

If this is truly the age of heterogeneous supercomputers, then the system installed earlier this month at the University of Tsukuba is its poster child. The new NEC-built machine, which is now up and running at the university’s Center for Computational Sciences (CCS), is powered by Intel Xeon CPUs, Nvidia Tesla GPUs, and Intel Stratix 10 FPGAs. Known as Cygnus, the 80-node cluster gets its name from Cygnus A, a galaxy that features twin jets of material shooting out from its center.
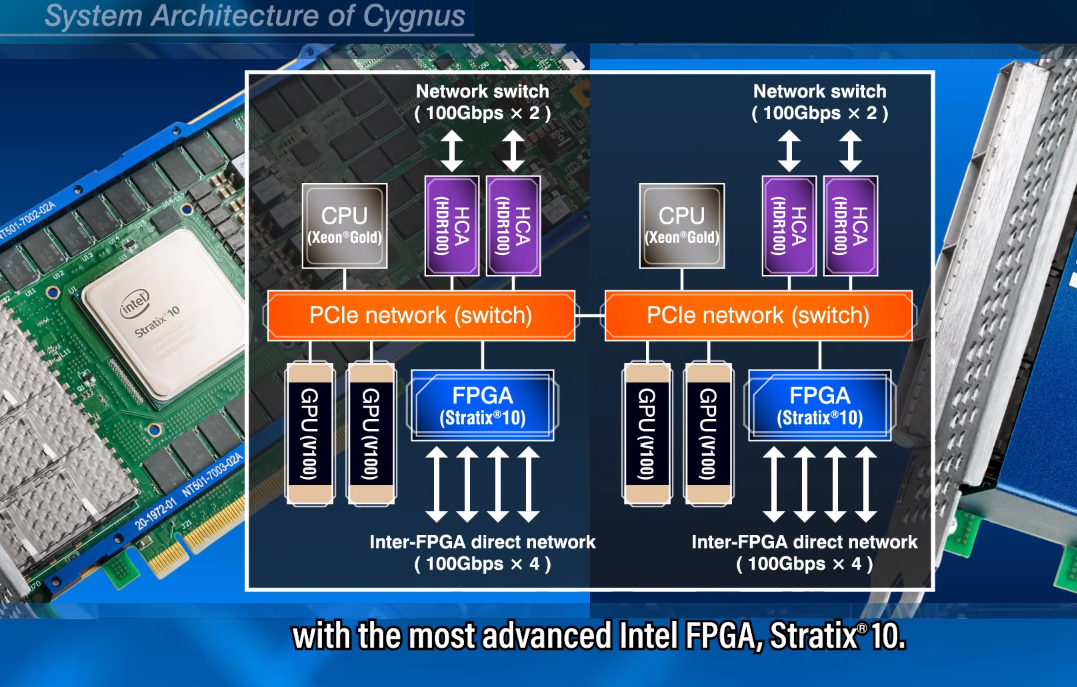
The system breaks down as follows: all 80 of Cygnus’s nodes are equipped with two Xeon “Skylake” Gold CPUs and four Tesla V100 GPUs, but in 32 of those nodes, two Stratix 10 FPGAs have been added alongside the GPUs. The 48 CPU-GPU-only nodes are called Deneb nodes, (named after the brightest Cygnus A star), while the 32 CPU-GPU-FPGA nodes are known as Albireo nodes (named after a Cygnus A double-star).
The FPGAs are provided in the form of Bittware 520N PCIe cards – a Nallatech product that got rebranded when Molex acquired Bittware last year. These are pretty heavy-duty FPGA cards, offering 10 teraflops of single precision performance, along with four banks of DDR4 memory. But it’s big claim to fame is that the card is outfitted with four 100G optical network ports – so 400Gbps – that can talk directly to other 520N FPGAs over its own fabric. In Cygnus, this capability is used to hook up the 64 FPGAs to one another in an eight-by-eight 2D torus network. Bittware includes a board support package (BSP) that makes that interface available to OpenCL developers.
 The double precision floating point performance of each Cygnus node is 30 teraflops, 28 of which are delivered by the four V100 GPUs. The two Stratix 10 devices deliver 20 single precision teraflops on the FPGA-equipped nodes. For the entire machine, that works out to 2.4 petaflops of FP64 or 5.12 petaflops of FP32.
The double precision floating point performance of each Cygnus node is 30 teraflops, 28 of which are delivered by the four V100 GPUs. The two Stratix 10 devices deliver 20 single precision teraflops on the FPGA-equipped nodes. For the entire machine, that works out to 2.4 petaflops of FP64 or 5.12 petaflops of FP32.
Cygnus is replacing COMA, a Cray CS300 cluster that was powered by Intel Xeon CPUs and Xeon Phi coprocessors, topping out at just under a peak petaflop. It was installed in 2014 and was retired at the end of March 2019 to make way for the new system.
Mellanox HDR InfiniBand is used as the system interconnect on Cygnus, and as with the standalone FPGA network, the system designers made sure they had plenty of bandwidth to play with for inter-node chatter. In this case, they used four 100Gbps HDR channels per node, wired as a full-bisection fat tree network. The InfiniBand network is also used to access a 2.5 PB Lustre file system, hosted on a DataDirect Networks ES14KX appliance.
Despite the novelty of the dual-accelerator setup, Cygnus is no testbed machine. It is meant to be a production system for scientific research in areas such as cosmology, particle physics, life sciences, and artificial intelligence. The idea behind including both GPUs and FPGAs is to use each where their respective computational strengths can best be exploited on actual science applications.
In particular, GPUs provide coarse-grained parallelism that excels at SIMD-friendly computation, whereas the FPGAs offer a fine-grained parallelism that can be more easily applied to non-SIMD algorithms. FPGAs have demonstrated speedups over CPUs, GPUs, or both, for specific algorithms used in climate simulation, bioinformatics, molecular dynamics, geophysics, and linear algebra. That said, scientific codes encompass a number of applications that can take advantage of both types of architectures.
One of the target applications for Cygnus is a simulation of the early universe that models radiation transfer from light sources. The simulation is implemented in a code called ARGOT, a package developed by CCS researchers at Tsukuba. A ray tracing algorithm known as ART (for Authentic Radiation Transfer) is a big part of this simulation, which runs better at scale on the FPGAs because the memory access patterns aren’t well-suited to SIMD. Other parts of ARGOT run better on the GPU, however, so using both accelerators turned out to be the optimal solution. The application used PCIe-based direct memory access between the GPUs and FPGAs to coordinate their work, so they avoided the latency penalty of getting the CPU involved.
The ART implementation was implemented using the relatively high-level OpenCL, which suggests other developers of scientific codes could do the same. Bittware tells us that users who compared OpenCL implementations, using their BSPs, against those strictly using Hardware Description Language (HDL), found that for many cases, the OpenCL implementation was “close enough” performance-wise.

