
OpenMP is probably the most popular tool in the world to parallelize applications running on processors, but ironically it is not a product, but rather a specification that those who make compilers and middleware use to implement their own ways of parallelizing code to run on multicore processors and now, GPU accelerators.
The latest OpenMP 5.0 spec is probably the most important update to the framework since its inaugural release way back in 1997. Some of the new features that are coming out in OpenMP 5.0 were under development for more than five years, and other features have been talked about for more than a decade, Michael Klemm, who is chief executive officer for the OpenMP Architecture Review Board and a senior staff engineer at Intel, tells The Next Platform.
The OpenMP 5.0 spec was in alpha release about a year ago with key implementers and customers, and in the summer it went into beta review to gather up broader community input before the specification was finalized.

One of the big features is the tools interface, where there were several different proposals from interested companies that, as it turns out, don’t exist anymore. But many of them that have been asking for a better way to interface OpenMP with development tools have worked hard to add this functionality to the spec.
“OpenMP is a specification that only details the functionality required and the semantics of the programming language,” says Klemm, explaining an important aspect of why this tools interface is even necessary. “We are not trying to not enforce certain implementations of the spec. Each vendor has its own way of implementing OpenMP, and usually those ways to implement OpenMP are incompatible with each other. So the inner workings of OpenMP are completely different across the vendors. The tools interface provides a standardized mechanism so that a programming tool vendor can, for instance, write a performance tool or a debugger or whatever that works across the board with all of the disparate OpenMP implementations. Now tool vendors can be agnostic about the specific OpenMP implementation, but have enough insight into those implementations to get what they need to support them.”
The major OpenMP implementations come from The Portland Group, the compiler maker that is owned by Nvidia but which supports all major CPU and GPU compute engines, and Intel, of course, which probably has the largest installed base among HPC players for both its compilers and its OpenMP implementation. IBM has one, too, and Oracle did as well for a while. Red Hat and SUSE Linux work together on an open source implementation of OpenMP that is associated with the GNU open C, C++, and Fortran compilers. Klemm says that there is a trend towards using the LLVM compiler backend and the Clang front end for C/C++ compilers, so the compiler stacks available in HPC are getting closer and closer together. (Clang has its own distinct OpenMP implementation from the GNU compilers, but given that this is all open source, it seems likely that over time their efforts will merge.)

