

Is the inclusion of specialized matrix engines in general-purpose processors truly motivated and merited, or is the silicon better invested in other parts?
Dr. Satoshi Matsuoka is well-known in supercomputing circles for taking the path less traveled and often, those roads lead to ultra-high performance and innovative thinking about co-design and how to tailor tightly around some of the world’s most pressing scientific computing problems.
In recent years, he and his teams at RIKEN and AIST have made forward-looking arguments about the rise of low-precision HPC, the suitability of unique compute, interconnect and software architectures, and most notably, have collaborated to build the Fugaku system, which is of course, far and away the world’s most powerful supercomputer as of mid-2020.
Always with an eye on what’s next, Matsuoka is thinking about 2028, which in supercomputing terms is just around the corner. We are already starting to slide into the post-Moore’s Law era of computing and by then any architectural approach they consider will have to be primed for that future. If one were to take the temperature of HPC now, it might seem like AI will become an ever-larger share of workloads over the next few years and architectures are evolving to meet that perceived demand with the addition of matrix engines. But this is putting the cart before the proverbial horse and those matrix engines, as much as they might suit AI training for image and speech, could have far less relevance to HPC than all the hype implies.
“People have been saying LINPACK is dead or at least no longer significant and when we profile our own applications there is some qualitative evidence this is true.” What is needed, he argues, is “extreme engineering” instead of architectural additions that do not represent what’s really happening with HPC workloads, which largely is less about raw compute and more about speedy, ample memory bandwidth. Even HPC architectural cornerstones like emphasized double-precision are not standing the test of time, and perhaps will not in the next few years, either, Matsuoka argues, adding that their analysis yields that double-precision is not necessarily well-utilized in many HPC codes.
So, if so many long-held norms in HPC are beginning to dissipate, where is the panacea? If anything is for certain, at least to Matsuoka and his teams who have just released extensive performance and software analysis, it is not dense matrix engines, despite all the emphasis they’ve received in papers and more recently, in architectural focus on the part of vendors.
There is a lot of hype around matrix units. It seems the whole high-end processor industry is set on heading down this matrix engine route. The result means populating dominant areas of silicon on future architectures that won’t be fully utilized and that’s a huge step backwards in terms of performance gains,” he argues. “With that said, we are not denying the utility of these units for certain applications, but we feel they’re overhyped, they’ve received too much attention, and given the false sense these are a cure for post-Moore’s Law computing but this does not present a very general purpose solution.”
“Acceleration and specialization are not just about hardware, there’s a tremendous co-design effort. But innovation should not be driven by hype, rather there should be extreme engineering judgement based on what the applications look like now and in the future; what algorithms can actually use these. All of this should be considered before making decisions about the occupancy of new features given real workloads,” Matsuoka says. He points to Intel’s Sapphire Rapids as an example of hype-driven engineering versus the kind that could pay real dividends for broader HPC. “Maybe in their second generation they’ll put high-bandwidth memory in the CPU, but why did that take so long? It’s been available for years. We think this is attributed to LINPACK, for needing higher rankings. And now they’re just thinking about dense linear algebra and not about memory or throughput or how the memory and cache can allow these vector engines to work effectively. That’s just bad engineering. If we continue like this, we’re just going to keep wasting resources.”
Jens Domke, a colleague of Dr. Matsuoka at RIKEN and AIST in Japan and focuses on HPC networks in particular, points repeatedly to the idea that the memory bandwidth constraints of near-term future HPC are the most critical bottleneck. While he agrees that there are places where dense matrix math units make sense, they certainly don’t help with the memory and data movement problems.” Even if you have some acceleration most applications can’t benefit much.” When asked if he expected the results the research team looking at the broad usefulness of matrix engines, he adds that he expected some applications would struggle with using them but they didn’t realize how little many applications actually use dense matrix multiplications. “After profiling all the applications, we realized it’s substantially lower than expected for HPC. We might have estimated this would wouldn’t be true, there is so much emphasis on matrix math when you’re a student or post-doc.”
