
There have been several chip startups over the last few years that have sought to new ways to train and execute neural networks efficiently, but why reinvent the wheel when each idea has yielded at least one small piece of a much bigger performance picture?
This week at the annual Hot Chips conference Arm presented its first generation machine learning processor, the IP of which should be available to partners later this year.
The architecture, which was first described under the name “Trillium” is comprised of some familiar elements tied together with Arm logic cores and could mean much for those who want the functionality of what a TensorCore on an Nvidia Volta GPU offers, the compression techniques of a DeePhi (now part of Xilinx) neural network, the programmability of an FPGA, and the low power processing capabilities of a DSP. In other words, Arm might have just cobbled together a best of all worlds AI processor that could spell big trouble for chipmakers that have to lay a lot of extra real estate down on much larger general purpose devices.
As Ian Bratt, director of technology and distinguished engineer at Arm told us at Hot Chips this week, the design goal for Arm’s first foray into an AI processor is to be as generalizable as possible so that it can meet market needs in server-side AI as well as on much smaller devices for automotive and IoT needs.
“Along the way to this first generation machine learning processor we had some early missteps where we saw we were bringing old frameworks to a new problem. We could see how GPUs, CPUs, and DSPs were being used for machine learning but we started to see how we could leverage technology in each of these distinctly. We could leverage technology in CPUs around control and programmability and from GPUs in terms of data compression, data movement and arithmetic density, for instance, all with the efficiency uplift of a DSP and with an open source software stack.”
As seen below there is nothing particularly exotic about Arm’s machine learning architecture, but what is worth noticing is what they pulled from the most successful innovations in hardware, compression, and compilers.
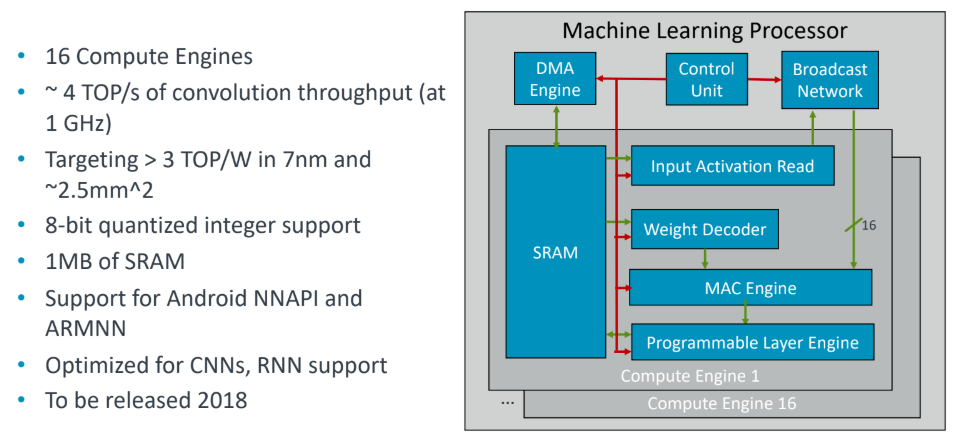
The building block is the compute engine, each of which (16 total) is a 64 KB slice of SRAM. The MAC engine (not unlike the TensorCore we’ve seen from Nvidia) is where the convolutions are performed and the programmable layer engine is what handles much of the necessary shuffling among layers. The architecture has a DMA engine for talking to the external memory interface. Arm’s own Cortex tech is the control engine.

Bratt breaks down the various architectural features by noting what is most important in a neural network processor chip. The key features that keep these devices “future proof” include static scheduling capabilities, efficient convolutions, bandwidth reduction mechanisms as well as programmability and flexibility.
It might be easy to overlook the value of that first element—static scheduling—but as Bratt explains, this is a key part of the overall performance and efficiency of the chip.
During inference, memory access patterns are perfectly statically analyzable and can be easily understood and mapped but many devices do not take advantage of this. CPUs have complicated cache hierarchies for optimizing around non-deterministic memory accesses but for deterministic neurla networks, it is possible to lay everything out in memory ahead of time. The compiler can then take the neural et and create a command stream for different components (orchestrated by the Arm control processor) and hit registers to control these components. The short answer for why this matters is that there is no need for caches. Another hidden efficiency there is that the flow control is dramatically simplified, meaning less energy consumed and more predictable performance.
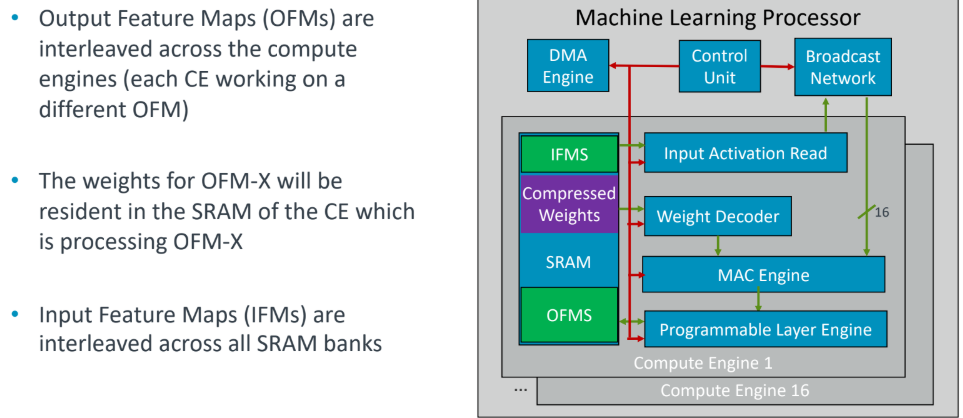
More efficiencies come with how convolutions are handled. The SRAM shown below highlights the way the compiler will allocate a portion of resources for the input feature maps and the compressed model weights. Each compute engine will work with a different feature map interleaving across the compute engines.
