
General purpose computing systems have been seen as the best way of delivering on enterprise data processing needs for decades. Creating a standard platform to serve as the foundation upon which a wide range of business applications can be developed and run makes for greater flexibility and lower cost, and thus we saw the rise of Windows and Linux on the X86 platform in the datacenter.
However, there comes a time when the general purpose platform becomes a barrier to improving performance, and using a specialized system provides better performance, lower cost per unit of work, or both at the same time. We have already seen how specialized hardware such as GPUs and ASICs has crept into servers in order to accelerate specific functions, for example, while Pure Storage has introduced its AIRI FlashBlade system, described as converged infrastructure optimized for machine learning and AI workloads.
In a similar light, Yellowbrick Data has stepped out of stealth mode with a dedicated data warehouse system that combines custom hardware and software to deliver an integrated system for analytics, along with some impressive claims on performance: one customer that has piloted development of the data warehouse appliance has reportedly been able to replace six racks that made up its existing platform with a single 6U Yellowbrick system that offered much greater performance.
Yellowbrick is going after the customers of traditional data warehouse platforms such as Teradata’s eponymous warehouses or the FPGA-accelerated kit from IBM’s Netezza unit or even Oracle Exadata shops, particularly those who are running into limitations such as difficulties handling advanced forms of analytics, the time take to process some queries, as well as rising support costs.
The performance of the Yellowbrick’s data warehouse appliance hinges on a couple of key features: It is entirely based on flash storage, and it pioneers a technique that the firm calls native flash queries, in which data being processed is streamed directly from SSD storage and into the CPU cache, bypassing main memory entirely in order to take advantage of the massive bandwidth offered by flash memory. (That’s a neat trick.) This is one reason why Yellowbrick decided it needed to create its own custom platform, because of the difficulty of implementing this in an off-the-shelf server using a standard operating system with all its layers of drivers and other abstractions.
“We have built everything in there, from the boards in the blade servers that run the database – it’s a scale-out data warehouse, like most massively parallel data warehouses – through to the operating system, down to the core of the database, the query planner, the query executor, the user interface. Every aspect of the stack is built by Yellowbrick,” Neil Carson, chief executive officer at the upstart data warehouse supplier, tells The Next Platform.
“The special thing we have done is this: If you think of an SSD, it has got 10X or 20X the bandwidth of a hard drive, and now it has higher capacity as well. What we asked is: How do we get 10X to 20X the analytic performance out of this? So what we do at Yellowbrick is we move the data directly from the SSD directly into the cache of the CPU, bypassing main memory. To do that, we have to do our own operating system with our own schedulers, our own memory managers, our own device drivers, our own file systems – all of that stuff. So it’s a massive undertaking,” Carson adds.
This sounds counter-intuitive, because no matter how fast flash is, it is still about a thousand times slower than the DRAM memory in a server. The key thing to remember is that many analytics workloads are much too large to fit into main memory (or at least, the amount of memory that most customers can realistically expect to fit into a server, particularly given the rising cost of memory over the past few years) and most analytic workloads are also restricted by bandwidth rather than latency, according to Yellowbrick.
