
The Spectre and Meltdown speculative execution security vulnerabilities fall into the category of “low probability, but very high impact” potential exploits. The holes that Spectre and Meltdown open up into systems might enable any application to read the data of any other app, when running on the same server in the same pool of system memory – bypassing any and all security permissions. These potential exploits apply to every IT shop, from single-tenant servers potentially exposed to malware to apps running in a virtual machine (VM) framework in an enterprise datacenter to apps running in a multi-tenant public cloud instance.
There are no known exploits for Spectre and Meltdown – yet. Therefore, there are no patterns for antivirus and malware detection suites to match. After the first exploit gets loose in the wild, it is likely to have an open opportunity to siphon data from any infected system. Variants will quickly proliferate. Keeping up with proliferating exploit variants will quickly devolve into a losing game of “Whac-A-Mole.”
The best strategy is to fix Spectre and Meltdown before the first real exploits are demonstrated. However, there is a dramatic difference between applying a normal software update to patch a security exploit; applying the new Spectre and Meltdown fixes boils down to managing extreme complexity. Every IT organization will be challenged to address this extreme complexity over the next few calendar quarters. Plus, we only talk here about computing; modern datacenter switch architectures also use server processors and are likewise also at risk. Ditto for storage arrays and clustered storage that rely on servers are their basic building blocks.
We think that Spectre and Meltdown do have the potential to:
- Accelerate enterprise IT migration to cloud-based platform-as-a-service (PaaS) and software-as-a-service (SaaS) applications.
- Increase cloud and enterprise consideration of non-Intel based servers.
The following is what IT is up against and how IT might better cope with these updates.
How To Fix Spectre and Meltdown (Condensed Version)
Spectre and Meltdown fixes start with potential microcode updates from server processor manufacturers AMD, Cavium, IBM, Intel, Oracle and Qualcomm. The impact then ripples to firmware updates coordinated between processor manufacturers and contract motherboard manufacturers and original design manufacturers (ODMsuch as ASUS, Gigabyte, Quanta and Wiwynn) and OEM system vendors (such as Dell EMC, HPE, Huawei, IBM, Lenovo, Supermicro and Oracle). On top of all of that are matching security patches for OS distributions (Canonical, CoreOS, Red Hat and SUSE Linux distributions, plus Microsoft Windows Server, to start), hypervisors (Hyper-V, KVM, VMware ESXi, Xen and others) and container frameworks (Docker, Red Hat OpenShift and others).
The entire stack of Spectre and Meltdown fixes is still very fresh and not fully tested. It is going to take time for this complex system to reach stability.
We collectively call the Spectre and Meltdown fixes “CVEs” in this article, short for the Common Vulnerabilities and Exposures numbers they have each been issued:
- Spectre
- Variant 1: Bounds Check Bypass (CVE-2017-5753)
- Variant 2: Branch Target Injection (CVE-2017-5715)
- Meltdown
- Variant 3: Rogue Data Cache Load (CVE-2017-5754)
Processor Fixes
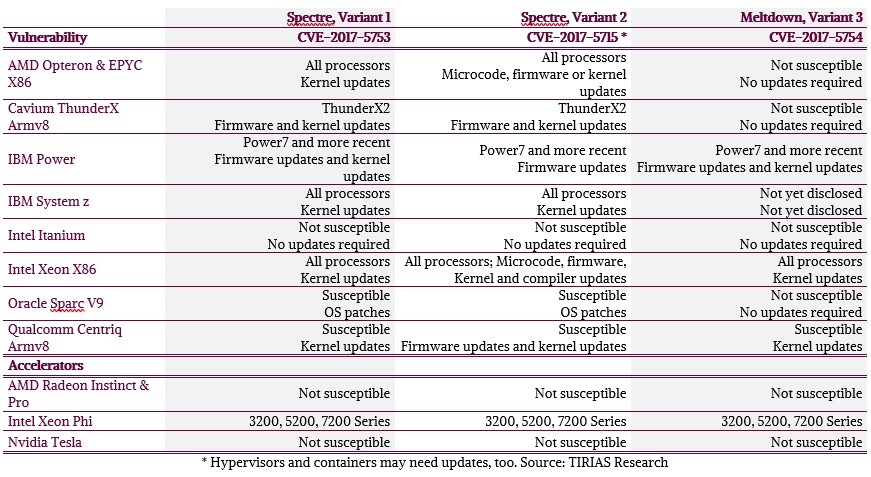
All current generation server processors – AMD Epyc, Cavium ThunderX2, IBM Power9, Intel Xeon SP, and Qualcomm Centriq 2400 – are affected by one or more of these CVEs to one degree or another, as are many older AMD, IBM, Intel, and Oracle processors models. All are scrambling to ship microcode and firmware patches to their downstream supply chain, although Cavium and Qualcomm carry less of a burden since their affected processors are just entering the market.