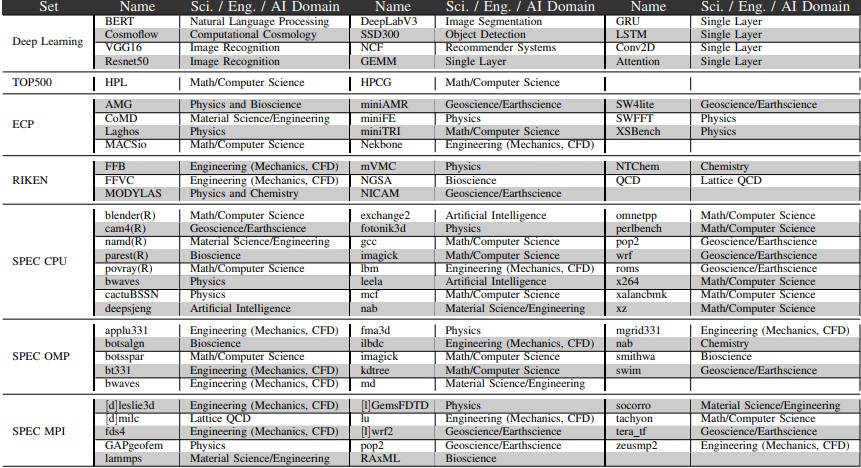
There is quite a bit of detail in the paper but we did want to carry over a couple of screen grabs to highlight the points. The first shows the applications used in the study—it’s a rather broad but diverse (in terms computational/memory requirements) set. Below that are some of the results. Note that overall, only nine out of the 77 HPC benchmarks perform GEMM operations or outsource dense linear algebra computations to libraries.
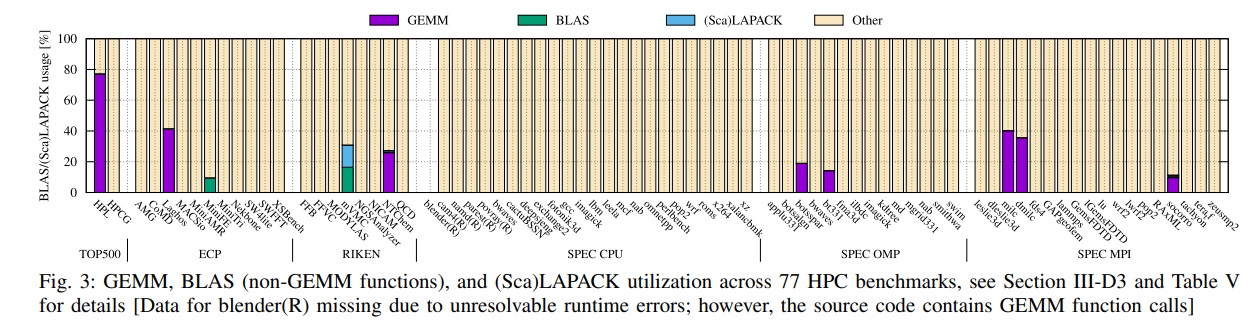
Even though the results from their analysis don’t bode well for broad HPC applicability for matrix engines, there are some promising areas where adoption might serve well, especially in supplementing traditional HPC applications, even those bound by the computational and memory requirements of physics simulations. “There are tendencies for applications to adjust to the hardware; it’s all about co-design,” Matsuoka says. “You have to basically take a very objective view but there are some fundamental principles in how applications are constructed. If you’re emulating physics directly we know only a few applications would use dense linear algebra, that’s just fundamental to physics. Now, you can make the argument that ML can emulate these physics and maybe in training can use considerable matrix operations. And still unproven—and there are some exciting applications we know of and are working in here for training, at least—where dense linear algebra operations may be effective as proxies or surrogate functions rather than first principles computing. There are various use cases for this and the results aren’t as bad as people might think, there really are ways to effectively and accurately accelerate simulations this way.”
Notice that much of the conversation has focused on training. That is, after all, where the most demanding work sits in deep learning. Even for inference, however, the proof in the matrix engine pudding isn’t there, at least not for the suite of applications they looked it. “Even for deep learning in the inference phase the amount of dense linear algebra is very small. When you try to combine HPC and ML or when you try to accelerate traditional HPC applications with surrogates, the dominant computation is on the HPC side. Whatever inference you do, whether using it to guide optimization or as supplemental extrapolation, the computation is very lightweight compared to the heavyweight HPC compute.”
