

Based on datacenter practices of the past two decades, it is a matter of faith that it is always better to run a large number of applications on a given set of generic infrastructure than it is to have highly tuned machines running specific workloads. Siloed applications on separate machines are a thing of the past. However, depending on how Moore’s Law progresses (or doesn’t) and how the software stacks shake out for various workloads, organizations might be running applications on systems with very different architectures, either in a siloed, standalone fashion or across a complex workflow that links the systems together to create an application of applications on a system of systems.
It is with this in mind that we consider the possible converged or diverged futures of two key workloads that represent the upper echelons of computing: high performance computing (HPC) and deep learning.
Traditional HPC workloads are largely represented by simulation and modeling of physical phenomena using parallel applications written in Fortran and C++, and glued together using the Message Passing Interface (MPI) protocol that enables these applications to scale out and drive performance; there is also a smattering of financial modeling applications, which are generally written in Java with their own messaging layers. These applications have been around for decades and have been the canonical high performance of computing.
Similarly, artificial intelligence (AI) has been around for many decades, and even the deep learning algorithms that have been expanded by the hyperscalers like Google, Amazon, Baidu, and Microsoft are not new. What is new, and what has made deep learning actually work, is the combination of enough parallel computing firepower at the right price, thanks to GPU computing (particularly Nvidia’s Tesla compute engines) and of very large datasets that turbocharge machine learning algorithms.
Traditional HPC applications started out on workstations and then moved to clusters. They always worked, even if they were initially limited by scale. Deep learning algorithms are bumping up against their own scale limits, but the brightest minds in AI software and hardware are striving to circumvent machine learning scale issues, and it is likely that machine learning frameworks will be bolstered by borrowing MPI from the HPC community, much like how deep learning researchers borrowed GPU-accelerated system architecture – which got its start in 2007 – from the HPC arena some five years later.
Given the nascent nature of deep learning, and the even younger markets for GPU-accelerated databases, it is natural to wonder if there is some way to converge HPC and AI workloads onto a single set of infrastructure. It may be too early to tell, Vineeth Ram, vice president of HPC and AI portfolio marketing at Hewlett Packard Enterprise, tells The Next Platform. But HPE is making sure it has a portfolio of systems and networking options that is wide enough and deep enough to take customers whatever direction they need to go.
Last year’s acquisition of supercomputer maker SGI, which has had its share of machine learning and data analytics contracts for its parallel cluster ICE XA and shared memory HPE Integrity MC990X systems, was made precisely to bolster HPE’s position in both the HPC and AI markets and to provide the company a hedge for the possible future paths that both HPC and AI take.
“There are a few different facets of artificial intelligence,” says Ram. “There is a connection between data analytics and machine learning in this shift to making things more predictive as an enterprise use case, but this is not quite the simulation- and modeling-intensive HPC that we know. The use case that is much closer to HPC is deep learning, which is a subset of machine learning. The fact is, simulations keep generating more data, and you have to make sense of it and take action on it. Deep learning is a significant help in that regard. On the other side, enterprise possess troves of big data, and if they utilize deep learning and train their models across this data, they can distill it into small amounts encapsulated in the inference algorithms. Simulation- and modeling-related HPC workloads typically start with relatively small data sets that swell during multiple runs of complex simulations. Meanwhile, deep learning is all about condensing massive amounts of data with training models into specific algorithms that are used for inferencing. Yet there are areas where these converge, such as using simulated data to feed a neural network model, or to use a neural network to feed a simulation. In either case, you build the model and execute against it. Indeed, there are similarities in the two constructs, and we expect more interplay between HPC and AI in the future.”
It is this interplay that could end up driving system architectures that can do both well, or will produce systems that are tightly co-designed for either HPC or AI. It all comes down to use cases and cost.
This was certainly true in the HPC space. Very specialized machines, often called capability-class supercomputers, were created by Cray, IBM, SGI, Fujitsu, NEC, Sun Microsystems, and others that could scale to thousands of nodes running a few selected workloads –usually operated by the largest government-sponsored HPC centers in both civilian and military organizations. Academic and corporate HPC shops with modest-scale needs sometimes bought smaller versions of these capability-class machines; however, they often went with a more generic capacity-class machine that was designed more as a throughput engine for diverse applications with modest-scale needs. These were more appropriate for larger users.
