

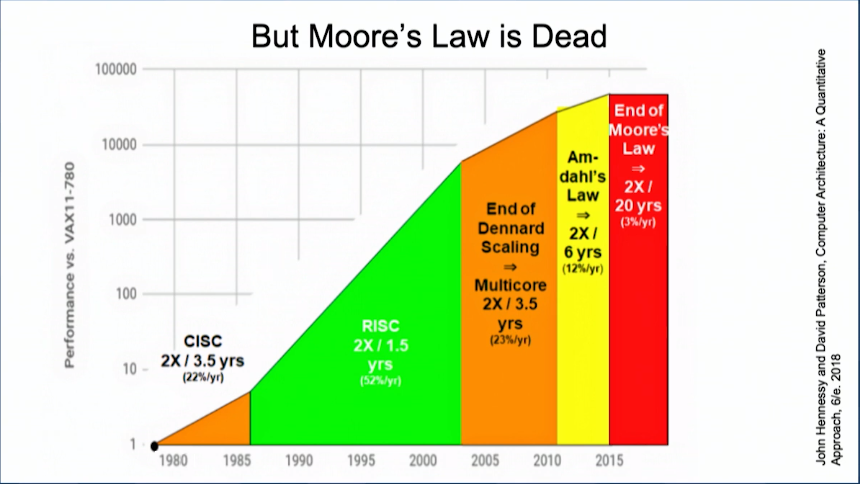
The emergence of machine learning has forced computer architects to realize the way they’ve been developing hardware for the last 50 years will no longer suffice. Dennard scaling is dead; Moore’s Law is dying; and the future of the general-purpose processor looks uncertain.
In a presentation at the Matroid Scaled Machine Learning Conference, Nvidia Chief Scientist Bill Dally talked about how his company is successfully navigating through this challenging landscape and how it plans to build on that success in the coming years.
As should now be apparent to readers of this publication, Nvidia has invested heavily in machine learning, which they (and many others) see as the cornerstone of the computer industry going forward. The technology is spreading to every sector of the economy and is poised to transform entire industries – transportation, healthcare, media & entertainment, manufacturing, and financial services, not to mention computing itself.
Dally reminded the conference audience that machine learning, and specifically deep learning, has actually been around for decades, noting that most of the underlying algorithms were developed by computer scientists back in the 1980s. At that time though, the hardware was not powerful enough run these algorithms fast enough to make them practical to use.
“The missing ingredient and spark that really ignited the fire that is the current revolution in deep learning was having enough compute horsepower to train these models on these datasets in a reasonable amount of time – people defined reasonable as two weeks,” explained Dally. “Once that happened, it took off.”
Of course, the compute horsepower Dally is referring to is now derived largely from GPUs, which Nvidia began optimizing for deep learning after 2012, post-Kepler. For all subsequent architectures: Maxwell, Pascal, Volta, and now Turing, Nvidia progressively added circuitry to their microprocessor that made training and inferencing deep neural networks faster and more energy efficient.
For training, the watershed moment came with the Volta, which saw the addition of specialized Tensor Cores. With their FP32/FP16 operations optimized for neural net number-crunching, Volta’s Tensor Cores delivered a 3X performance increase over the previous Pascal architecture in this area. The Tesla V100 GPU delivers 125 teraflops of these tensor-optimized operations, along with nearly a terabyte per second of High Bandwidth Memory (HBM) bandwidth.
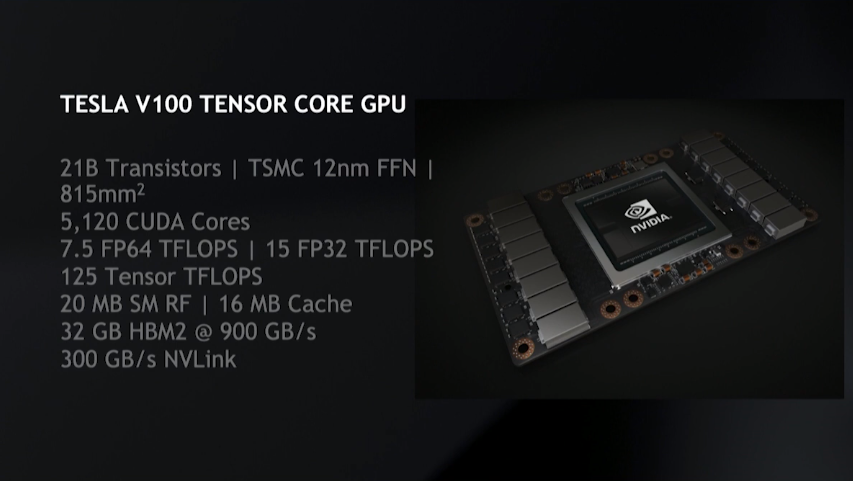
Being the good Nvidian that he is, and one who had a key role to play in the Volta design, Dally declared the V100, “the best machine on the planet for training.” He later backed that up with MLPerf numbers that showed the V100 produced the best benchmark results across all six benchmark categories that Nvidia submitted numbers for.