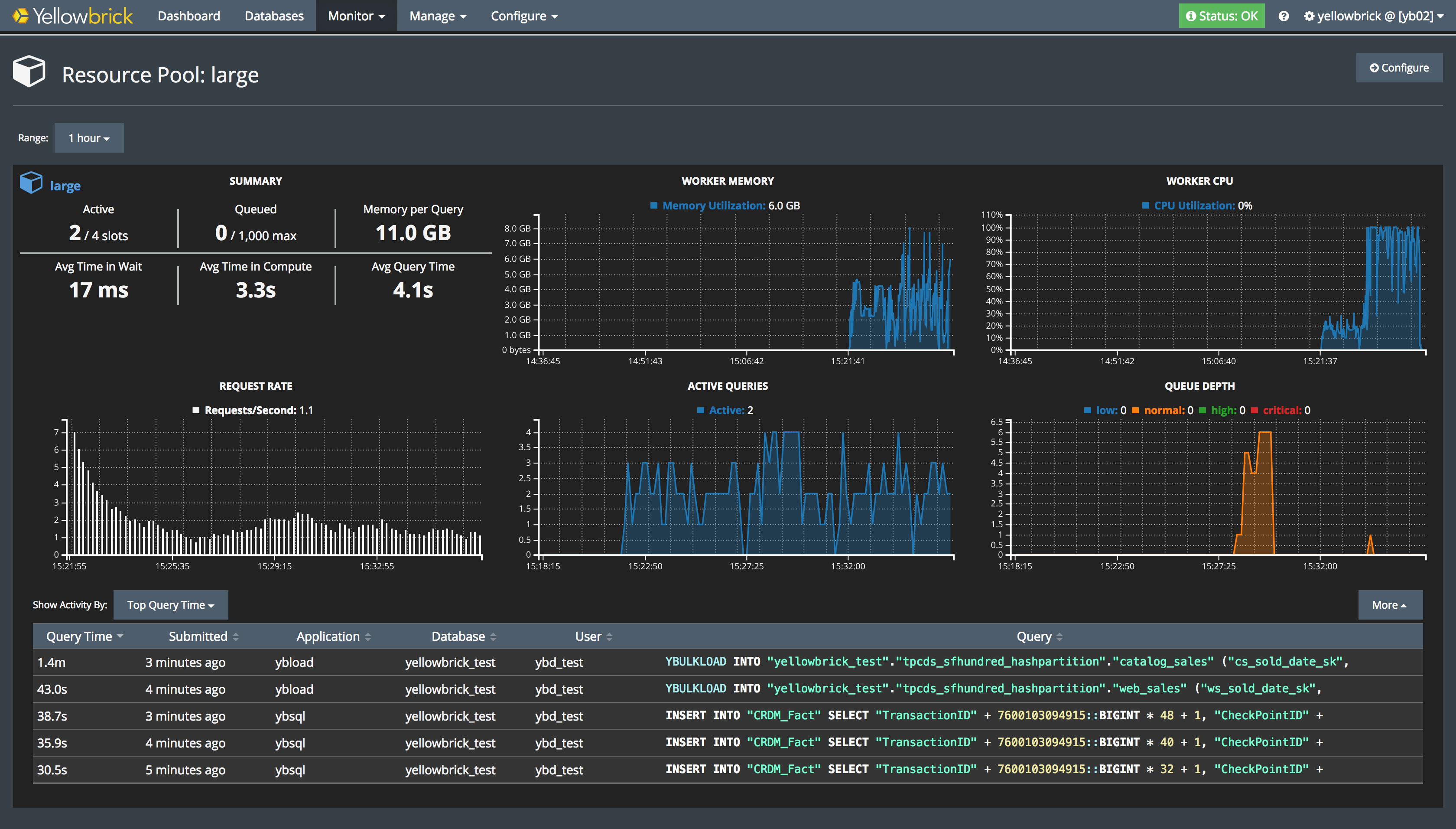
“In analytics, most of the operations you do care about bandwidth and they are on streaming data, so what we do is we stream data from the SSDs through the CPU and through the caches, and because you’re streaming, it’s fine as long as you’ve got enough cache to support enough I/O buffers to keep the SSD busy, which you do on a modern processor. When you come to do big sorts, big joins, big aggregates, those operations care about latency, and for that we use large amounts of main memory,” Carson explains.
The end result is that users can work with multi-terabyte or even petabyte data sets, while getting comparable performance to an in-memory database such as SAP HANA, but with much less infrastructure required.
Sadly, Yellowbrick is being somewhat cagey about the precise architectural details of its data warehouse system, but it appears to be built from standard components, including unspecified variants of Intel’s Xeon processors. A typical system is a 6U rack-mount enclosure that holds up to 15 compute node blades. Each each deployment needs two manager nodes (for redundancy purposes). Thus the architecture is split into a data plane and a control plane, with the data plane running on the scale-out compute nodes.
