

2011 marked ARM’s first step into the world of HPC with the European Mont-Blanc project. The premise was simple: leverage the energy efficiency of ARM-based mobile designs for high performance computing applications.
Unfortunately, making the leap from the mobile market to HPC was not an easy feat. Long time players in this space, such as Intel and IBM, hold home field advantage: that of legacy software. HPC-optimized libraries, compilers and applications were already present for these platforms. This was not, however, the case for ARM. Early adopters had to start, largely from scratch, porting and building an ecosystem with a fledgling HPC toolchain. Through partnerships with academic and industrial partners, the Mont-Blanc project tackled the initial work of building test systems and porting software for ARM HPC test systems.
In 2014, ARM began working as a subcontractor to Cray Supercomputer, as part of the US DoE FastForward-2 program. Leveraging numerous US and EU collaborative research projects such as FastForward-2 and ensuing phases of the Mont-Blanc project, along with a great deal of HPC targeted investment and planning, ARM and partners have strived to build a comprehensive ecosystem to support the HPC marketplace, complete with tools, compilers and specialized hardware. In 2017, the results are finally taking shape.
The first GoingARM workshop, hosted by ARM research at the ISC event in Frankfurt Germany, was designed to complement the ARM HPC Users Group and other similar events. It is intended to provide a forum to share ARM HPC information and experiences for everyone, from application programmers, to operating system maintainers, to