Mohamed Wahib, another colleague at RIKEN and AIST who collaborated on the matrix engines analysis, says he was surprised and disappointed when reviewing the results that showed how few HPC applications could benefit.
He points to HPC’s adoption of commercial technologies, including PC and mobile chips over the years, as a hopeful sign that there is always something from the outside world that can fill an HPC niche. In this case, however, he says that he doesn’t doubt matrix engines will have broad use in ML but seeing how only a small handful of bright spots out of 70 or so applications in the study was disappointing and did not meet with what he expected to see. He is optimistic about some related insights from the work, “it is opening a discussion about programmability. While the work focuses on empirical results focused on the utilization of matrix engines in HPC, a follow-up should include a study of the programmability of the devices for a more comprehensive look at broader applicability. “Even if it’s not matrix engines, specialization is coming out way. If anything positive comes of this, it’s that it shows it time to think out loud about how we’ll actually use the specialized engines of the future.”
“We are not denying the utility of these engines, especially for training. For as long as I can remember, there’s been hype around acceleration and specialization; floating point, FFT, vector acceleration, the list goes on. Specialization isn’t new but you have to think about why, for certain cases, they haven’t been widely successful and why this time around, they might be. In the cases where there was some success it has been because of software ecosystems, performance, features that became more general purpose and baked into the processor itself as in the case of vectorization. The specialization is not just about hardware, it’s all about co-design,” Matsuoka concludes.

Compare markets: how much money can move the ~30 years old HPC (mature) market vs the “hyped” ~5 years old AI market (training + inference) in the next 5-10years? Isn’t it worth for the computing industry to focus development efforts on it? Also think in N^4 computing complexity for AI vs at best N^3 for HPC. Look where (institutions, companies, systems/individuals such as in cars, wearables, medical appliances,..) those AI systems are going (being setup and used) vs HPC systems. IMHO, it is not hype, it is plain and simple the ROI of the business. Disclaimer, I have been in HPC for 20+ years and 4+ years in AI.
So what is Matsuoka’s solution? Is there something I missed? To spend a growing percentage of the power and dollar budget on I/O each generation? Of course I/O is the problem. That’s the point of considering matrix calculations, isn’t it? That and the fact that AI already makes good use of the matrix units, and, as Joshua Mora points out above, it is going to be a larger industry than pure HPC going forward. If calculations are getting significantly comparatively cheaper than I/O perhaps you can find a way to do your calculations that, while less efficient computationally, is more efficient in terms of practical performance and power usage due to the physical constraints of the systems. Of course the current algorithms are not written that way. But, to my relatively small understanding, the problem isn’t going away, it’s only going to get worse. Matsuoka says (paraphrasing), “Look, HPC applications don’t make use of this.” Therefore what should be done? /Can/ they make use of it, and at what cost? Surely there comes a time when extra billions of dollars are being spent on all the machines each year for I/O such that it makes sense to re-factor the code. The question is, is it possible to refactor the code? I would assume that that’s why all the research is going into algorithms using matrix calculations, not because of “hype”.
When we buy a stake in a company, we invest in the future, not the past. The same thing would apply to chip architecture designs. The current 77 HPC benchmarks most likely would represent the hardware features provided by the past processors, but not the would-like-to-have features. If the processors in the past 20 years did not provide the matrix / vector instruction, how would we expect these benchmark codes have the matrix instructions? The Intel Xeon processors started to support AVX vector instructions about 10 years ago, and it is true that they have not been widely used due to the ecosystem and clock frequency drop and power consumption issues. Optimizing the BLAS, LAPACK and FFTW libs (total about 2500 functions) with SIMD instructions takes a lot of efforts — 2500 functions x variances of SIMD (AVX, AVX2, AVX512, etc.), as well as the required memory bandwidth to support the performance. HBM memory will change the data center middle-high end compute in the coming years: HBM price has been dropping from about $120/GB to about $120/16GB in 2019-2020, and TSMC said on their 2020-August Technology Day that they will be able to build SoC with 12 HBM stacks in production in 2023. With each HBM stack of 32GB-64GB & ~800GB/s, we could have an SoC with 384GB-768GB capacity & 10TB/s bandwidth in-package memory, 50X of what current 8-channel DDR4-3200 (200GB/s) memory could provide.