According to Yellowbrick, the manager nodes are basically standard servers running Linux plus Yellowbrick software, while the compute nodes are custom-built and run Yellowbrick’s custom operating system. As these are single socket nodes, the fact that a fully populated enclosure has 150 physical CPU cores, 1.92 TB of DRAM memory and 60 TB of raw storage suggests each compute node is a 10-core Xeon with 128 GB memory and a 4TB SSD.
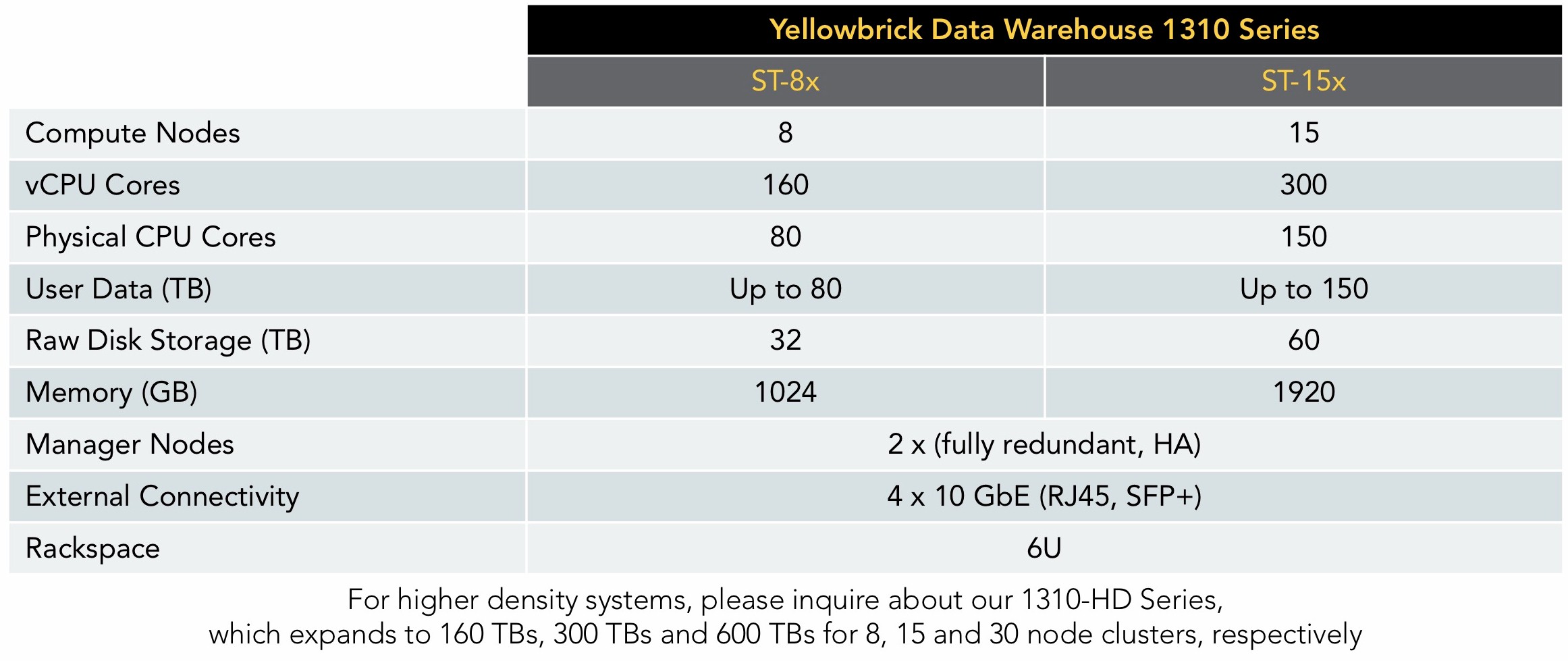
Carson says that each node has “massive amounts of NVM-Express bandwidth available – 8×4=32 lanes worth,” while the whole enclosure has external connectivity through four 10 Gb/sec Ethernet ports.
Because of the modular design, customers can scale up to petabytes of data by adding analytic nodes on the fly. How far this can go depends how well the customer’s data compresses, according to Carson, but somewhere between 1 PB and to 2 PB of data.