hardware architects and system integrators. During the workshop, participants shared the state of the art in the ARM ecosystem as well as discussed challenges. From looking around the room, it was clear the workshop was significantly more popular than expected. During the entire day, there was standing room only, having throughout the day approximately 70 attendees. In spite of the crowded room, the audience stuck it out to hear from early users of SVE simulators (University of Michigan), application and runtime porters (BSC, AVL), ARM library and Allinea tool designers, RIKEN, Cavium and the lead on the Isambard project (University of Bristol).
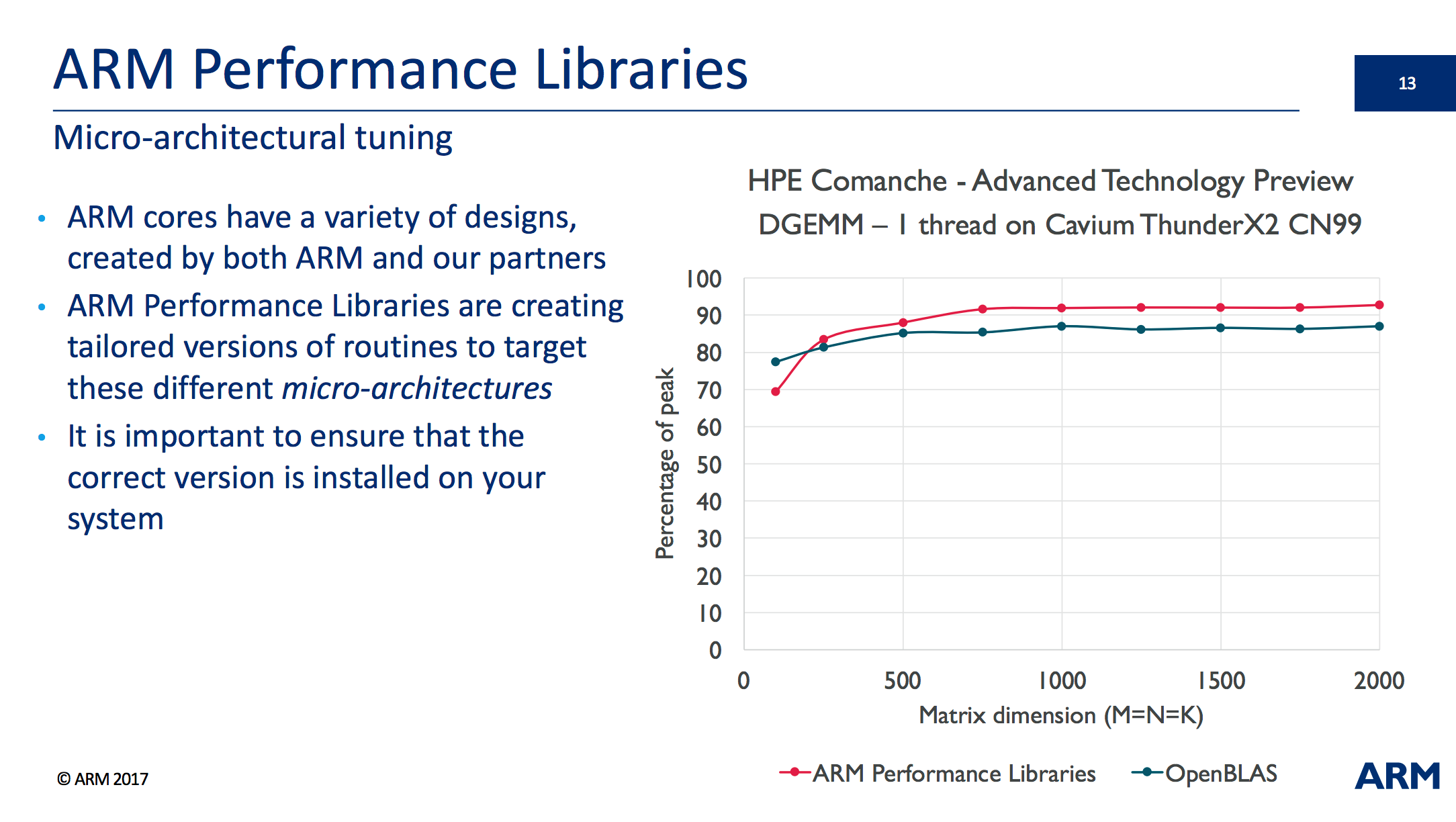
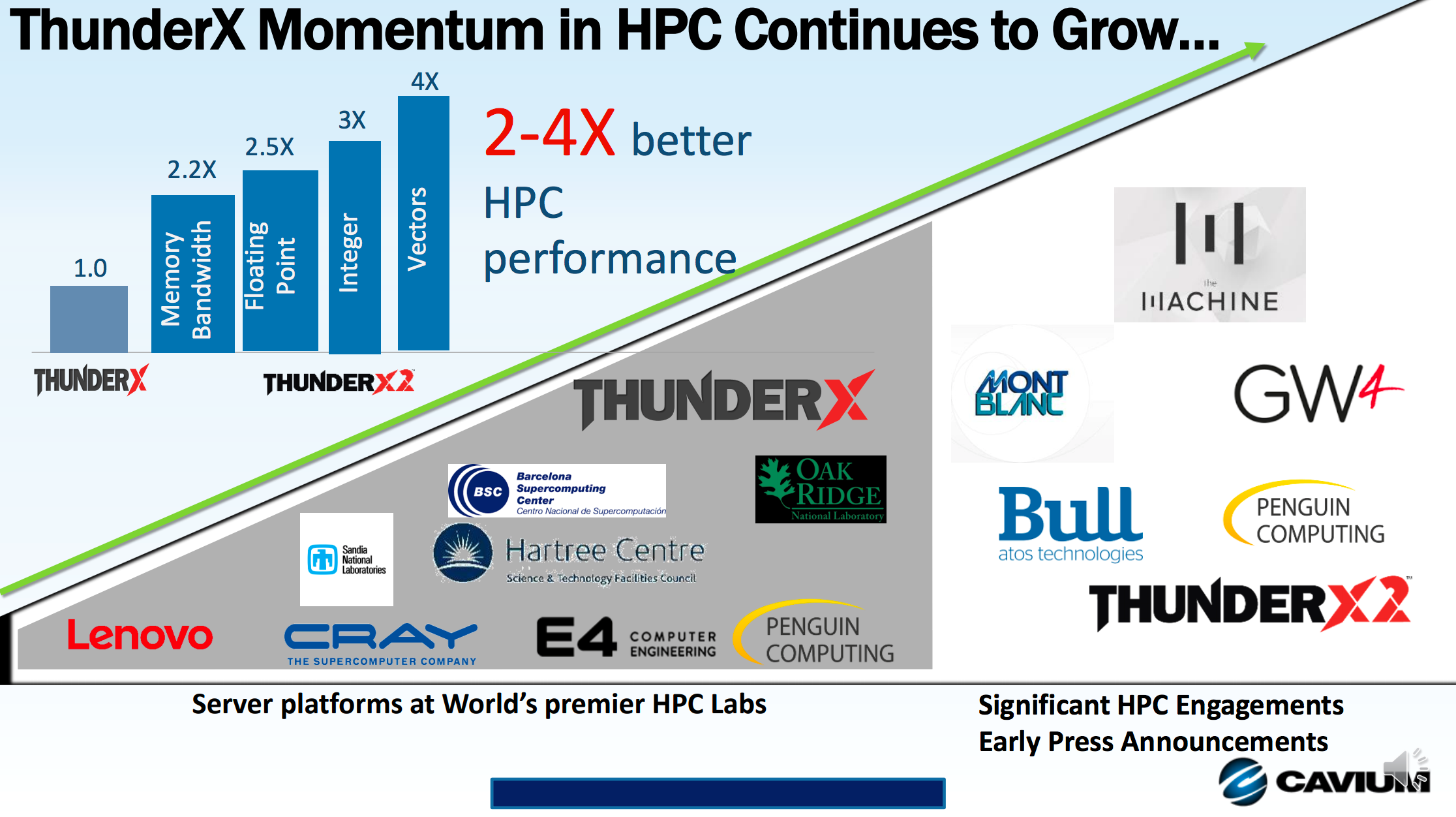
The first two speakers, Chris Goodyer (ARM) and Olly Perks (Allinea Software, now part of ARM) talked about the ARM Software libraries, ARM performance debugging tools, as well as widely used tools from Allinea Software that are now available on the ARM platform. Chris presented some early Cavium ThunderX2 results, with a relative comparison to OpenBLAS at single thread and then at 56 threads.
Olly presented the progress of Allinea tools development for the ARMv8 platform. The biggest questions and concern from the audience were around the continued support for all the other architectures Allinea supports. Olly re-assured the audience, by stating that “support and tool development for all other platforms will continue.”
The move to purchase Allinea Software, whose tools are widely used by many HPC centers, is seen by the ARM community as a sign that ARM is in the HPC space to stay for the long term.