What Nvidia did with Volta for training, it did with Turing for inference. In this case, that meant incorporating a boatload of INT8 and INT4 capability into the Tensor Cores that could be applied to neural networks. Unlike training, inference is deployed in volume across entire hyperscale datacenters, making energy efficiency a key criterion for this technology. That level of scale also spurred Intel, Xilinx and a raft of startups to try to cash in on this opportunity with customized or semi-customized solutions, some of which are just coming to market now.

Dally claimed that the Turing-based Tesla T4 delivers better ops per watt for inference than any of the special-purpose offering, noting that Nvidia has improved its energy efficiency in this area by 110-fold over the past six years, from Kepler to Turing. “We are not a stationary target,” he laughed. For all these numerous startups out there who would like to eat our lunch, it’s a very rapidly moving lunch.”
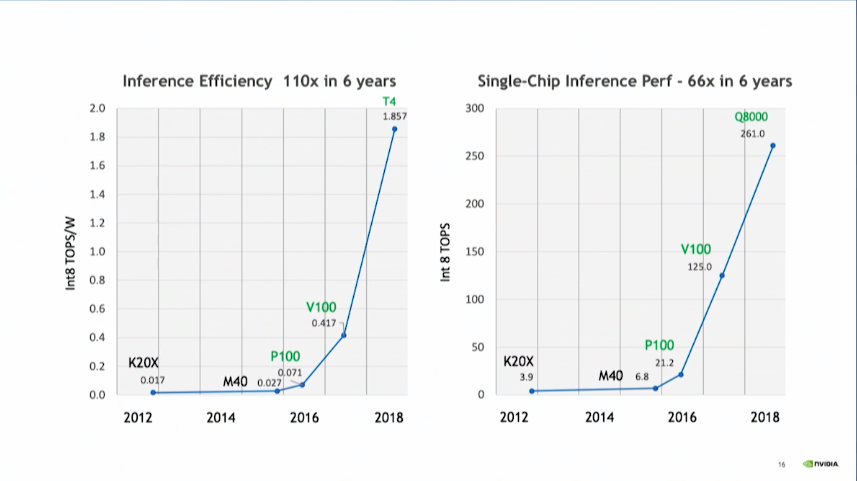 A good chunk of that increased efficiency was a result of moving to lower precision math. Since energy expended increase quadratically with the number of bits, going from FP32 to INT8 yielded a 16x boost in energy efficiency. Reduced data size also contributes to better performance, since a trained model becomes easier to fit into the smaller, faster on-chip memory, as opposed to the slower external memory. Dally said inference precision is trending down toward INT4 but he doesn’t think it’s going to get much lower than that because, for the most part, accuracy starts to suffer appreciably below four bits.
A good chunk of that increased efficiency was a result of moving to lower precision math. Since energy expended increase quadratically with the number of bits, going from FP32 to INT8 yielded a 16x boost in energy efficiency. Reduced data size also contributes to better performance, since a trained model becomes easier to fit into the smaller, faster on-chip memory, as opposed to the slower external memory. Dally said inference precision is trending down toward INT4 but he doesn’t think it’s going to get much lower than that because, for the most part, accuracy starts to suffer appreciably below four bits.
Significantly, Nvidia has not been overly reliant on Moore’s Law to keep its GPUs on these steep performance and efficiency curves. Kepler and Maxwell were built on 28 nm technology, Pascal advanced to 16 nm and 14nm, with Volta and Turing chips settling on 12 nanometers. The progression certainly helped boost flops and ops over the last five generations of chips, but the company is not depending on Moore’s Law for much more help.
