

People have been talking about software defined networking and its related network function virtualization for so long that it must appear to many organizations that everyone else is doing it. But in reality, there are very few organizations outside of the hyperscalers and big public clouds who have actually implemented SDN and NFV. But that is changing, and it is changing fast because certain network functions that never should have been on CPUs inside of servers whose real purpose is to run applications are offloading these functions to beefed up network interface cards.
It is a classic accelerator model, but with a few twists that are unique to networking and that mirrors the hard work that the hyperscalers and cloud builders did all by their lonesome to make their systems – including compute, storage, and networking – disaggregated, virtualized, and flexible. Now, mirroring a pattern we see all the time at The Next Platform, commercial alternatives to the hardware and system-level code that the hyperscalers and cloud builders developed at great expense and effort have become mature and integrated into a true SDN and NFV stack that can be deployed in commercial settings. And so, the telcos are leading the charge and large enterprises are right on their heels, looking at how they can run their networks more like the Super Eight.
Before the revolution in networking started, everybody bought specialized appliances that performed specific functions, which had their own proprietary software and underlying hardware, often using a mix of different kinds of compute – specialized ASICs mixed with FPGAs and sometimes CPUs – to drive those functions. A network consisted of these things – switches, routers, load balancers, firewalls, wide area network accelerators, content distribution devices, session border controllers, carrier-grade network address translation controllers, various testing and monitoring equipment – and it was very expensive for datacenters and very profitable for suppliers. Which is why it had to change. The hyperscalers and cloud builders pried the lids off these devices, and helped foment revolution by either developing versions of these services that could run on more generic servers, often onto specialized offload engines with CPUs or FPGAs, and they basically virtualized everything they could. Some of this software they created is still proprietary, and some of it has inspired open source projects that the mainstream can take advantage of. But the transition has not been an easy one.
“When software defined everything started happening around 2007, including network function virtualization, everybody said it was the best thing ever,” Kevin Deierling, vice president of marketing at Mellanox Technologies, explains. “Then they went to deploy it and found out that the efficiency is terrible. They wanted all of the cloud-like capabilities that they see with the cloud builders and the hyperscalers – agility and scalability – but could not achieve it themselves. I think what it has taken is the time to do the hardware and software integration that finally puts us at a point that we can deliver commercially what those hyperscalers and cloud builders created themselves and use internally. I think we can finally deliver on the promise of NFV.”
The telecommunications companies and cable operators (it is hard to tell the difference sometimes) are leading the charge, and because they have traditionally just sunk enormous amounts of capital into these appliances and they can’t afford to do that anymore. They also can’t wait to innovate or to drop the cost of their networks and increase their capabilities because they can be displaced by the hyperscalers and cloud builders, or their innovative peers in the telco and cable arena, in a heartbeat. Mainstream enterprises will not be far behind the communications service providers for much the same reason: They can’t spend a fortune on specialized appliances, so they need to avoid vendor lock in, and they need to virtualize the network functions, and they cannot lag their peers or they will lose business.
Here is what the evolution of SDN and by extension NFV looks like over the past decade:
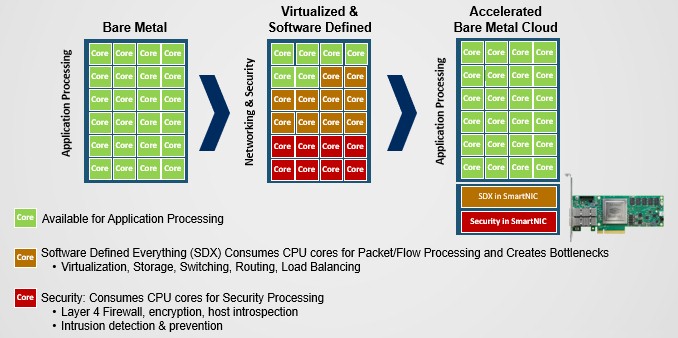
In the beginning, when all servers were bare metal running applications and the network was built from interconnected appliances, all of the cores on a server were available for processing. With the advent of virtualized servers and software defined networking functions, packet and flow processing as well as security functions such as firewall, intrusion detection and prevention, host inspection, and encryption. But that meant all of these network functions were pulled off the appliances and onto the servers.