Filippo Mantovani (of Barcelona Supercomputing Center) presented the Mont-Blanc project history, from the first Exynos-based test systems from several years ago, to the Mont-Blanc 3 Cavium ThunderX2-based demonstrator. The latest phase 3 system, codenamed “Dibona” has 48 compute nodes, each with 2-sockets with 32-core Cavium ThunderX2 processor cores, bringing the core count for the demonstrator system to 3,072 cores.
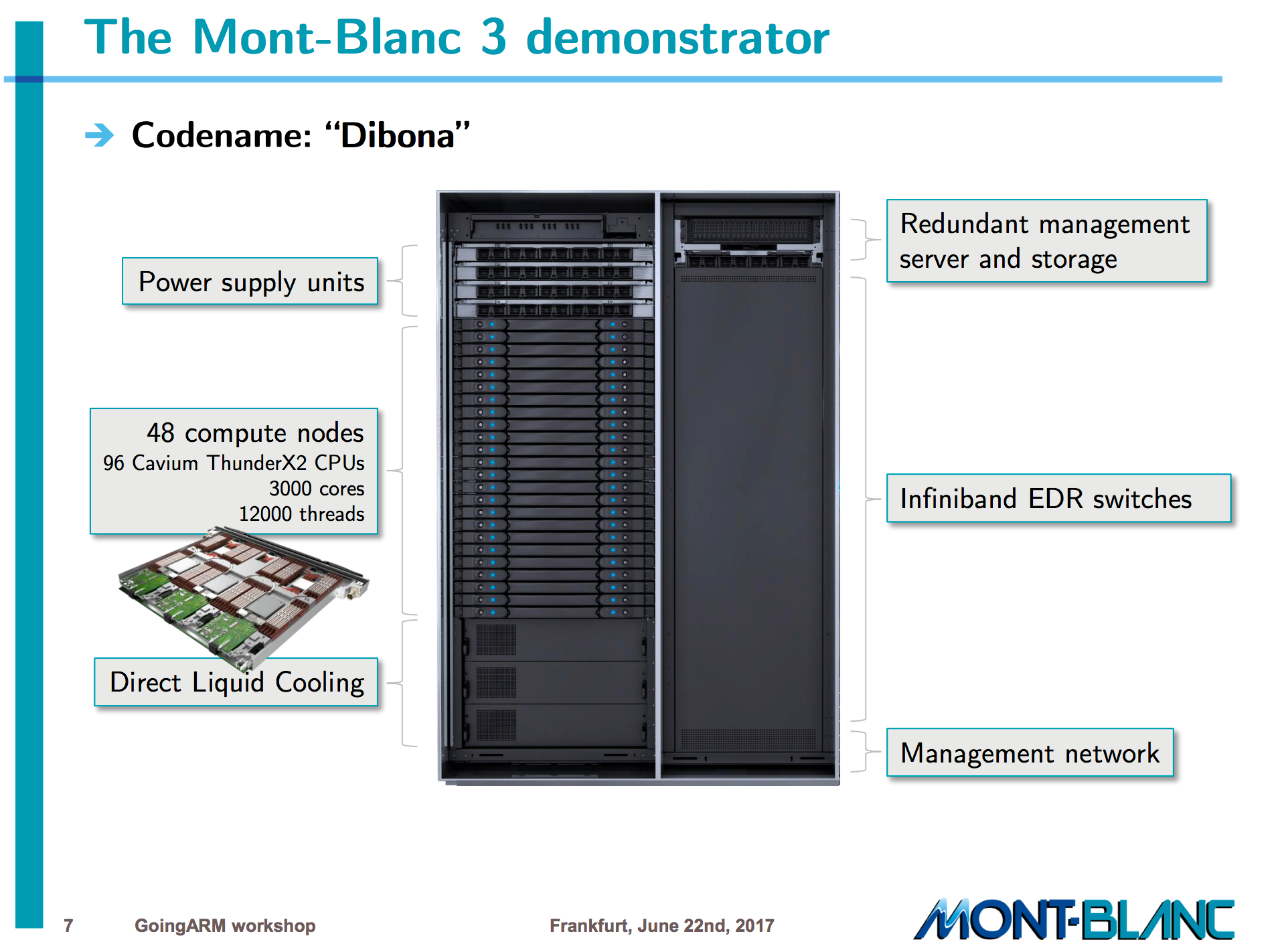
With 4-way SMT this brings the logical core count to 12,288. Each node is connected via an Infiniband fabric from Mellanox. The software stack, which has been in development as part of the Mont-Blanc effort since 2011 (and coordinated with OpenHPC), contains everything that an HPC system would need: BLAS libraries, MPI, OpenMP, performance and debugging tools. Current efforts include standardizing power measurement formats for energy-aware scheduling. To bring into the HPC world a new architecture takes massive effort. Fillipo showed a slide that outlined Mont-Blanc efforts from four separate research centers (AVL, BSC, HLRS, U. Graz) to bring up runtimes (OmpSs, OpenMP + MPI), and applications up to HPC-capable performance levels.
On the application side, Patrick Schiffmann from AVL presented his experience porting a Radial Basis Function Interpolation Solver (used, for example, for fast 3-D mesh refinement) from x86 to ARMv8. Porting software to a completely new ISA will be familiar for some embedded developers, but is not often done for scientific codes given the sensitivities of the code to changes. One contemporary example of such a move is from x86 and Power to GPGPU, however, the move to ARMv8 is