Progress in FPGA software development over the past few years has been enough to encourage hyperscalers like Microsoft, Amazon, and Baidu to adopt FPGAs on fairly broad scale, especially for applications like machine learning inference. That’s given a boost to both Intel and Xilinx, the two major FPGA manufacturers.
However, in HPC proper, their adoption has been much more limited. Assuming, CCS submits a Linpack run for Cygnus, it will be the only FPGA-equipped supercomputer to crack the TOP500 list. Paderborn University in Germnay recently installed a more modest FPGA machine, a Cray CS500 supercomputer, called Noctua, outfitted with the 32 of these same Bittware 520N cards. That system is not equipped with GPUs and delivers about half a peak petaflop. There are also a handful of other FPGA-flavored HPC clusters strewn around at various centers, including the Nova-G# system at CHREC (now SHREC) in Florida, the Maxeler HPC-X machine at Hartree Center in the UK, and the Catapult 1 and HARP v2 clusters at TACC.
Whether that list expands depends not only on what happens at places like Tsukuba and Paderborn, but also if hyperscalers continue to drive the ecosystem from the top down. From Bittware’s perspective, the critical adoption has to come from the middle, with commercial deployments; but that segment is also dependent on better support for high-level languages and more mature development tools. The good news is that both Intel and Xilinx appear to be on the same page with regard to delivering better tools for developers and are packaging them tools with their next-generation FPGA products. Which is reason enough for some cautious optimism.


Intel To Set Its FPGA Unit Free To Pursue Its Own Path
Maybe Intel chief executive officer Pat Gelsinger has spent too much time at EMC and VMware. Because now Intel wants to spin out the FPGA business that is a small but bright spot in its datacenter and edge computing businesses. It never made a lot of sense that EMC, the …

The GPU Is The Worst – And Best – Thing To Happen To The FPGA
A decade or so before the GPU started storming the datacenter thanks to Nvidia’s Tesla GPU accelerators and their CUDA parallel programming environment and CPU offload model, FPGAs were starting to gain traction as accelerators in their own right. But because FPGAs remained difficult to program in that decade head …
Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …
That’s a cool set up.
Fpga will significantly increase cluster performance. Also it will help in more powerful edge applications.