

As data grows, a shift in computing paradigm is underway. I started my professional career in the 1990s, during massive shift from mainframe computing to the heyday of client/server computing and enterprise applications such as ERP, CRM, and human resources software. Relational databases like Oracle, DB2, SQL Server, and Informix offered improvements to managing data, and the technique of combining a new class of midrange servers from Sun Microsystems, Digital Equipment Corporation, IBM, and Hewlett-Packard with storage tiers from EMC and IBM reduced costs and complexity over traditional mainframes.
However, what remained was that these new applications continued to operate on moderate amounts of structured data. Most of the time and effort was spent developing and executing consistent business logic on these relatively modest data sets. The primary value was not in the data but in the application business logic itself. During the past decade, data has grown phenomenally, and an overwhelming amount of the world’s data is unstructured data. As data has grown so has the size and scale of infrastructure required to handle these large and growing data sets.
Unlike enterprise business applications of the 1990s, systems processing this growing deluge of unstructured data have to deal with an entirely different class of problems. As data scales beyond petabytes, simply ingesting, storing, retrieving, and processing data becomes challenging using traditional server and application architectures.
 The sheer scale of infrastructure needed to support these workflows is, for most companies, daunting. There is network complexity required to support terabytes per hour data ingest rates, a large and growing storage tier, and a compute infrastructure that continuously scans incoming data to classify and process it. Businesses must tackle all of this complexity associated with the heavy lifting of undifferentiated infrastructure before they can execute the first line of code that is actually unique to them.
The sheer scale of infrastructure needed to support these workflows is, for most companies, daunting. There is network complexity required to support terabytes per hour data ingest rates, a large and growing storage tier, and a compute infrastructure that continuously scans incoming data to classify and process it. Businesses must tackle all of this complexity associated with the heavy lifting of undifferentiated infrastructure before they can execute the first line of code that is actually unique to them.
The effort of setting up scalable server, storage and networking infrastructure required to even get started far exceeds the effort to actually process the data and derive value from it.
Next Up: The Era Of Data-Centric Computing
The earliest companies to be awash with data were Google and Facebook. Faced with unprecedented data and user growth, they were forced to re-invent the entire technology stack that powers their infrastructure. They reimagined hardware platforms, ways to manage compute resources, monitor and manage data center infrastructure, route messages between applications, store data and analyze it.
Mary Meeker points out in her 2016 Internet Trends presentation (see slides 194 – 197), that current and future data growth comes from machines, including cars, cameras, satellites or phones. As with all things electronic, over the past decade, these machine based sources of data have become more powerful and less expensive resulting in an explosion in both their numbers and the volume of data produced by them.
For example, scientists and researchers are now working with a new generation of instruments that allow them to observe the world around us at a microscopic level in full motion. Needless to say, these instruments produce many terabytes of data per experiment.
The proliferation of inexpensive drones in conjunction with high resolution, multi-frequency sensors means that it is now possible to create high-resolution 3D images of physical infrastructures such as bridges, tunnels and buildings.
Not only is data now ubiquitous, it is now more valuable than ever before, serving as the basis to inform new business models and more rapid decision making. What started at Google and Facebook is now a broad trend. For a growing number of businesses, data has become the most valuable asset (“the new oil”).
In this growing world of data-centric computing, the primary value is not in the business logic but in the data itself. Consider that a competitor to Facebook could write the same business logic and remain uncompetitive because of the lack of data and the absence of an efficient infrastructure stack to handle the growing volume of data.
New infrastructure and application concepts are now emerging to address these problems of data-centric computing. Born out of necessity at companies like Google, Amazon, Facebook and Microsoft, these new patterns are becoming more relevant to a wide variety of businesses and to the enterprise data center.
Distributed Architectures
No single system — no matter how fast — can handle the large and growing scale of data and related computational needs.
The secret behind the hyper-scale public cloud providers like Amazon Web Services, Google Cloud Platform and Microsoft Azure has been their ability to scale using distributed architectures — a large number of similar systems working in concert. Improved performance and reliability comes with numbers.
The way to coordinate software running on a large number of similar systems is to ensure that each individual system is stateless and communication between them is RESTful. State is persisted on a stable storage (hard drives, flash, etc.) using REST APIs (Amazon’s S3, Google’s BigTable, and Microsoft’s Azure Active Directory). This API-driven approach abstracts the applications from the details of underlying infrastructure.