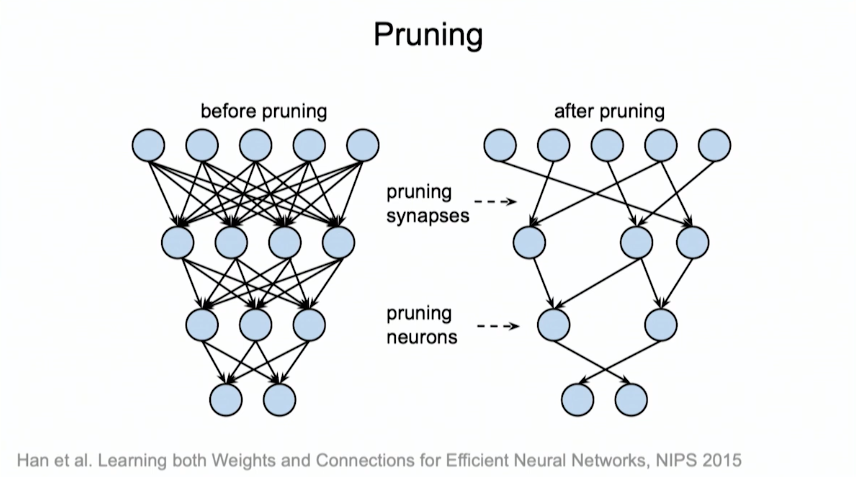
Part of it will undoubtably have to come through software advances. One of the most fruitful improvements has been network pruning, a technique where redundant or low-contributing neurons are removed from the network as the model is trained (which also happens to be the way biologic neural networks are built.) Dally said for fully connected layers, with a multilayer perceptron, or MLP, they have been able to remove 90 percent of the neurons in the network. For convolutional neural networks, he said 60 to 70 percent of the neurons can be pruned away. “You can lop out most of the neurons in a network and not lose any accuracy,” he claimed.
As much as Dally and company tout their GPUs as the king of deep learning hardware, Nvidia is also busy developing custom-built accelerators for these algorithms, trading in programmability for hardwired functions in order to squeeze out the last drop of energy efficiency. That’s especially crucial for power-constrained environments, as is the case for self-driving cars, robotics, and mobile video analytics. Nvidia has targeted these embedded applications with Xavier, the chipmaker’s SoC that is comprised of a small Volta GPU, an eight-core Arm CPU, a couple of video processors and a deep learning accelerator. Dally likened Xavier’s accelerator to Google’s custom-built Tensor Processing Unit (TPU). Although Xavier has a much small matrix multiply unit than the TPU, hardware support has been added for sparse matrices and Winograd transforms, which can help make for much more efficient processing of neural networks.
Over the last few years, Nvidia researchers have designed a number of deep learning accelerators, including an Efficient Inference Engine (EIE) and a Sparse CNN (SCNN), both of which also exploit hardwired support for sparse matrices. They’ve also came up with the RC18, a 36-die multichip module that delivers 10 teraops/watt for deep learning inference. Another technology that’s designed to minimize data movement and memory accesses has even achieved 30 teraops/watt.
As of yet, none of these have made it out of the lab, but the fact that Nvidia is exploring non-GPU designs not only says a lot about how seriously the company is taking its competition, but also how determined it is to keep the performance party going after Moore’s Law runs out of steam and it’s squeezed all the precision they can out of the arithmetic. And since that is happening sooner rather than later, you can pretty much bet a deep learning accelerator will end up in their Tesla GPU line, perhaps in the next generation.
“If we don’t continue to build faster and more efficient hardware, we will plateau; we will stagnate,” said Dally. “Because we can’t run bigger models and bigger networks without the machines to run them on.”

Watt for Watt general purpose GPUs will always be slower than FPGA, also as models and algorithm changes, FPGAs can keep adapting make inference faster.
The Edge TPU needs a minimum of 500 ma USB. Does over 4 trillion OPS.
Doubt Nvidia is in the ball park for inference. But be curious if they are close?
Edge tpu would be 500ma * 5volt = 2.5 watt, 4 trillion / 2.5 = 1.6 Tops/w Compare that with the 1.857 Tops/w for nvidia from the chart. Nvidia’s March 2019 talk claimed the worst case scenario for overhead from programmability compared to specialized accelerators like TPU was 27%. https://youtu.be/EkHnyuW_U7o?t=588 He talks about it @ 9m47s.