

Back in October 2019 when the world was normal and it felt perfectly reasonable to look forward to a slew of AI events that would showcase the newest developments from the chip startup world, we talked about Groq and its inference-oriented chip. This might make for good background reading before we dive into what the company announced today.
We noted then that Groq had been cagey about its architecture but since that time, they’ve opened up more about what they’ve built and how they might differentiate, even if the markets that seemed most in reach have shifted somewhat.
The company is now shipping cards and more important, full stacked nodes as well as their fleshed out Groqware SDK and also shed some light on their architectural decision-making in a conversation with The Next Platform today.
As you can see below, Groq is taking their SRAM approach seriously, dedicating ample silicon real estate to the 220MB. This is a key feature of their Tensor Streaming Processor (TSP) architecture, along with the purpose-build chip-to-chip links that have been central to the chip since its inception and, along with the large well of SRAM, have formed the basis of their differentiation and tuning for batch size 1—something Groq has been emphasizing from the beginning.
In moving from chips to systems, Groq has had to apply to software smarts to the problems of intelligently switching (and turning off/on) vector and tensor elements and has also had to master some tricky synchronous communication among the TSPs using a nearest-neighbor topology. The point to plentiful pin bandwidth with 512 GB/s of off-chip bandwidth 16 custom developed high-speed links across the TSPs. More on that below.
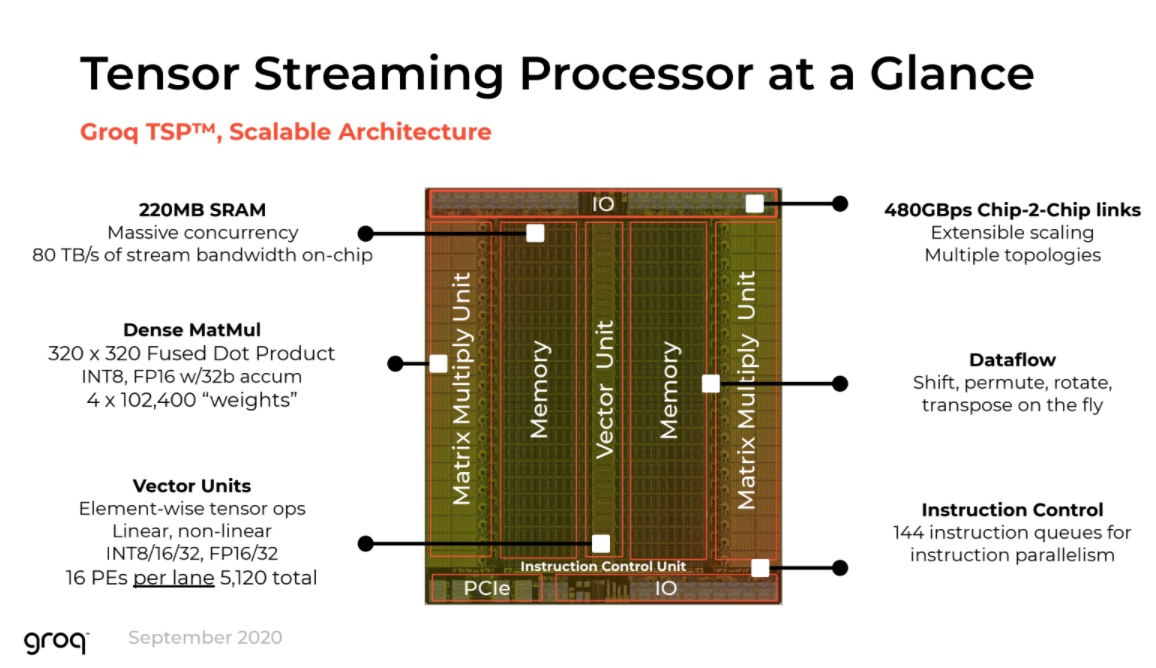
“It’s always a balance between compute, memory, and network when you’re building high performance chips—it’s all about the tradeoffs,” Bill Leszinske, who heads product at Groq, tells us. “The thing that’s different in our architecture is that we don’t have multi-level caches and multi-tiered memory so we’re able to extract more capability of that 220 MB of SRAM we have.”
“Today a lot of folks talk about how much memory they have on the die but they’ve fractured it into small blocks they can’t use efficiently (L1, L2 cache) then they have to go to memory. Other competitive architectures take a multicore approach and put a small amount of memory near the core; they can’t optimize the use that memory and have to through that to balance. We have that centralized block of SRAM, which is a flat layer that allows us to use all those transistors efficiently. That is definitely different.”