For most enterprise datacenters, the primary concern here is deploying updates to older AMD and Intel processors and to older OS and hypervisor distributions and releases. However, for the platform and system software supply chain, the number of processor models that will need to be regression tested is extraordinary.
I’m not going to describe CVE exploit details (see here for a great explanation from Chris Williams at our sister publication The Register) or which processor vendors are most or least affected. All the fixes involve some amount of performance degradation, from trivial to double-digit percentages. While early fixes have been issued (or are not necessary) for variants one and three, variant two is harder to fix and affected processor vendors will be updating all their patches through the first quarter. We list most of the processors in use today in the table below with a summary of their CVE exploit exposure and update status.
Note that these CVEs potentially expose data on compute accelerators designed to map accelerator-local physical memory into a processor’s OS kernel address space. This type of shared memory space is sometimes called “heterogeneous computing.” The impact here is for servers accelerating data analytics and deep learning with any shared memory add-in accelerator. The shared memory risk is two-fold, because processors can access accelerator memory and accelerators can access system memory. Because of that, an accelerator that includes a processor architecture using speculative and/or out-of-order execution might also require fixes to address the CVEs, adding to a IT organization’s update complexity. Of the server compute accelerators listed below, only Xeon Phi is known to perform speculative execution and therefore only its processor architecture is potentially exposed to both risks. GPU accelerators do not implement speculative execution, they are only affected by speculative processor access to accelerator-local memory. We exclude FPGA-based accelerators, but if they implement shared memory architecture, they might also be affected. We also exclude processors with integrated graphics, as integrated graphics are not used as compute accelerators.
Server processor vendors will eventually fix their silicon designs so that these CVE patches are not needed. However, there is a two-year a minimum timeline for implementing these fixes in silicon. That means first half of 2020, at the earliest, before any of the current server processor vendors can ship fixed chips in volume.
Platform Fixes
Motherboards are designed for specific processors from each vendor. What is important here is that every motherboard must have processor-specific firmware on a flash chip. This firmware – called BIOS, UEFI, and so on – contains the code that starts up a server processor when power is turned on. After the firmware runs, it loads an OS, hypervisor or container.
Installing firmware fixes can be temperamental. For PCs and smartphones, interrupting a BIOS or system update in any way may “brick” the device – it may simply not boot ever again. Servers are also subject to bricking. Because of the risk of bricking and because each server is completely offline for the time it takes to re-flash its firmware (and therefore not doing its job), datacenters only update server firmware under duress, when a firmware fix corrects a problem that the datacenter is directly experiencing.

System Software Fixes
OS vendors usually handle security patches for a host OS (used with hypervisor and container frameworks), without needing to coordinate with upstream processor, motherboard and system vendors. In addition, most security updates do not involve updating kernel code – kernel updates are a very big deal.
Kernel code is the rigorously regression and time-tested core code of an operating environment. Enterprise kernels must be robust and resilient (“bullet-proof”), so changes are made in a slow, deliberate, highly validated fashion. These CVEs touch every datacenter operating environment kernel, and due to the high-impact nature of the CVE exploits, fixes must be made available quickly. Other “user mode” operating environment updates may also be required for higher-level frameworks, like hypervisors and containers.
In addition, some of the CVEs require, for each specific processor model, in-depth coordination through the supply chain from processor microcode to a system software fix. Because of this, the combination of fixes needed to update a single OS release for each processor model and each CVE variant may be completely different. The impact of this complexity on OS, hypervisor and container vendors is that only a handful of OS kernels will receive updates to fix the CVEs, and so relatively few full OS distributions will be updated.