Stream Processing
Growing data sets are best processed as they arrive as opposed to in batch, at some later point in time. The latency between the arrival of new data and its processing to extract actionable information can negatively impact the value of that information.
Consider the example often highlighted in Hollywood movies depicting the prevention of terrorist acts using archives of camera feeds from multiple locations. Processing incoming feeds to identify anomalies once a day or even once an hour, results in a substantial delay in finding the bad guy leaving the suspicious bag in the crowded railway station.
This pattern of transitioning from batch processing to stream processing is what is driving the move from now traditional batch processing tools like Hadoop MapReduce toward stream processing tools like Apache Spark.
Event-Driven Computing
Back in the 1990s, relational databases introduced a radical concept called database triggers. Triggers allowed the database engine to execute custom code (stored procedures) on certain database events, simplifying application development.
Traditional storage systems hosting today’s ever-growing volumes of unstructured data lack such sophistication. Hyperscale public cloud providers have introduced the equivalent of database triggers to the world of unstructured data. Examples include Lambda from Amazon Web Services and Cloud Functions from Google Cloud Platform and Microsoft Azure.
Microservices Architecture
Microservices is the latest, much-hyped buzzword denoting the idea that distributed systems are best built using small, easily replaceable and upgradable single purpose stateless programs that communicate using RESTful protocols. As the value of applications moves from monolithic business logic to the data itself, microservices allow small pieces of code to surround the data rather than the other way around.
The ecosystem surrounding AWS Lambda provides a good example of microservices realized.
Machine Learning
With growing data sets, the best emerging ways to automagically analyze and classify their content is to use various machine learning techniques. Given large enough data sets and sufficient parallel computation resources (such as GPU farms!) to train models, modern implementations of machine learning have progressed to the point that deep content inspection and classification are now practical.
Data-Centric Computing Platforms
As data continues to grow, data-centric computing is poised to change the nature of computing and storage as profoundly as the changes caused by the shift from mainframe to client/server, or from the shift from client/server to Web.
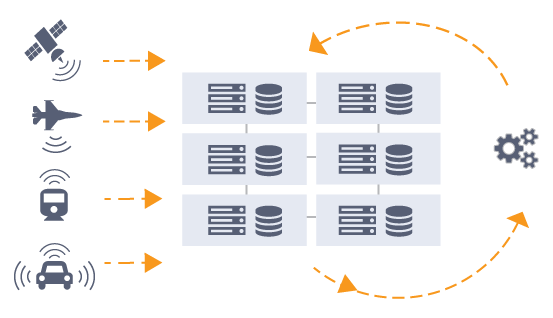
In this world, data is ingested via HTTP (ubiquitously accessible) into an intelligent platform that automatically adds relevant metadata and executes snippets of code (micro-services) to inspect and classify the incoming data on the fly. Processed and curated data is API-accessible by users and machines. Developers can realize all of this without the tedium of building, monitoring and managing complex compute, networking and storage infrastructure.
Outside of a select few businesses, the only option to instantiate such a modern, distributed infrastructure is to use the public cloud. While appropriate in many cases, moving large and growing volumes of data across Internet connections is slow, cumbersome and expensive.
If we can’t move the data to the public cloud, it only makes sense to bring the cloud to the data. The next and natural stage in the evolution of cloud services lies with platforms that bring the attributes of public cloud infrastructure to where data is generated and curated.
Kiran Bhageshpur is CEO of Igneous, an infrastructure start-up that is in stealth mode that will be revealing its datacenter management tools later this month. Bhageshpur was previously vice president of engineering at the Isilon storage division of Dell EMC and prior to that was senior director of engineering at Isilon Systems, where he was responsible for the development of the OneFS file system and its related clustering software.

Emergence emergence … IBM developped the concept in 2014 … mainfrainers have such sensitivity from the beginning. Why don’t IT people understand that a computer is made to process Data ? (Data Center – right in front your eyes !)
I agree with the assessment especially that information is the new oil analogy. Unfortunately we see a large asymmetry here it is quiet clear that internet companies have realized that very early on but consumers still haven’t realized it fully yet and are still willing giving their oil up for basically nothing. We need a stronger social movement to increase awareness and potential improve this imbalance as it exists right now.