Another big feature is support of OpenMP 5.0 running natively on GPU accelerators and being able to dispatch parallel routines to these massively parallel devices. OpenMP 4.0 had some basic support for GPUs, and with OpenMP 4.5 had some improvements. With OpenMP 5.0, the biggest change with regard to GPUs is support for unified shared memory between the GPU accelerators and the CPU hosts in a hybrid system. “You don’t have to transfer ownership of data any more, you can just access the CPU and GPU regions,” says Klemm.
In a Reese’s peanut butter cup moment (or actually a pair of them), the OpenACC parallel programming framework that was created to offload applications from CPUs to GPUs is now able to parallelize code natively on CPUs.
The OpenMP 5.0 spec introduces a feature called loop construct. Before now, OpenMP was very specific about the semantics of the parallelism that the code contained and how it could be translated down to the iron.
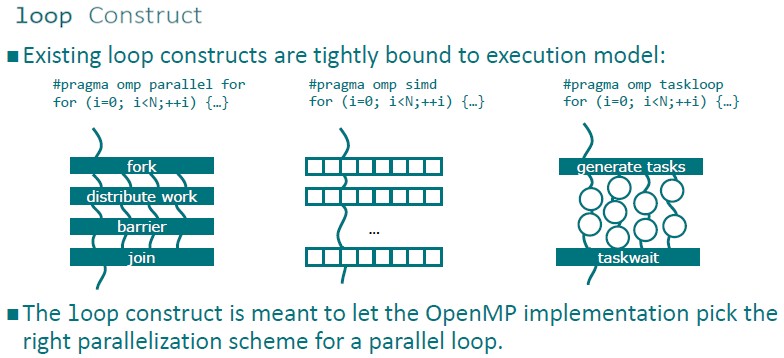
With the loop construct, the programmer can now tell the compiler that specific loops are fully parallel and then the compiler is free to choose any level of parallelism that it thinks is appropriate for the underlying hardware. If, for example, the compiler is pushing code for an Nvidia Tesla GPU accelerator, it would probably split the loop into teams and SIMT slots, whereas if the code is compiled for a host CPU it may do multithreading plus SIMD instructions to implement the very same loop. The compiler may reorder the loop to improve accesses to memory, it may do other parallel optimizations that are not possible if you have a threaded version of the loop in mind.
“The responsibility of parallelizing the code is moved to the software instead of the programmer,” says Klemm. This is a bit of a Holy Grail moment.
The updated OpenMP 5.0 has memory allocators, which are aware of the differences between high bandwidth, low capacity memory and low bandwidth, high capacity memory, as well as straight up low latency or read-only memory. There is now an interface inside of OpenMP that allows programmers to allocate memory where it will best suit the memory performance requirements of the application. “It is implemented in a way so that programmers can choose faulting mechanisms so that, for instance, if high bandwidth memory is not available, programmers can stop the program or find the best memory that is available in the system, such as DRAM on the local NUMA domain,” says Klemm. “There is a whole set of abstractions that at a very high level allow for the extraction of the memory that is needed and the implementation can pick and choose the right physical memory from the system, depending on what it has.”
Before this capability was woven into OpenMP, there were ways to manage such memory allocations, including libraries such as Memclient from Intel and Numactl from the Linux community, but these were either dependent on the processor architecture or the operating system, and they were incompatible with each other. This approach in OpenMP unifies access to these libraries and interfaces with them in a consistent manner.
OpenMP has to continuously evolve alongside the C, C++, and Fortran compilers out there in the field, and so the OpenMP 5.0 update also supports the most important new features of Fortran 2008, C++ 14 and C++ 17. Until OpenMP 4.5, the parallel programming specification was stuck at C++ 11, Fortran 95, and Fortran 2003.
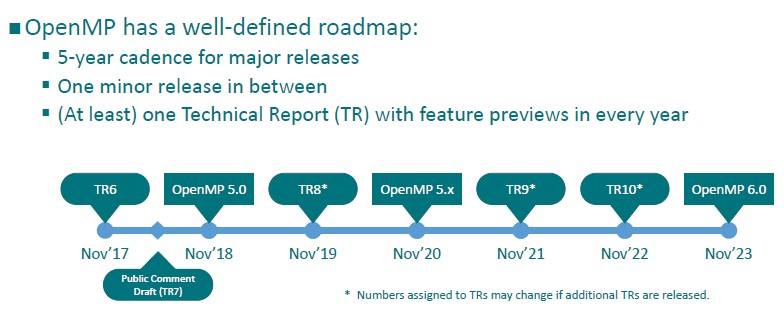
The cadence for OpenMP specification releases has been absolutely regular, and the play is to stick with five-year plans. OpenMP 3.0 came out in May 2008, with OpenMP 4.0 coming out in July 2013 and now OpenMP 5.0 coming out in November 2018. The plan is for OpenMP 6.0 to come out in 2023, concurrent with the rollout of many exascale-class supercomputers. There were – and will continue to be –dot release updates in between the major releases, depending on what gets added and how hard the future features are to implement. We can expect an interim OpenMP 5.X release two years from now, and it looks like the OpenMP organization is going to try to stick to new versions and releases coming out in November more or less concurrent with the future SC19, SC20, SC21, and so forth supercomputing conferences.


Datacenter Becomes Nvidia’s Largest Business
Something that we have been waiting for a decade and a half to see has just happened: The datacenter is now the biggest business at Nvidia. Bigger even than the gaming business for which it was founded almost three decades ago. The rise of the datacenter business has been no …
Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …
Nvidia To Build DGX Complexes In Clouds To Better Capitalize On Generative AI
GPU computing platform maker Nvidia announced its financial results for its fiscal fourth quarter ended in January, which showed the same digestion of already acquired capacity by the hyperscalers and cloud builders and the same hesitation to spend by enterprises that other compute engine makers for datacenter computing are also …
Be the first to comment