far less drastic as the porting does not involve changing the entire programming style, language, and algorithms. One of the biggest issues faced, aside from unraveling chains of dependencies, when moving from x86 code to ARM code was the lack of standardization for vector intrinsic macros. Patrick says moving from AVX to Neon and now SVE takes time.
Last year we saw the official unveiling of ARM’s Scalable Vector Extension (SVE) at HotChips 2016. At GoingARM, we saw some of the first early performance results from simulated architectures equipped with SVE units. University of Michigan’s Jonathan Beaumont presented his work on porting genomics applications, specifically the Smith-Waterman algorithm, to ARM SVE. He gave more SVE code examples than have been publicly released to date, showing off not only how to write code with scalable vectors, but how to effectively use features such as per-lane predication. Jonathan gave scaling results for simulated SVE implementations ranging from a NEON-like 128-bit wide, all the way through 1024-bit wide vectors. One of the best numbers shown was a 38.2x speed-up over a base processor configuration, showing the difference that adding vector unit makes for sequence alignment applications. For his genomics examples, the 512-wide vector gave the best overall performance given the sequence lengths. He noted that larger hardware vector units favored longer sequence alignment problems, up until the point where memory became the bottleneck. Jonathan also gave a brief introduction to some current University of Michigan research on memory access coalescing, a technique he says could be adapted from GPGPU computing.
