

Like their US-based counterparts, Google and Amazon, the Chinese Internet giants Baidu and Alibaba rely on GPU acceleration to drive critical parts of their AI-based services. At Nvidia’s GPU Technology Conference in Suzhou, China, co-founder and chief executive officer Jensen Huang revealed a couple of recent deployments that shed some light on how these two Chinese hyperscalers are using the hardware for training and inference across their vast web empires.
Baidu, China’s number one search engine, is now using Nvidia’s Tesla V100 GPUs on a single node to train its recommendation engine, replacing a large CPU cluster using hundreds of nodes. According to Huang, the GPU box was just one-tenth of the cost of the cluster it replaced.
The scope of the problem for Baidu is enormous. There are billions of products and services available to online shoppers, spread across trillions of web pages. While it’s impressive to have that level of choice, making informed choices becomes impossible without some sort of guidance that attempt to ranks your preferences. To do that, you need to create a recommendation model for each customer’s preferences as well as a model for each product or service. The intersection of the two creates a data structure with billions of dimensions.
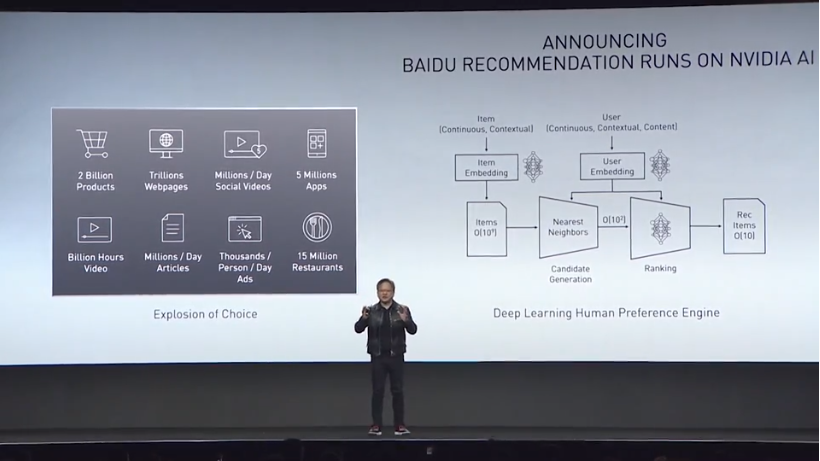
As a result, the model can exceed 10 TB in size, which is much too large to contain in the local memory of a GPU (or even several of them) and was the principle reason the original recommendation system employed a large CPU cluster using distributed memory with MPI.
Baidu’s GPU implementation is based on a model called AIBox, a deep neural network (DNN) that makes click-through rate (CTR) predictions for its online advertising system. Unlike a lot of DNN models, this one has to be retrained every few minutes, since products and services are being constantly added and dropped, while at the same time, billions of customer clicks per day are continuously modifying the preferences of users. That make training time for this application especially time-sensitive.
According to a paper on the GPU porting effort, despite the reduction in hardware and associated cost, the single node GPU-equipped system using AIBox was able to achieve “comparable training performance with a large MPI cluster.” The way Baidu dealt with the multi-terabyte data problem was by using a bi-level cache system with SSD hardware and partitioning the CTR model into two parts: one for the CPUs and one for the GPUs.
By contrast, the Alibaba GPU deployment is on the inference side, using Nvidia T4 GPUs to support its e-commerce recommendation system. However, the scope of the problem is similar to the one we just discussed for Baidu. Alibaba has a catalog of two billion products that can serve as many as 500 million customers per day. In this case though, Alibaba is using thousands of T4 GPUs across its infrastructure to support the recommendation queries on a real-time basis.
One November 11, known as Singles Day in China, Alibaba generated $38 billion in sales, which is more than twice as much as Black Friday and Cyber Monday combined. To support that level of online shopping activity, the system has to process hundreds of thousands of queries per second. With the T4 hardware, the infrastructure is now able to support a click-through rate 10 percent higher than before. “The click-through rate absolutely improved,” said Huang. “However, the computation time also improved.”

According to Nvidia, in the Alibaba model, their GPU-powered infrastructure was able to boost throughput by two orders of magnitude compared to that of a CPU. In real numbers, the T4 is able to field 780 queries per second, as against three queries per second for a (non-specified) CPU.
GPU-powered inference is not restricted to China. Nvidia lists more than 20 companies using their GPUs for inference for a range of application. These include, among others, Expedia (for content recommendation), PayPal (for fraud detection), Twitter (for content moderation, Walmart (for product analytics), and the United States Postal Service (for package sorting).
Microsoft has also adopted GPU-based inferencing to power all of its Bing search recommendations, increasing throughput by a factor of 800X, compared to a CPU setup. Perhaps more importantly, Microsoft has moved to a BERT-based model for all its Bing queries, taking advantage of the superior language capabilities of that model. As a result, Bing searches, besides being faster, are now more relevant than before.
To support that kind of capability, Nvidia recently updated TensorRT to version 7, a library for accelerating inference on GPUs, to support transformer models (like Bert) and Recurrent Neural Networks (RNNs). As a result of those updates, TensorRT is now able to support the entire conversational AI pipeline using transformer and RNN models. In addition, the new library also supports something called kernel generation, which automates the production of new RNN kernels.
At the GTC China event, Huang also spoke about DRIVE AGX Orin, their new platform for automated driving, new AI-powered genomic analysis, and autonomous machines. His entire two-hour-plus keynote can be replayed here.

Google Woos HPC Centers With Fast CPUs And Networks
The HPC centers of the world like fast networks and compute, but they are also always working under budget constraints unlike their AI peers out there in the enterprise, where money seems to be unlimited to what sometimes looks like an irrationally exuberant extent. They are also don’t have a …

AMD Hits Intel Below The Belt In The Datacenter Wallet
What Intel calls “cloud digestion” as the cause of the massive pullback in spending in its Data Center Group is looking more and more like a case of “Epyc indigestion” for Intel, not for the hyperscalers and cloud builders. And the top brass at Intel should be thanking the heavens …
With VMware, Broadcom Has A Real Enterprise Software Stack
Once Dell spun out VMware on Wall Street, it was only a matter of time before someone would put together enough money to acquire it. A year ago, we mused about Intel being the logical buyer of VMware once Pat Gelsinger left the top job at VMware to return to …
Be the first to comment