The mere fact that a scalable cluster exists and can be used for new workloads is sometimes enough to fuel a revolution. If we have learned anything from enterprise Hadoop clusters doing data analytics, it is that a cluster starts with one workload in one line of business. Once another line of business learns of its success, the two lines share their data and cluster, and they both benefit. Then more datasets are added, more applications are created across the business, and before you know it, the Hadoop cluster is a shared utility for the entire business with hundreds to thousands of nodes.
All distributed computing platforms evolve based on their portfolio of use cases. The idea is to spread the cost over the greatest number of users and applications to keep the clusters as busy as possible and to recoup as much of the investment as possible.
In HPC and AI scenarios (using the HPE system portfolio as an example), a company can decide to offload some workloads to an HPE Integrity MC990 X (formerly called SGI UV 300), or HPE Integrity Superdome X shared memory system. Meanwhile, another set of code could be on CPU-GPU hybrids with the densest compute, and applications that are largely driven by storage might belong on the cheapest CPU clusters with greater flash and disk capacity and a modest number of GPU enclosures for acceleration on some of the nodes. Alternatively, customers may choose to determine the greatest or lowest common denominator and standardize on one hardware spec because it lowers unit cost and simplifies management.
As enterprises plot their HPC and AI courses, two HPC systems embody the possible paths: the “Bridges” system at the Pittsburgh Supercomputing Center (PSC) and the Tsubame 3.0 supercomputer at the Tokyo Institute of Technology.
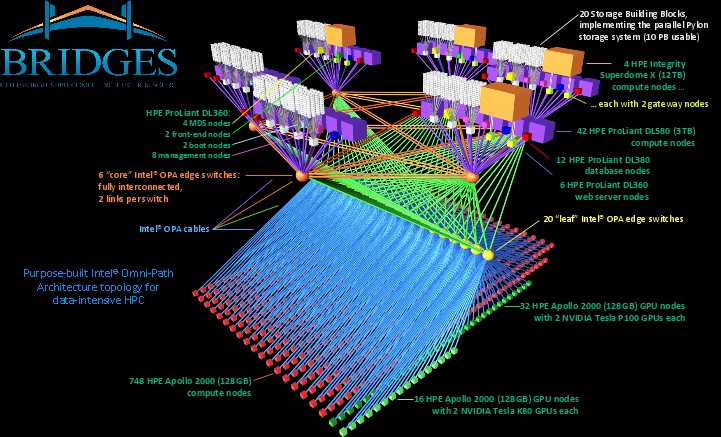
With the Bridges system, the PSC run by Carnegie Mellon University and the University of Pittsburgh is focused on the convergence of HPC, data analytics, and AI, but the system architects were not convinced that a homogenous architecture was the right way to go.
PSC was always a showcase for Compaq, and now for HPE supercomputing systems. Bridges continues this tradition. The $17.2 million Bridges system, which was funded by the National Science Foundation, has CPU compute and hybrid CPU-GPU compute nodes, supporting traditional Fortran and C++ HPC applications as well as popular analytics programming languages (such as R, MATLAB, and Python), and the batch Hadoop and in-memory Spark frameworks for analytics. The system is composed of five different compute elements, all lashed together using Intel’s Omni-Path interconnect. There are 748 of HPE’s Apollo 2000 nodes for CPU-only compute, plus another 16 nodes that have a pair of Nvidia Tesla K80 GPU accelerators and another 32 nodes that have the more recent Tesla P100 GPU accelerators. These are two-socket Xeon nodes with 128 GB of main memory. An additional 42 four-socket server nodes have 3 TB of memory each for a fat memory segment of the cluster, and for the big shared memory jobs where tighter NUMA interconnect technology is preferable to the looser MPI clustering that is used across the other nodes, there are four Superdome X systems that have 12 TB of memory each. The plan calls for PSC to use a combination of Xeon and “Knights Landing” Xeon Phi processors in the compute nodes.
PSC is striving to address a wide variety of memory capacities, compute elements, and performance for applications, not just build a homogeneous system with a fixed amount or type of compute. Bridges is, in essence, a cluster of clusters. HPE offers substantial portfolio choice and flexibility to meet the unique requirements of customers like PSC.