Sudden Impact to Datacenter Operators
Every datacenter operator will have to decide where the crossover point is between a) customer pressure to deploy the CVE fixes as soon as possible and b) IT pressure to wait for CVE fix stability and optimization before deployment. When that crossover point is reached, datacenter operators will need processes in place for:
- Enumerating every server chassis in a server farm, down to each server’s processor model and firmware revision
- Enumerating the contents of every server’s deployed software image, including kernel revisions
- Assembling, testing and validating the right combination of fixes for each server’s combination of processor, platform and system software
- Deploying processor microcode and/or motherboard firmware updates across all servers
- Deploying kernel-level software updates across all servers
- Validating that version-controlled microcode, firmware, kernel and OS updates have been performed before rebooting each server
Because every server must be updated, these CVEs will invoke rolling “blackouts” across a datacenter or multiple locations.
There are additional risks to deploying what amounts to an unplanned operating environment update:
- Only specific (more current) operating environments are likely to be patched by OS, hypervisor and container vendors. This will force an operating environment update for datacenter customers choosing to fix the CVEs.
- An operating environment update may force application updates. Older versions of key applications may not be validated against current operating environments. This will force app licensing renegotiations, new app image validation and perhaps data migrations to new app database formats or schemas.
The end result of this ripple effect may be that IT organizations consider whether to move key applications into managed PaaS environments or punt to a data migration into cloud-based SaaS apps.
The CVE fixes will affect the performance of every application differently, based on each application’s memory and I/O usage patterns. Most customers should not notice much performance difference after installing the CVE fixes. However, there will be exceptions:
- Cloud datacenter operators that run at extremely high server utilization rates. These customers may have to deploy more servers to achieve the current levels of service for a given workload.
- Cloud datacenter customers running apps that highly utilize a specific instance type. These customers may have to rent a slightly larger instance to run their app at the performance level needed.
- Enterprise and high-performance computing (HPC) datacenter operators running apps close to the maximum utilization of specific physical or virtual machine (VM) types. These customers may have to buy new servers to host their existing apps, or may decide to push the offending apps into cloud instances.
The critical effect across the industry is that every application benchmark must be updated to fix Spectre and Meltdown, because the performance degradation will be measurable.
How Will Deploying CVE Fixes Play Out?
Cloud giants, such as Alibaba Cloud, Amazon Web Services (AWS), Baidu Cloud, Google Cloud Engine, Microsoft Azure and Tencent Cloud, as well as social media giants, such as Facebook and Twitter, already have significant IT automation capabilities. These companies are already evaluating CVE fixes and have the capability to deploy those fixes at scale. Likewise, managed cloud services, such as IBM Cloud, Packet and Rackspace Managed Cloud, are also already engaged in developing CVE responses.
Large enterprise IT shops are closely watching the CVE fixes and talking with their systems vendors about how to deploy fixes. Most of these customers buy servers in volume from branded OEMs. It will be up to the OEMs—primarily Dell EMC, IBM, HPE, Huawei, Lenovo and Oracle—to assemble, test and validate the right combination of fixes for each of their server products in their large customers’ installed bases.
The pain over fixing the CVEs will be felt most at medium sized IT shops that do not have dedicated security staff and do not buy directly from a server OEM. App migration is a big challenge in the mid-market, and so are data security and privacy. These customers should consider working with a Managed Security Services Provider (MSSP), such as Rackspace Managed Security Services, Dell Technologies’ SecureWorks and HPE PointNext (there are many others). MSSPs can help automate the process of updating datacenter infrastructure to mitigate potential CVE exploits. MSSPs are still in the early stage of addressing CVE fixes, but should begin to see the mid-market opportunity in the next few months.
Small IT shops or small businesses working with local systems integrators (SI) or value-added resellers (VAR) will probably take the longest to apply these fixes. It may take a successful exploit to educate this section of the market, and it may be that app modernization is one step too far – small businesses are most at risk for simply punting on owning servers and moving to some form of cloud provisioning.
What Else Can Be Done?
Encrypt System Memory. AMD’s EPYC system-on-chip (SoC) architecture implements main memory encryption and decryption in hardware in its memory controllers. Hypervisors and containers supporting AMD Secure Run technology may not prevent CVE exploits, but they may ensure that when a CVE exploit reads data from a different VM, that data cannot be decrypted by the CVE exploit. AMD EPYC’s memory encryption and decryption overhead is in the 1 percent performance impact ballpark, significantly lower than the CVE fixes currently being deployed.
IBM’s System z mainframe also offers memory encryption. But it is, well, a mainframe, and not an economic alternative for many server customers.