“This brings flexibility and agility,” says Deierling. “But what happens is that we chew up all of the CPU cores with all of this stuff running in software. This is a great story for Intel because it chews up massive amounts of CPU forwarding packets. You can drive maybe 1 million packets per second, which corresponds roughly to 1 Gb/sec, using two to four CPU cores on a server. What we have seen is that even if you use twelve cores, you can’t reach 30 Gb/sec. And so it really is not a scalable solution, and this is what has blocked the wide scale deployment in telco and enterprise environments. They can’t stand the performance penalty.”
The answer, as we hear so often, is to at first accelerate these functions on the CPUs, and then in many cases boost the performance even further by adopting an offload model that runs the network functions software on adjunct processors in the network interface cards. To be specific, the control plane of the software defined network remains in the controller that companies deploy – VMware’s NSX, Juniper Networks’ Open Contrail, the Nuage Networks controller from Nokia (which is what the telcos use), or the integrated virtual networking in Microsoft’s Windows Server or Red Hat’s Linux stacks – and only the data plane is offloaded from the servers to the network interface cards. These stacks support the Data Plane Development Kit (DPDK) that was created by Intel to accelerate these functions on the server, but perhaps more importantly, they are also supporting the Accelerated Switching and Packet Processing (ASAP2) offload model put forth by Mellanox in conjunction with its ConnectX and BlueField lines of network interface cards.
“DPDK is an onload technology that Intel came up with, and today we are the manager of this project and we have the highest DPDK performance,” boasts Deierling. “Intel has a lot of good ideas and we like them and use them. This one is a really good idea for Intel because it chews up a lot of CPU, and it uses a polling mechanism so that instead of using interrupts to let you know there are packets, it polls and waits for data to be available. When you poll, you use up 100 percent of the CPU because you are just waiting, but with polling you can respond quicker, you just stay in user space and see that there is a packet available and keep operating on it. DPDK doubles the performance of Open vSwitch in terms of the packet rate, but at the expense of using up the performance of the cores it runs on.”
That is a tradeoff that many organizations will not want to make, considering the cost of a Xeon core these days – somewhere between $200 and $500 per core in the popular SKUs of the current “Skylake” Xeon SP processors at list price.
The performance difference between running Open vSwitch raw on the CPUs, running it on top of DPDK, and running it atop the virtual e-Switch inside of the ASAP2 stack that runs on the Mellanox NICs is dramatic. Take a look:
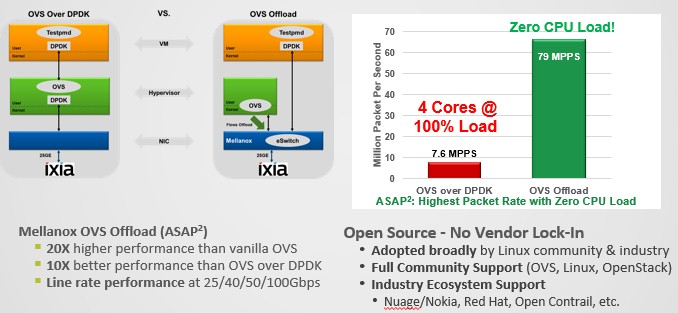
With four Xeon cores running Open vSwitch on DPDK at 100 percent of CPU capacity, the virtual switch can process 7.6 million packets per second (MPPS), but with the offload model espoused by Mellanox with its ASAP2 approach, all of the packet processing is offloaded to the NIC and the server can now handle 79 MPPS with zero CPU load. There is still processing for the control plane in both scenarios, but for the ASAP2 setup this is relatively low. It comes down to establishing a set of rules governing the control plane interfacing with the SDN controller (whatever one is chosen) and programming the NIC with these rules. This happens at initialization time and then periodically thereafter, but this does not eat much CPU.