2016 saw the announcement of the Post-K computer by Fujitsu, in collaboration with RIKEN. Mitsuhisa Sato from RIKEN gave an overview of the application targets (a much wider set of scientific applications that many other HPC systems).
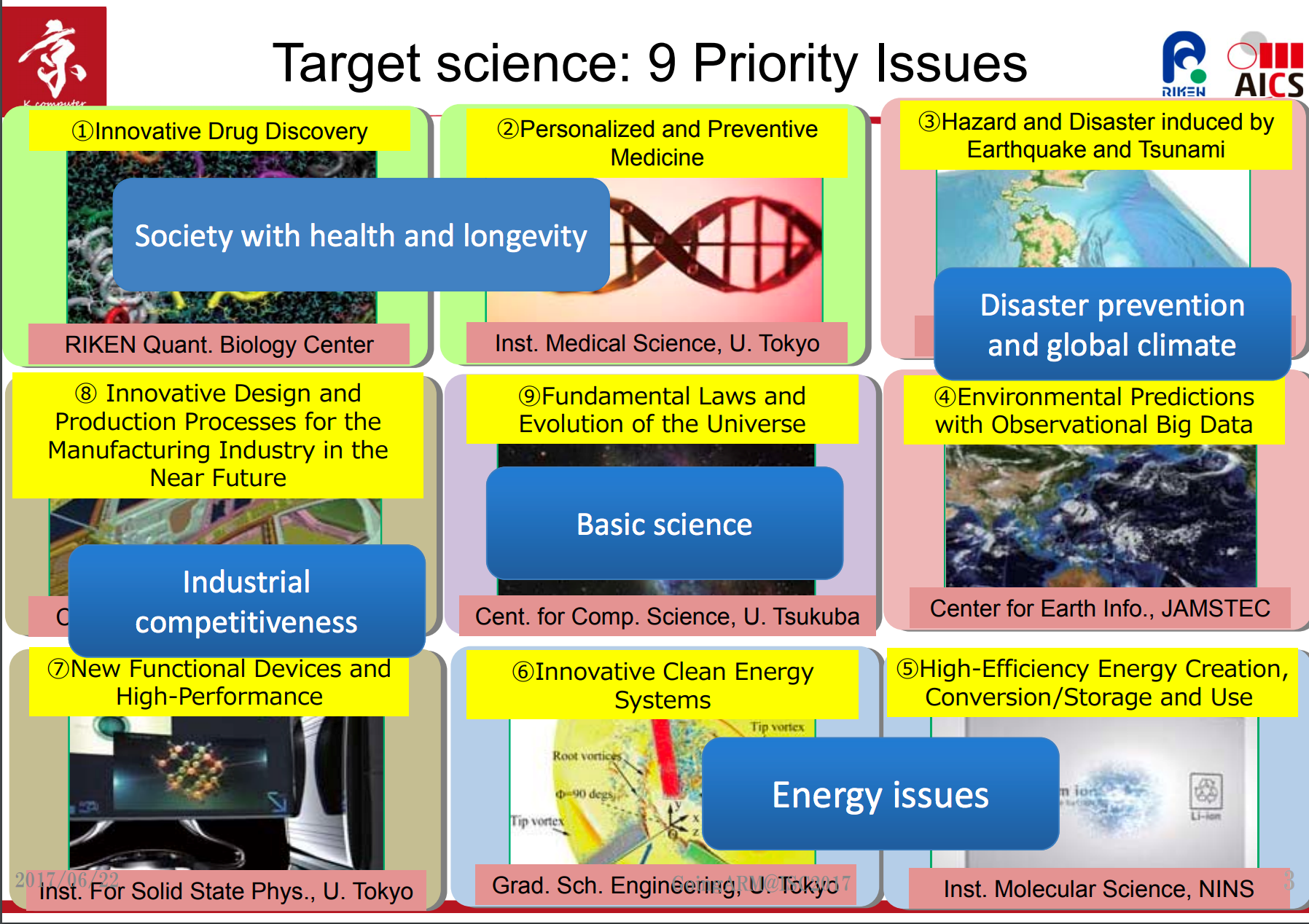
The wide range of applications used favors the same kind of balanced approach that brought Fujitsu to engineer the long-lived (operational as of 2011) performance of the current SPARC-based K-computer, which is still in the top ten of the world’s top 500 supercomputers (as of June 2017). Based on his slides, the Post-K machine is to be expected by 2021, Q3. As part of their evaluation, just as Mont-Blanc and FastForward-2 projects brought up many of the early stage ARM tools, RIKEN is heavily involved in developing the ARM toolchain to meet the needs of HPC. Specifically, RIKEN has been working towards optimizing compiler support for SVE vectorization. Along with Kyoto University, they have been evaluating compiler support from both ARM and Fujitsu and researching ways to enhance compiler emitted SIMD code through auto-vectorization and explicit SIMD programming directives.

