

Back in 2016, we wrote a column about the rise of data-centric computing. At the time, just a handful of companies were actually living in this world where data is collected on a massive scale and is the most valuable asset of a business – Google, Facebook, and Amazon. For these hyperscale pioneers, data is both their raw material, their end product, and it is in their DNA.
Like many, we believe this data revolution would soon spread to every industry, and we argued we needed new approaches to help businesses manage the massive volumes of data, especially unstructured data, they’d soon be grappling with.
Three years later, we are entering a Golden Age where data really does live at the center of anything and everything. Today, all manner of businesses – from life sciences to manufacturing to automotive and more – are reorienting around data-centric strategies. And the need for smarter data management is more critical than ever.
The Rising Tide Of Unstructured Data
As Mary Meeker details in her Internet Trends 2019 report, images and video are now the primary drivers of huge growth in unstructured data. Unstructured data is also driving IDC’s forecast that the “Global Datasphere” will grow to 175 zettabytes (175 trillion gigabytes) by 2025. The activities driving these trends – our still-nascent ability to systematically gather, store, and process huge volumes of unstructured data – are already reshaping industries.
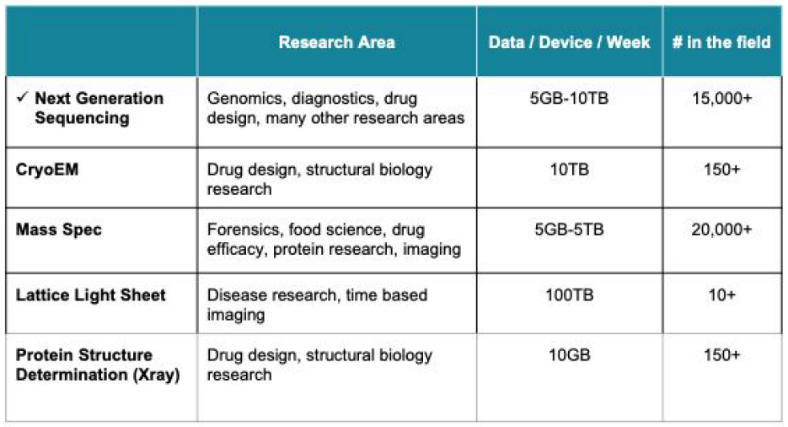
Start with life sciences. According to National Institutes of Health (NIH) statistics, collection of genomic data has exploded in the last decade, and sequencing costs have dropped at a rate faster than Moore’s Law. These trends are fueling a wide range of new research areas (see below), generating titanic amounts of data as they do. In genomics alone, tens of thousands of new devices in the field generate petabytes of new data every week.
Now look at geographic information systems (GIS): It’s now common for commercial operators to make a dozen flights a day, each generating 20 TB to 30 TB of raw data. This can include images in a variety of wavelengths and resolutions, cloud-penetrating radar, and more. Using this data and distributed computing techniques, organizations can create visualizations to answer a broad range of questions – from which electric lines in California are most likely to cause the next fire, to expected crop yields in Iowa, to the likeliest eruption points for active volcanoes in Hawaii, Indonesia, and Iceland.
Even the manufacturing sector is being affected. In this world, everything is going digital. Computational fluid dynamics (CFD) workflows, for example, allow for faster iterations on designs that, in the past, required expensive wind tunnel testing. Many of these workflows can generate more than a petabyte of raw data that needs to be stored, moved, analyzed, and operated on.
 In the automotive sector, where it is hard to separate the manufacturing operation from the services operation, a modern vehicle generates more than 10 TB of raw data per month. Businesses working on autonomous vehicles have seen their data footprint grow from tens of petabytes to hundreds of petabytes and they expect to exceed 500 PB per program in the next two years.
In the automotive sector, where it is hard to separate the manufacturing operation from the services operation, a modern vehicle generates more than 10 TB of raw data per month. Businesses working on autonomous vehicles have seen their data footprint grow from tens of petabytes to hundreds of petabytes and they expect to exceed 500 PB per program in the next two years.
Grappling With Growing Volumes Of Data
Clearly, businesses are racing headlong into the data-centric future. Too often though, they’re held back by the limitations of the past. The challenges are multifold. As unstructured data is generated at unprecedented scales, we need to be able to capture it, store it, process it, index it (so you know what you have and where it is), protect it, and move it. We also, of course, need to budget for the costs of storing and archiving it – and those costs are growing every year. (See the white paper, The True Cost of Cold Data.)
Modern storage innovations can help companies address the first several challenges listed above. The latter items, however (indexing, protecting, and moving massive volumes of unstructured data), remain elusive for many businesses.

Consider the strides made in the 20th century in the management of physical assets: Inventory control systems to tell you how many of gizmo X you have in various warehouses. Supply chain management (SCM) systems to get that gizmo from central warehouses to distribution centers to retail locations around the globe. Where is the equivalent of these systems for an organization’s data? What helps you know where your data is and how it’s changing? How do you keep track of digital assets that grow and change at the speed of modern computing? And how do you efficiently get data assets from centralized warehouses (onsite NAS stores, or cloud or edge landing zones) to where it’s needed, close to users or compute farms?
We need new management systems for businesses operating in a data-centric world. And we know the capabilities those systems should have:
- Automatically discover data everywhere it lives: Businesses need tools to scan all possible repositories of data in an efficient, nonintrusive way. (Think Google continuously scanning the entire web in the background, without impacting any sites.) This is essential to maintain an accurate picture of what you have and where it is.
- Index all data: With the cost of storage dropping faster than Moore’s Law (see cloud archival storage now available for dollars per terabyte per year), more businesses are deciding to keep all their data for a very long time, if not forever. But if you can’t find data in near-real-time, then what’s the point? Businesses need to index all unstructured data, no matter where it lives.
- Easily move data: To protect data as well as use it, you need to be able to copy and move it at will. But today, too much business data is locked up in proprietary silos. What’s needed is the equivalent of SCM for data – platform-agnostic tools to move volumes quickly from one platform to another. As with SCM, this isn’t rocket science, but there’s a lot of complexity in making sure all the moving parts work the right way at the right time. The answer: API-enabling all your data. This gives you the flexibility to select the right storage platform for each application and move volumes back and forth (such as between all-flash NAS and cloud object storage) automatically, without compromising data availability.
- Keep costs manageable: Critically, the cost of new data management capabilities should exist independent of the amount of data being acted on. Costs cannot scale with data that’s growing geometrically. To make that happen, we go back to the earlier items on this list: being able to efficiently scan, index, and move all your data.
Riding The Wave
It’s a long list of requirements. But as data becomes more central to the basic business of more organizations, these capabilities become essential. Fortunately, innovators in this space are making major strides in addressing all of these areas, so businesses can fully capitalize on their unstructured data. With these innovations, the massive wave of unstructured data can actually lift all boats, instead of scuttling them.
Kiran Bhageshpur is CEO of Igneous, the only Unstructured Data Management (UDM) as-a-Service solution. Bhageshpur was previously vice president of engineering at the Isilon storage division of Dell EMC and prior to that was senior director of engineering at Isilon Systems, where he was responsible for the development of the OneFS file system and its related clustering software

Be the first to comment