One could make the argument that to continue scaling onward to the next level of performance, however, the company will have a much steeper climb and probably an even larger chip. The rate of transistors doubles roughly every two years, for SRAM it’s more like four. This means the next iteration for Groq might mean some even more intense tradeoff conversations, but that topic is for the future. For now, it is noteworthy that Groq has been able to show scaling from chips to actual systems, as seen below.
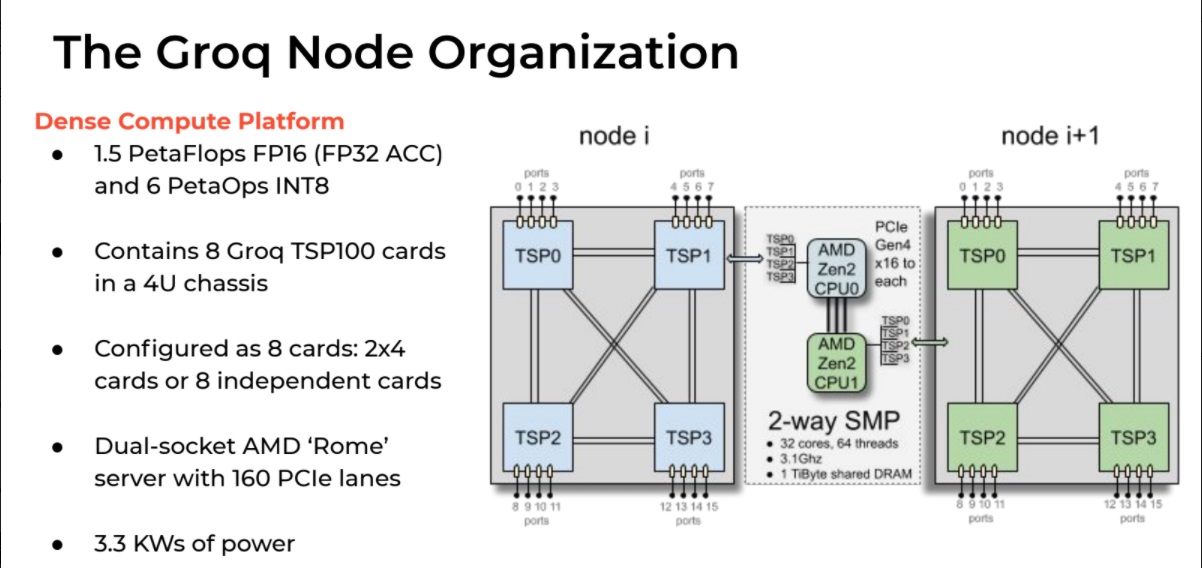
The chip-to-chip links were baked into the original design of the TSP to allow Groq to gang them up in a single box. “This is entirely unique; it is a low overhead network that doesn’t require external chips and allows, at the software level, to make multiple TSPs look like a single unit,” Leszinske says. This differs, of course, from a CPU or GPU with its multi-level caches that require duplicating data, thus avoiding losing memory to caches with their own subsets of data.
This begs the question of what the Groqware SDK sees. “Those links were architecture from the beginning. We started down the path of the SDK for one chip, then customers wanted to put multiple cards in a box. The initial customers we talked to in fintech and at the national labs had problems that went well beyond a single chip and they wanted more compute and memory and needed the TSPs together. We always planned on doing this, but just not so soon,” Leszinske adds.