Mitsuhisa had several questions at the end of his talk around the Softbank acquisition. The audience wanted to know what role the Softbank acquisition played in the choice of ARMv8 for Fujitsu. Roxana Rusitoru, one of the workshop organizers, intercepted this question to lay out a more accurate timeline. Much of the work that ARM had done with RIKEN and Fujitsu had been ongoing for years, prior to the announcement of the Post-K system. Any alignment between the system announcement and the SoftBank acquisition was purely coincidental. There was also a question around Brexit and EU funding projects for ARM. Roxana Rusitoru, the coordinator of the Mont-Blanc 3 Software Ecosystem work package, said that they have seen no changes in EU funding and that their commitment to European partnerships remains as strong as it has ever been.
A more recent large-scale deployment of an ARMv8-based production machine will be Isambard. As part of a collaborative effort, the UK’s Great Western-4 alliance of the universities of Bristol, Bath, Cardiff and Exeter, along with the Met Office and Cray U.K., has announced what will be the world’s first, large-scale production ARMv8 machine.

Simon McIntosh-Smith, leader of the Isambard project, says that more results will likely be available for public consumption at Supercomputing 2017 (Denver, CO). For testing and application porting purposes, they are currently using a Cavium ThunderX2 platform, however, as Simon stated for the main platform, “we haven’t announced the production core to be used”. For those wanting to try out Cavium hardware, according to Larry Wikelius (of Cavium), one of the best places try out a Cavium ThunderX system is packet.net, Packet provides bare metal ThunderX systems in the cloud. Simon McIntosh-Smith added that once the Isambard ARMv8 system becomes available, anybody can apply to request for time via a web form. Larry indicated that soon data centers will be able to purchase ARMv8 compatible systems from many vendors, not just one.
Only time will tell if the ARM architecture will be successful in driving vendor differentiation. The main hope of the HPC community is that the ARM ecosystem will increase the number of viable choices for HPC processor cores, breaking the single vendor lock-in of today. If the community enthusiasm is any indication, then ARM partners have a wide, receptive audience.
Editors Note: This non-sponsored article was written by two participants from ARM who were present at the workshop at the request of The Next Platform since editors were otherwise engaged during the ISC event.


Ruminations About Europe’s “Alice Recoque” Exascale Supercomputer
Designing chips and shepherding them through the foundry and package and assembly is a complex and difficult process, and not having these skills at a national level has profound implications for the competitiveness of those nations. In many ways, Europe behaves more like a nation than not, and this is …
AWS Boosts Memory Capacity On Graviton 4 Compute
UPDATED With its Graviton 4 homegrown Graviton 4 Arm server processors, Amazon Web Services has put into the field a CPU that can compete with all but the toppest of bin parts from AMD for X86 CPUs and Ampere Computing and Nvidia for Arm CPUs, and it is driving price/performance …
Arm Neoverse Roadmap Brings CPU Designs, But No Big Fat GPU
Spoiler alert! A lot of neat things have just been added to the Arm Neoverse datacenter compute roadmap, but one of them is not a datacenter-class, discrete GPU accelerator. And another one that is also not there is a more specific matrix math accelerator like the ones that Intel (well …
Be the first to comment