
The landscape of HPC storage performance measurement is littered with unrealistic expectations. While there are seemingly endless strings of benchmarks aimed at providing balanced metrics, these far too often come from the vendors themselves.
What is needed is an independent set of measurements for supercomputing storage environments that takes into account all of the many nuances of HPC (versus enterprise) setups. Of course, building such a benchmark suite is no simple task—and ranking the results is not an easy exercise either because there are a great many dependencies; differences between individual machines, networks, memory and I/O tricks in software, and so on. Still, one group is trying to both benchmark and rank—and their results for their first nine participants set the stage for the IO-500.
The impetus for the IO-500 goes beyond just resetting expectations for the sake of users that desperately try to tune to meet unattainable figures of projected performance—so called “hero numbers”. According to John Bent, one of the leads of the IO-500 storage performance benchmark and rankings, this hero numbers problem has made the RFP process difficult because those unrealistic “standards” get carried over as requirements that can never be met. This, in turn, becomes a vicious cycle as vendors then need to keep up false appearances stay in the RFP line.
Bent, along with colleagues Jay Lofstead from Sandia National Lab and Julian Kunkel from the German Climate Computing Center, have gathered the following results in a fashion similar to the Top 500, which of course is a single metric that ranks the top fastest supercomputers. This first incarnation of the list only features nine systems but like other new benchmarks in supercomputing (HPCG for instance) it will get new converts assuming there is compelling need.
So, with that out of the way, let’s look at the main benchmark results, which are a composite of measurements as detailed just below the results.
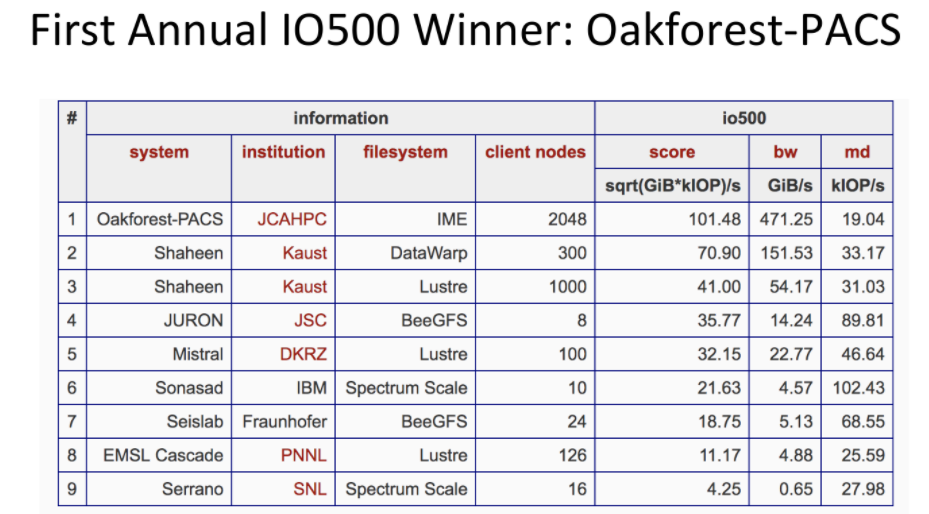

Here is where you might be confused on first glance. The list is touted as an “X”-500, which implies #1 is measurably differentiated than the ones below it. Even though some may take issue with the validity of the Top 500 for real-world work, few argue with the ranking metrics. They are static and measure one thing well—floating point performance. There are different system configurations that lead to better performance but those are generally front and center on the list (processor, interconnect, accelerator type, etc).
This ranking is less of a definite ranking and more of what Jay Lofstead says is a a way for different storage systems deployed both for production and development systems to get a comprehensive technique for comparing one system against another.“Our real goal is not a competitive list, but a way to get people to collaborate in a long-term research archive about various storage systems. We want to get documentation about the various storage devices and types deployed at various sites with benchmarks,” he adds.
In our conversation with Bent today, we asked how to interpret results when systems of similar size have far different rankings–even on a small list like this. For instance, see the Lustre clusters of similar size (100 and 126 nodes) with very different bandwidth and performance profiles? It would seem that these are should be roughly equivalent but again, with storage systems in HPC, so many factors play into overall outcomes that ranking these machines is a difficult task. This is where Lofstead steps in to explain that the ranking is more like a carrot for vendors. “In order to get sites to be willing to participate in the research database creation, the comparative list offers incentive. Our inaugural winner, along with the storage system vendor, now has marketing clout while the tests themselves have helped populate the database describing storage systems and related platforms along with the best practices on how to achieve hero-level performance.”
He says the IO-500 list offers a way for different storage systems deployed both for production and development systems to get a comprehensive technique for comparing one system against another. “Our real goal is not a competitive list, but a way to get people to collaborate in a long-term research archive about various storage systems. We want to get documentation about the various storage devices and types deployed at various sites with benchmarks.”
There are four sets of tests that are combined into the single overall ranking, the results of which are listed below (and may actually be more useful for those looking to balance a storage system against specific workload demands in terms of bandwidth or overall IOPs capabilities. “We have bandwidth and metadata tests designed to be pathologically bad to see what the worst case should be. On the flip side, we have the corresponding easy tests for bandwidth and metadata where we encourage sites to ‘game’ the tests—with a catch. In order to have a result be accepted, you have to run the 4 benchmark sets along with your settings and any non-standard tools used for the easy tests. This information with documentation about the storage system and compute nodes that we can compare them is what is important.
The initial creation/writing tests are required to run for 5 minutes. This is attempting to represent the required 90% forward progress requirement DOE, and others, have in their platform acquisition RFP. The reading/consumption parts are allowed to run in any time.
“While the initial benchmark some claim is not comprehensive enough since it focuses on simulation and engineering workloads, this does parallel the Top500 list and addresses the hardest type of storage acquisitions. Additional benchmarks to address data intensive workloads, such as Hadoop or other read-intensive applications, are either easier or we do not have adequate benchmarks. For example, a lot of work is done to distribute data for Hadoop-hosted processing, but the situations they work best for varies widely. A single benchmark that represents all of these isn’t defined well. Additionally, the node-local reading does not tax a central storage service and can scale infinitely based on the number of nodes. Finding a reasonable way to compare that isn’t just asking which technology works best on a single node, we don’t know.”
The Virtual Institute of I/O, or VI4IO, is the host for IO-500, is seeking to expand the additional benchmarks we ask users to run as part of the IO-500 tests. As the community coalesces some benchmark being important and widely accepted as representative for some important workload(s), the core tests may expand. For now, such as the next 2 years, we want to keep things stable as the community discusses how to expand the comprehensive view of storage with additional benchmarks.The IO-500 page offers a completely searchable and sortable way to dig through the all of the list so users can figure out which systems work best for different kinds of workloads. All of the data, including all settings and code used for the hero-level results, are available to the public. This will drive back into the research community to improve IO and storage, says Lofstead.
More on this burgeoning benchmark, which will be presented bi-annually (SC and ISC) can be found here. There is a great deal of detail in the team’s presentations that we could not represent here for brevity’s sake. The team has a mailing list and other contact opportunties on their site.

Be the first to comment