

In high performance computing, machine learning, and a growing set of other application areas, accelerated, heterogeneous systems are becoming the norm.
With that state come several parallel programming approaches; from OpenMP, OpenACC, OpenCL, CUDA, and others. The trick is choosing the right framework for maximum performance and efficiency—but also productivity.
There have been several studies comparing relative performance between the various frameworks over the last several years, but many take two head to head for compares on a single benchmark or application. A team from Linneaus University in Sweden took these comparisons a step further by developing a custom tool called CodeStat to gauge productivity by looking at the percentage of code lines needed to parallelize code for each framework and another, called x-MeterPU to track performance and energy consumption for OpenMP, OpenCL, CUDA, and OpenACC.
Using select applications from the SPEC Accel benchmark, which highlights performance for compute-intensive parallel workloads on accelerated systems and the Rodinia benchmark suite of applications the team tested developer productivity as well as application performance and efficiency for each of the frameworks on two separate single-node systems; one was a Xeon E5-based machine with Xeon Phi acceleration and another with GPU acceleration via a TitanX card. Arguably, these results are limited in scalability terms and the lower-end hardware (especially for the GPU side since a Tesla K80, for instance, would yield better performance, for example), but the productivity concepts they reveal are worth noting.

In terms of productivity for the application sets (including Lattice Boltzmann, 3D-Stencil, Breadth-First Search, HotSpot, and a CFD solver, among others) the team found, using their CodeStat tool, that OpenMP required 3.6X less effort compared to OpenCL and about 3.1X less than CUDA.
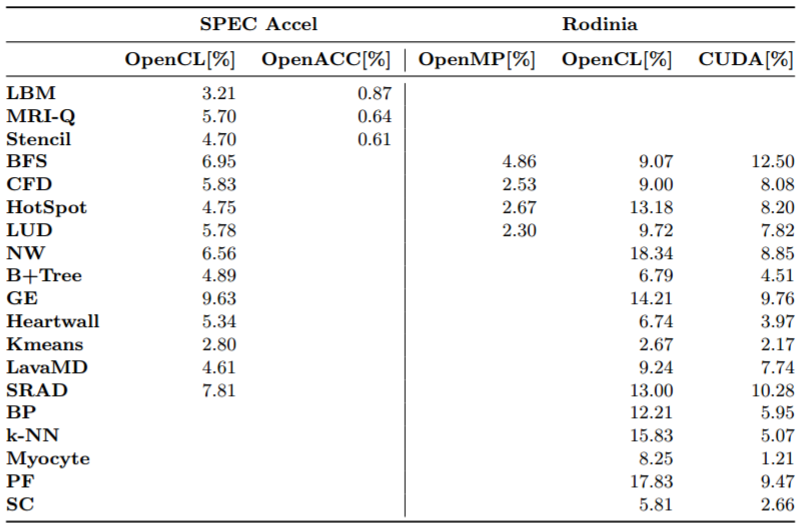
Drilling down, they say that programming with OpenCL required more effort than using OpenACC for the SPEC Accel benchmark and programming with OpenCL on average required 2X more effort than programming with CUDA for the Rodinia benchmark applications tested. “With respect to comparison between OpenCL and CUDA, on average, CUDA required 2X less programming effort than OpenCL.”
Those results get a bit murky with the layers of comparisons, but ultimately, OpenMP is the most productive approach, at least according to these results from single-node system tests. Of course, one also has to take into account human factors when it comes to parallelization productivity.
In terms of performance and efficiency, the team says the both performance and energy draw for OpenCL and CUDA are application dependent. For the Rodinia suite, OpenCL wins on some but others run more efficiently and higher performance with CUDA. They also note that for some of the applications, particular CFD, HotSpot, and LUD, using OpenMP on the Xeon Phi machines is far slower than with OpenCL, OpenMP, or CUDA on the GPU accelerated system. On that machine, performance and efficiency is roughly comparable across all three approaches. They also found that OpenCL performed better than OpenACC for the SPEC Accel benchmark applications selected.
As with nearly everything in high performance computing, “it all depends” is often the answer when it comes to finding the best approach. However, with the rise of accelerated machines handling applications as represented by these benchmarks, we can expect to see more fine-grained results over time comparing these approaches. Results highlighting new hardware will also shade the results, especially with the next-generation Knights Mill and successive Xeon Phi products and certainly with the addition of Pascal-based GPUs hitting more systems this year.


Wanted: A Complete – And Heavily Customizable – HPC Software Stack
Sponsored Feature. There are a lot of things that the HPC centers and hyperscalers of the world have in common, and one of them is their attitudes about software. They like to control as much of their systems software as they can because this allows them to squeeze as much …

Can SYCL Slice into Broader Supercomputing?
There are a few unignorable trends in high performance computing, especially in the exascale age. First, heterogenous and differing architectures at the major HPC sites are diverging with some using AMD CPUs and GPUs, others Nvidia, and of course, still others sticking with the well-tread Intel path. Second, codes are …

OpenACC Cozies Up To C, C++, and Fortran Standards
Not so long ago, there was a question whether exascale supercomputers would be built from a very large number of thin nodes containing only modest amounts of parallelism or a smaller number of fat nodes powered by specialized accelerators and powerful manycore processors. As PGI’s Michael Wolfe pointed out, the …
Two technical comments: First, OpenACC can be implemented for host parallelism or device parallelism. The PGI compilers certainly support this, though to be fair it doesn’t support both host and device parallelism at the same time. I don’t know if the Cray compiler also supports this, but there’s nothing in the language restricting this. Going further, I don’t know if any of the programming models allow a program to seamlessly spread parallel work (like a single parallel loop) across both host and device; that’s probably still a research topic.
Second, CUDA C is a C/C++ extension, but CUDA Fortran is also well-defined and quite popular for Fortran programmers that want to program GPUs at a lower level. PGI supports this, and you can search for ‘IBM CUDA Fortran’ to see a second implementation.