Review Key Management Processes. Now is a good time to review key management processes and update them to industry best practices and standards. This is not a short-term fix, as it requires changes to application source code, debugging and re-validating application behavior.
Modern cryptographic (“crypto”) systems should put all their crypto keys in one basket—and then guard the basket well. There are two key principles behind this design best practice:
- Least privilege: A process should only have access to the information needed to do its job.
- Compartmentalization: Limit key access only those processes that must use that key.
Now is a perfect time to review crypto key hygiene best practices. Good key hygiene means decrypting keys only when needed. When a process is finished using a decrypted key, it should erase memory containing the key and any information needed to create the key– effectively minimizing the decrypted key’s lifetime. The longer a key remains decrypted in memory (for example, as a global variable in an application), the greater the risk that the key can be stolen. There is some nominal coding and runtime overhead to implement decrypting keys on-demand and then cleaning up memory, but these should be negligible compared to the overall performance costs of the CVE fixes.
Guarding a key basket means keeping your keys protected behind key derivation functions and diligently erasing memory. For more detail on industry best practices, start with US NIST key management guidelines and crypto key management systems standards.
Simply put, encrypt sensitive information – period. Encrypt sensitive information in-flight, when sending it over a network or over the Internet. Encrypt sensitive information at-rest, in storage and in memory.
While Spectre and Meltdown are forcing the issue of memory security today, over the next few years non-volatile system memory technologies (via dual in-line memory modules, known as NVDIMM) will also force many of the same considerations. Companies like HPE are pioneering new non-volatile system memory hardware and software architectures in preparation for new product introductions. (I wrote a backgrounder on these new technologies at a previous gig, it still very much applies.) Non-volatile system memory should always be encrypted, as it will still contain data when it is powered down and removed from a system.

Additional Thoughts
The datacenter supply chain is working hard to ensure that the upcoming Spectre and Meltdown processor, platform and system software fixes are robust and will minimize server performance degradation. The first combinations of patches will most likely be the least stable and the worst performing patches—but, stability and performance is likely to improve over time.
Jacob Smith of Packet reminded us: “The cloud is about automation. Following that, the core things you get from digital transformation are agility and the ability to operate at scale.” If IT shops do not already have processes in place to manage this update complexity, there is no reward for enduring multiple updates as waves of fix revisions spew out of the server supply chain. Every IT shop will have to evaluate for itself how long they can hold off in deploying fixes in each datacenter.
At first glance, CVE fixes equally affect cloud and enterprise datacenters. However, the ripple effect of updating operating environments to a more recent version (simply to install the CVE fixes) is likely to force enterprise IT shops to evaluate modernizing applications.
In the short-term, enterprise server buyers may look to AMD Epyc servers as a credible alternative to Intel Xeon SP servers. Cloud server buyers may also consider Arm processor-based servers (Cavium ThunderX2 and Qualcomm Centriq 2400 processors) and IBM Power9-based servers as they evaluate total cost of ownership (TCO) for specific classes of workloads.
In the long-term, Spectre and Meltdown do have the potential to accelerate enterprise migration to the cloud, especially for small and medium businesses. Organizations that develop processes to manage this complexity will benefit the most. Because it is likely that we’ll find more hardware bugs that will require software fixes.
Paul Teich is an incorrigible technologist and a principal analyst at TIRIAS Research, covering clouds, data analysis, the Internet of Things and at-scale user experience. He is also a contributor to Forbes/Tech. Teich was previously CTO and senior analyst for Moor Insights & Strategy. For three decade, Teich immersed himself in IT design, development and marketing, including two decades at AMD in product marketing and management roles, finishing as a Marketing Fellow. Paul holds 12 US patents and earned a BSCS from Texas A&M and an MS in Technology Commercialization from the University of Texas McCombs School.
Author’s Note: David Teich (@Teich_Comm) and Andrew Donoho (@adonoho) asked great questions that enabled me to refine my thoughts in this post. Andrew contributed much of the key management text.