“The architecture is unlimited – it can basically scale as wide and as high as you can go,” Carson says. “Practically, we haven’t had a customer that has needed anything bigger than a petabyte so far, and that’s enough to replace eight to eighteen racks of anything else you can buy out there.”
Of course, having a custom-built specialist system probably rings alarm bells for some potential buyers, who will have questions about the interoperability of such a setup with their existing enterprise infrastructure. We put these concerns to Yellowbrick, and Carson told us that it is designed to present itself as a standard SQL-based system from the outside, and that the components that the users interact with are the Linux-based manager nodes.
“From the outside it looks like the Postgres database, which is dialect compatible with IBM’s Netezza and Amazon Redshift and those products, so it just looks and smells like what’s there today, it just plugs in and interoperates with all the data flows that they already have, so there’s no magic at all from the standpoint of the user, this is a trivially easy to use reliable database system. You plug the system in, you turn it on and you get a database, a large data warehouse, and to move data in there customers can use all the ETL tools that they use today, they can use Informatica, they can use Syncsort, they can use any of the standard ETL tools or they can just copy CSV files and load them into the database,” Carson claims.
Yellowbrick’s performance claims may sound extraordinary, but the team behind the company includes several key engineers and executives formerly at Fusion-io, a pioneering high-performance flash storage firm, including Carson who served as chief technology officer.
Carson said that the idea for Yellowbrick data came from their experience at Fusion.io. All of its customers were using flash to accelerate OLTP databases to make transactions – Apple and Facebook were very early adopters and put Fusion.io on the map– but then the big data craze happened and all the data warehouse vendors and Hadoop companies came looking to pilot flash with their analytic databases.
“In pretty much all cases, the flash was expensive, the performance gains were mediocre, and as a result, the vast majority of analytic databases today just ship with hard drives not with flash,” he says. “We realized the reason why data warehouses were not getting a performance gain from flash was the core architecture of the database. We’ve seen this in the storage array market where people built early storage arrays with hard drives, they transitioned them to SSDs, and they went a little bit faster but the gains didn’t justify the economics at the end of the day, so you had companies like Pure Storage and XtremIO coming out and actually building dedicated systems for flash that actually realized the true benefits if the media.”
Yellowbrick says it has already signed up ten customers while operating in stealth mode, three of which it has detailed at launch. These are Teoco Corporation, which provides analytics and optimization services for telecoms operators worldwide; Overstock.com, an online retailer using the system for analyzing customer data and fraud detection; and Symphony RetailAI, which provides retail analytics services for large supermarkets and their suppliers all over the globe.
Future plans for Yellowbrick include a public cloud version. This would presumably see a cloud provider, or possibly Yellowbrick itself, host Yellowbrick Data Warehouse systems and provide on-demand access to them for customers, but the firm declined to give any further details.
Yellowbrick also declined to even discuss prices, but its website claims that early customers have been able to adopt this new solution for less than the annual support cost of their legacy systems.
“What you would have to spend with one of the older vendors, which might cost low digits millions, on Yellowbrick costs hundreds of thousands of dollars, so there is order of magnitude cost savings there,” Carson claims. This is exactly the same pitch – and engineering difference – that Oracle used to sell its Exadata database appliances for OLTP against established RISC/Unix NUMA systems and IBM mainframes.


Being Persistent With Persistent Memory
Intel in October clarified its memory plans moving forward when it announced it is selling its NAND memory business to SK Hynix in a two-step acquisition that is worth $9 billion and will take until 2025 to be completed. However, while the deal itself is unusual – the deal is …
Micron Gears Up For Its Potential Datacenter Memory Boom
If you don’t like gut-wrenching, hair-raising, white-knuckling boom bust cycles, then do not go into the memory business. There is a reason that Intel was driven out of it back in the 1980s, and once again in recent years as it exited the 3D XPoint ReRAM flash-ish memory business. The …
Putting More Flex Into Flash Storage Arrays
In a cloud-based, highly distributed, and data-centric world, flexibility in what a piece of hardware and its systems software can do, where it can run, and how it can be configured is a critical differentiator for picky enterprises. For several years, Pure Storage has been talking about flexibility and choice …
Be the first to comment