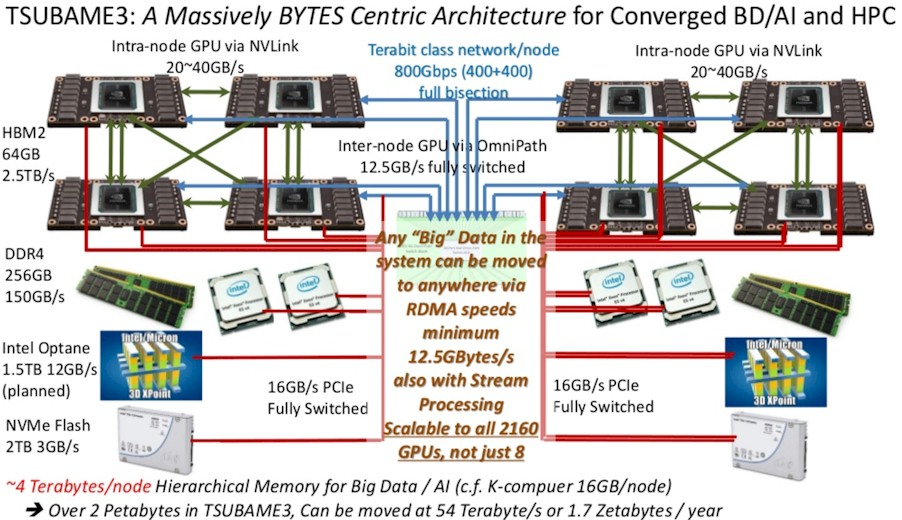
The Tsubame 3.0 system at Tokyo Institute of Technology is at the other end of the spectrum. Though similarly designed to be a machine for either HPC or AI work (or both, if these two types of applications interleave or converge), Tsubame 3.0 was built in conjunction with SGI – its contract was awarded just after HPE acquired the supercomputer maker last year. This cluster based on the HPE SGI 8600 system has 540 two-socket “Broadwell” Xeon nodes, each equipped with four of Nvidia’s “Pascal” Tesla P100 accelerators. The system has 256 GB of main memory and 2 TB of flash memory per node, with the nodes lashed together using Intel’s Omni-Path interconnect; the system links out to a 15.9 PB parallel file system running the Lustre file system from DataDirect networks.
While these two machines indicate possible architectural choices that new or practicing HPC and AI customers might take, many enterprises are relatively unfamiliar with these applications, particularly when it comes to emerging aspects of AI like deep learning. The SGI 8600 and Apollo 6000 Gen10 are purpose-built platforms for supercomputing and large commercial HPC to deliver a robust combination of performance, scalability, and efficiency. The HPE Apollo 6500 is optimized to maximize deep learning training performance with 8 GPUs per compute node, and the HPE Apollo 2000 offers a scalable solution for deep learning and HPC.
Customers looking to start out with something more modest might choose the new two-socket Apollo 10 Xeon servers, which have room for four GPU accelerators. This is a solid foundational solution because it is the least expensive compute platform with modest CPU compute density and modest GPU compute density. It also offers less thermal density, so customers can avoid retrofitting their datacenter with advanced cooling as is necessary with some HPC and AI systems. These customers might invest in a half or full rack of iron for a proof of concept before creating a roadmap as the workloads expand across use cases.
The point is, HPE has a wide range of iron to right-size an architecture to run and to scale lots of different modern workloads.


GPU Transitions, Aggressive Server Pricing Squeeze HPE Profits
Dell saw a sequential slump in server sales its most recent quarter as customers were awaiting access to systems using Nvidia’s “Blackwell” GPUs, and rival Hewlett Packard Enterprise had a similar issue when it turns in its first quarter of fiscal 2025, which ended in early February. But HPE apparently …
TSMC Will Have An AI Business Bigger Than All Of Intel Foundry
Everyone is in a big hurry to get the latest and greatest GPU accelerators to build generative AI platforms. Those who can’t get GPUs, or have custom devices that are better suited to their workloads than GPUs, deploy other kinds of accelerators. The companies designing these AI compute engines have …
A Deep Dive Into Datacenter And Server Spending Forecasts
Spending on AI systems in 2024 just utterly blew by the expectations of the major market researchers and those who dabble in metrics like we do. There has just been an unprecedented amount of spending, mostly for systems that are accelerated by Nvidia GPUs. It remains to be seen how …
Be the first to comment