Trading Off Security And Performance Thanks To Spectre And Meltdown
The revelations by Google’s Project Zero team earlier this year of the Spectre and Meltdown speculative execution vulnerabilities in most of processors that have powered servers and PCs for the past couple of decades shook the industry as Intel and other chip makers scrambled to mitigate the risk of the …
How Spectre And Meltdown Mitigation Hits Xeon Performance
It has been more than two months since Google revealed its research on the Spectre and Meltdown speculative execution security vulnerabilities in modern processors, and caused the whole IT industry to slam on the brakes and brace for the impact. The initial microbenchmark results on the mitigations for these security …
Reckoning The Spectre And Meltdown Performance Hit For HPC
While no one has yet created an exploit to take advantage of the Spectre and Meltdown speculative execution vulnerabilities that were exposed by Google six months ago and that were revealed in early January, it is only a matter of time. The patching frenzy has not settled down yet, and …
According to the Intel CPU design, the White House (Kernel) need to relocated for the security issue (Meltdown)!
According to Intel CEO, relocating the White House is the intended design!
Funny and amazing : )
Unfortunately Qualcomm on Jan 6 confirmed the impact of Spectre (Variant 2) on centriq 2400, so this brand new CPU is not a valid alternative on short term. The very same applies to AMD Epyc and IBM Power. I don’t see any valid alternative in the nearby future. Am I missing something? Does anyone knows how to avoid Variant 2 in short term?
I’ve got no problems on my Burroughs 6700 out in the 2 car garage as it runs only lightly parsed highe level Burroughs Extended Algol and Other High level languages directly on the processor. All code and data are contained and run from data and code stacks with dedicated in the processor core/s hardware stack pointers, one for the top of stack and another that delimits the bottom of stack. No user space code that overflows or underflows these Processor/OS managed stack(TOS, BOS)pointers will be allowed to continue running as any pushing and poping beyond the stack limits generates a hardware interrupt and the MCP(OS) will promptly stop execution. Ditto for other code running on the stack machne architecture.
The only issue I have is the space taken up by all those Cabinets/Tape Drives/Others and a washing machine sized Head-Per-Track hard dive(Single Large Spinning platter) for paging swap on that old mainframe. But that Stack Machine architecture is ageless so maybe someone will give it some FPGA treatment or an ASIC tape out in a microprocessor format and stress test that Stack Machine Architecture against the Microprocessors that are currently very loosely based on the modified Harvard CPU microarchitecture with all those security problems that dominate the market currently.
That Stack Machine microarchitecture is ready made for safely running high level Object Oriented and Procedural language code directly on the Stack Processors hardware and that really needs to be stress tested against that error prone fully compiled down to machine language code that is not so safely executed on those current microprocessors that are very loosely based on the modified Harvard microarchitecture.
New CPU architectures need to be devised and old ones looked at including that old Burroughs Stack mahine architecture as well as others because what we have today just will not do if the underlying hardware/microcode is so complex that it can never be full vetted for security.
Spectre and Meltdown increase the consideration of AMD EPYC, Cavium ThunderX2, Qualcomm Centriq 2400, and IBM POWER9 as viable alternatives to Intel Xeon because IT no longer sees Intel Xeon as one homogeneous set of processors to be managed as a single unit. Increasing the management complexity for a heterogeneous Intel Xeon server farm (multiple generations, each with separate fixes) will introduce management automation tools that will enable enterprise and cloud IT to use whatever instruction set they want in a given server node.
All of the alternatives are susceptible to one degree or another, with Meltdown giving some slight differentiation. All of them are deploying fixes. Speculative and out-of-order execution don’t disqualify Intel Xeon or any of its competitors. There will be some slight second-order performance impacts, but everyone will work on optimizing the performance of their fixes throughout the year.
A level playing field is all an alternative processor manufacturer can ask for against a strong incumbent like Intel. This set of exploits is bad timing for Intel Xeon because we have a fresh batch of viable competitors on stage this year. With a level server management playing field, it will be up to each processor manufacturer to show their performance, power consumption, and total cost of ownership (TCO) advantage for a given workload or application. Fun times!
” it will be up to each processor manufacturer to show their performance, power consumption, and total cost of ownership (TCO) advantage for a given workload or application. Fun times!”
But Performance needs to be thought of in the post Meltdown/Spectre era. So the cost of mitigations need to be factored in. It may just be that for some a more secure processer that may be a little less performant may be the winner in the short term to middle term until the CPU development process can validate any new designs with all the problems fully fixed. I’ll bet that there is some server/cloud folks looking at the processors that may have no Meltdown issues to fix but still have one or more Spectre issues that will take time to fix due to the time it takes to validate/fully vett a new CPU design.
AMD this new Post Meltdown/Spectre world may just be your oyster for a few years compared to the others with more Meltdown concerns in addition to the Spectre concerns.