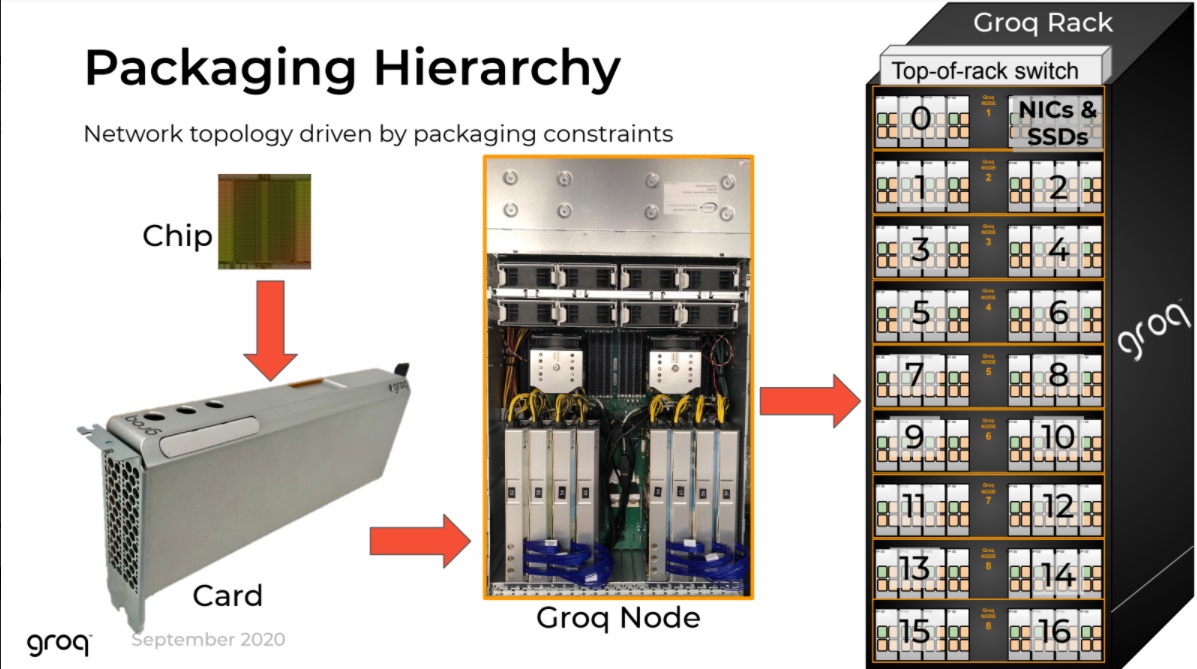
There had to be the ability to connect multiple cards, Leszinske says of the design process. “We have 16 chip to chip connects on every single component and this cards allows you to do direct connections between four of the cards but down the road we’re looking at how to make it so even more of them can be directly interconnected but this incarnation of the node, this 2X4 layout where you can use the eight cards together or independently. But each card is connected to three others, that gives the best scalability for passing weights and measures between chips.”
As part of today’s system release they also described the Groqware SDK and API, which is the interface developers will work with to spread their models across multiple chips. As hardware-oriented folks we did not spend much of our allotted time on this, although it is quite important, especially given the sophistication of Groq’s offering from a compiler and backend software standpoint with its intelligent ability to turn off idle components and cleverly route around the right computation for the moment. After all, there’s an element of compute that’s suited for more than one job baked into the TSP with tensor, vector, and dataflow capabilities that can flip on and off. On that note, we’ll point over to the piece from last year where we talked about some of this. Look under the subhead about the compiler leading the hardware horse.
In that linked overview the value of batch size 1 was emphasized as the core difference that would propel high-value areas where extreme low latency would be needed, kicking out results immediately instead of relying on batches to run through. There is clear import there for the financial services industry but for national labs, for instance, the power of Groq’s architecture might be far more in its ability to do general purpose as well as inference.
“We’ve had fintech and national lab customers who want scalability, many are focused on linear algebra and related functions and we’ve been doing a lot of work to enable that, although we have not published some of that work publicly,” Leszinske explains. “We started on inference but our first customers have pushed us to build the Groq Node server because they wanted more in a given area and wanted a box, not just cards. Also, they told us they were moving toward machine learning but linear algebra was a very high value area and they wanted to start there. So we re-prioritized.”
Leszinske adds, “While we talk a lot about machine learning and AI and that has actually been a vision for the company, we have built a general purpose architecture from the standpoint of it’s very good at different workloads…We’re Turing complete; we can do add, subtract, multiple and divide as you’d need in such an architecture but it’s not a bunch of little units optimized for machine learning or ResNet.”


Will Groq Re-Emerge to Steal AI Market Share?
With the AI chip startup hype cycle spinning down from its feverish pace in 2018, giving way to 2021 expectations for real-world deployments, it still difficult to see which company will steal what little share is left in the Nvidia/Intel/AMD dominated datacenter. The list of potential companies to grab some …

Groq Buys Maxeler For Its HPC And AI Dataflow Expertise
When it comes to application acceleration, having a deep understanding of the complex algorithms that underly most HPC and AI applications is perhaps the most important thing that can be brought to bear. And the relative handful of experts in coding field programmable gate arrays – and the hybrid compute …
Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years
If you are looking for an alternative to Nvidia GPUs for AI inference – and who isn’t these days with generative AI being the hottest thing since a volcanic eruption – then you might want to give Groq a call. It is ramping up production on its Language Processing Units, …
Be the first to comment