nGraph Compiler, which is a graph compiler and runtime for artificial neural networks. This backend supports the Cheon-Kim-Kim-Son CKKS encryption scheme and relies on the simple encrypted arithmetic library (SEAL) for the implementation.
So, pioneering research at organizations such as the Barcelona Supercomputing Center is breaking the DRAM capacity and power barriers confronting current HPC applications and supercomputers. Doing so in a production friendly manner that datacenters can implement without requiring code modifications is key.
The impact can be huge as Peña explains: “Right now, HPC applications are constrained by the amount of DRAM in the nodes and cluster. They need more and more memory but adding larger and more DIMMs with the current technology is not feasible due to the power constraints on the overall system.”
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at info@techenablement.com


Prime Contracting No Longer One Of Intel’s HPC Aspirations
Intel has spent the past nine months reorganizing itself in the wake of Pat Gelsinger becoming its chief executive officer in January, including new groups and divisions and new managers for them that were revealed in June. But the fate of its HPC organization, which has been less focused than …
Altera Is Being Realistic About FPGA Compute In The Datacenter
Like many a decade ago, we were enthusiastic about the prospect of triple-hybrid systems in the datacenter. We were convinced that there was a place for CPUs, for GPUs, and for FPGAs in complex and high performance systems because each of these devices were really good at different things and …

Intel Fills In The First Half Server Pothole – And Then Some
Let’s face it. Given how poorly the server market was doing in the final quarter of 2018 and the first two quarters of 2019, we had no idea how well or poorly 2019 might end up for Intel’s Data Center Group and the server industry at large. As it turns …
Looks like a malloc optimized after profiling the application. That is, the user need to run the app twice to get the performance. Second, the profiling information might be good for one set of inputs but not good for another set. It’d be far more interesting to see the same approach but dynamically learning the best allocation without requiring profiling and adapting to the inputs used in every rub.hpc apps last enough and are repetitive enough to allow such learning. Nevertheless, it is an step in the right direction.