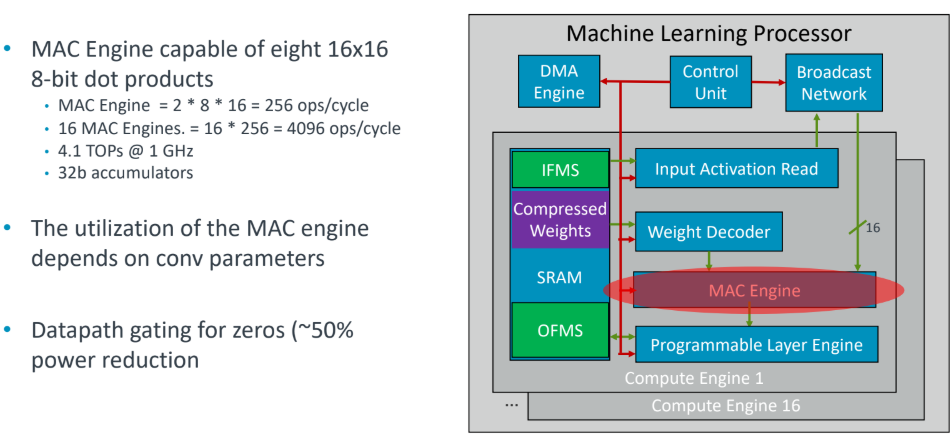
Arm’s MAC engine can do 8 16×16 dot products. We have talked about why this is important before, but there are many zeroes in these operations which can be detected and adjusted for in the MAC engine to avoid spending energy.
Arm also has what it calls the programmable layer engine which is designed to “future proof” the processor via programmability. It uses the Cortex CPU tech to support non-convolution operators and with vector and neural network extensions.
Further efficiencies are gained with the machine learning processor feature map compression techniques that sound similar to what DeePhi is doing for CNN compression.
Bratt says the machine learning business unit at Arm has 150 people and that number is growing with growing demand for machine learning to be integrated into new and existing workflows and settings. The goal is to make this work across a range of segments, he says, but making a generalizable platform that has all the needed features for as broad of a class of users is not simple.
Eliminating caches, refining compression, using mixed precision arithmetic, and pulling together compute on thin SRAM slices and shuttling them off to a dense dot product engine all make Arm’s IP a compelling addition to the market—and one that can be further refined for key workloads. The addition of high bandwidth memory (or HMC) might have made this a bit more recognizable compared to some AI specific processors but it will be up to licensees to see how that might work together in a system. Arm engineers truly pulled the best in class technologies for AI processors from the ecosystem and with an open source software hook, could let licensees make big waves.
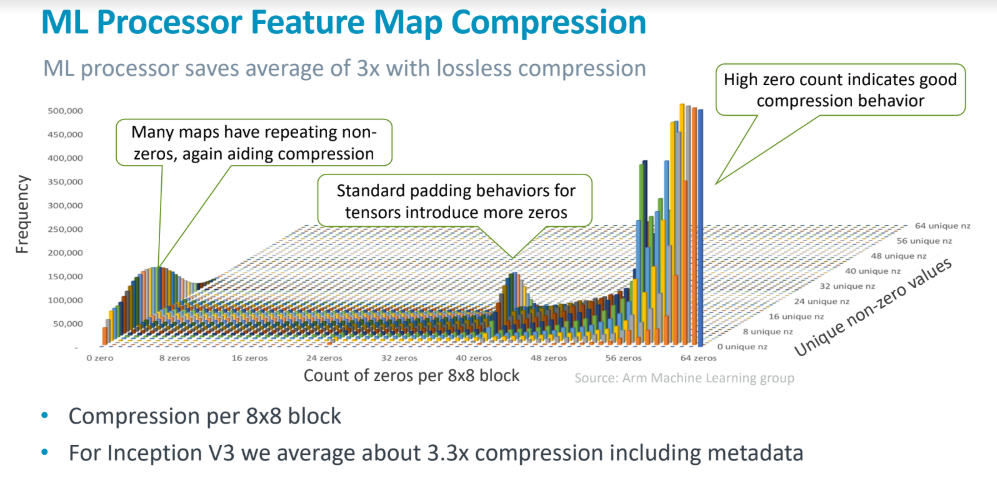
The histogram above shows 8X8 blocks on Inception V3 that highlights the lossless compression results that take the zero/non-zero filtering approach that significantly pares down the size of neural networks. The weight compression results stay in the internal SRAM and pruning techniques also stay there until required as well.
There are not many options for licensing this kind of technology and for Arm to nail down the most successful parts of existing neural network processors is noteworthy.

Be the first to comment