To illustrate the value of ASAP2 for telcos, Mellanox teamed up with Nokia’s Nuage Networks and Red Hat to test the native Open vSwitch Virtio stack inside of Enterprise Linux and under the thumb of the Nuage SDN Controller and with the VXLAN Layer 2 overlay for Layer 3 networks added on. This was tested against an Open vSwitch setup that had the Nuage SDN Controller interfacing instead with the offloaded Open vSwitch running on Mellanox NICs on the same Enterprise Linux 7.4 platform. (This also supported VXLAN tunneling.) Here’s the setup:
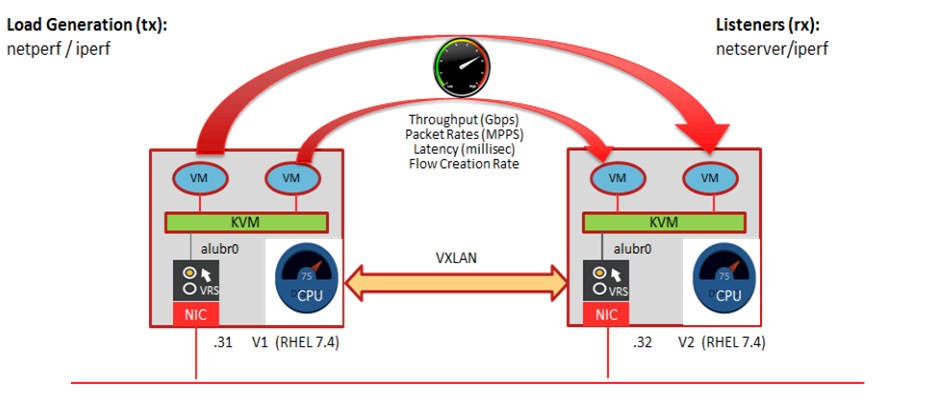
Here is what the benchmark results show:
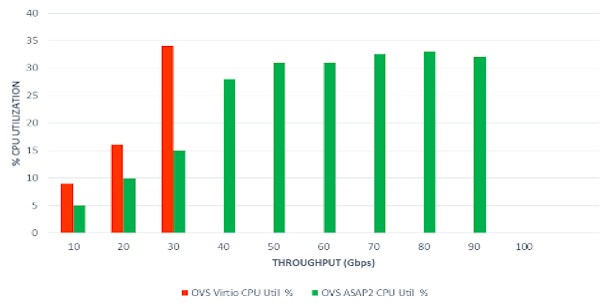
You have to be careful analyzing these numbers. The CPU load that you see is predominantly from the monitoring software that is counting how many packets the servers under test can process using Open vSwitch. But the larger point is that the Open vSwitch combination with the Linux Virtio networking tops out with around 30 Gb/sec of virtual switch throughput with a dozen cores assigned to it. Using the same SDN controller on the same server, the ASAP2 setup offloading to Mellanox ConnectX network interface cards can push 94 Gb/sec for large packets and can handle 60 MPPS running the VXLAN overlay.
“We are really accelerating all of this, and we are at the cusp of telcos and enterprises to really start using this in a big way,” Deierling says. “They don’t need to understand all of this technology, but what they do need to understand is that when they turn SDN and NFV on, it doesn’t eat all of their hardware and bring their application performance to a halt.”

Why The DPU Is More Important Than The CPU For Nvidia
If you are fairly new to the IT racket, you might be under the impression that the waves of integration and disaggregation in compute, networking, and storage that swept over the datacenter in recent decades were all new, that somehow the issues of complexity and cost did not plague systems …

InfiniBand Is Still Setting The Network Pace For HPC And AI
If this is the middle of November, even during a global pandemic, this must be the SC20 supercomputing conference and there either must be a speed bump that is being previewed for the InfiniBand interconnect commonly used for HPC and AI or it is actually shipping in systems. In this …

FRR: The Most Popular Network Router You’ve Never Heard Of
Everyone in the networking industry seems to fall into one of two camps: those that have used server-based routing software and those that have no idea such a thing exists. Now a solution called Free Range Routing (FRR) is taking over cloud and enterprise datacenters around the world and if …
Be the first to comment