
Continued exponential growth of digital data of images, videos, and speech from sources such as social media and the internet-of-things is driving the need for analytics to make that data understandable and actionable.
Data analytics often rely on machine learning (ML) algorithms. Among ML algorithms, deep convolutional neural networks (DNNs) offer state-of-the-art accuracies for important image classification tasks and are becoming widely adopted.
At the recent International Symposium on Field Programmable Gate Arrays (ISFPGA), Dr. Eriko Nurvitadhi from Intel Accelerator Architecture Lab (AAL), presented research on Can FPGAs beat GPUs in Accelerating Next-Generation Deep Neural Networks. Their research evaluates emerging DNN algorithms on two generations of Intel FPGAs (Intel Arria10 and Intel Stratix 10) against the latest highest performance NVIDIA Titan X Pascal* Graphics Processing Unit (GPU).
Dr. Randy Huang, FPGA Architect, Intel Programmable Solutions Group, and one of the co-authors, states, “Deep learning is the most exciting field in AI because we have seen the greatest advancement and the most applications driven by deep learning. While AI and DNN research favors using GPUs, we found that there is a perfect fit between the application domain and Intel’s next generation FPGA architecture. We looked at upcoming FPGA technology advances, the rapid pace of innovation in DNN algorithms, and considered whether future high-performance FPGAs will outperform GPUs for next-generation DNNs. Our research found that FPGA performs very well in DNN research and can be applicable in research areas such as AI, big data or machine learning which requires analyzing large amounts of data. The tested Intel Stratix 10 FPGA outperforms the GPU when using pruned or compact data types versus full 32 bit floating point data (FP32). In addition to performance, FPGAs are powerful because they are adaptable and make it easy to implement changes by reusing an existing chip which lets a team go from an idea to prototype in six months—versus 18 months to build an ASIC.”
Neural network machine learning used in the test
Neural networks can be formulated as graphs of neurons interconnected by weighted edges. Each neuron and edge is associated with an activation value and weight, respectively. The graph is structured as layers of neurons. An example is shown in Figure 1.
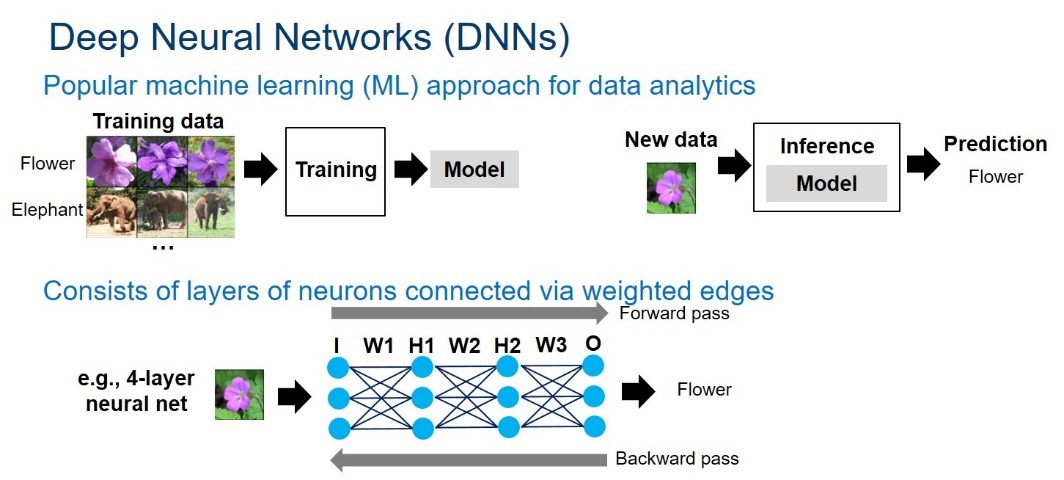
Figure 1. Overview of deep neural networks. Courtesy of Intel.
The neural network computation goes through each layer in the network. For a given layer, each neuron’s value is calculated by multiplying and accumulating the previous layer’s neuron values and edge weights. The computation heavily relies on multiply-accumulate operations. The DNN computation consists of forward and backward passes. The forward pass takes a sample at the input layer, goes through all hidden layers, and produces a prediction at the output layer. For inference, only the forward pass is needed to obtain a prediction for a given sample. For training, the prediction error from the forward pass is then fed back during the backward pass to update the network weights – this is called the back-propagation algorithm. Training iteratively does forward and backward passes to refine network weights until the desired accuracy is achieved.
Changes making FPGA a viable alternative
Hardware: While FPGAs provide superior energy efficiency (Performance/Watt) compared to high-end GPUs, they are not known for offering top peak floating-point performance. FPGA technology is advancing rapidly. The upcoming Intel Stratix 10 FPGA offers more than 5,000 hardened floating-point units (DSPs), over 28MB of on-chip RAMs (M20Ks), integration with high-bandwidth memories (up to 4x250GB/s/stack or 1TB/s), and improved frequency from the new HyperFlex technology. Intel FPGAs offer a comprehensive software ecosystem that ranges from low level Hardware Description languages to higher level software development environments with OpenCL, C, and C++. Intel will further align the FPGA with Intel’s machine learning ecosystem and traditional frameworks such as Caffe, which is offered today, and with others coming shortly, leveraging the MKL-DNN library. The Intel Stratix 10, based on 14nm Intel technology, has a peak of 9.2 TFLOP/s in FP32 throughput. In comparison, the latest Titan X Pascal GPU offers 11TFLOPs in FP32 throughput.
Emerging DNN Algorithms: Deeper networks have improved accuracy, but greatly increase the number of parameters and model sizes. This increases the computational, memory bandwidth, and storage demands. As such, the trends have shifted towards more efficient DNNs. An emerging trend is adoption of compact low precision data types, much less than 32-bits. 16-bit and 8-bit data types are becoming the new norm, as they are supported by DNN software frameworks (e.g., TensorFlow). Moreover, researchers have shown continued accuracy improvements for extremely low precision 2-bit ternary and 1-bit binary DNNs, where values are constraints to (0,+1,-1) or (+1,-1), respectively. Dr. Nurvitadhi co-authored a recent work that shows, for the first time, ternary DNN can achieve state-of-the-art (i.e., ResNet) accuracy for the well-known ImageNet dataset. Another emerging trend introduces sparsity (the presence of zeros) in DNN neurons and weights by techniques such as pruning, ReLU, and ternarization, which can lead to DNNs with ~50% to ~90% zeros. Since it is unnecessary to compute on such zero values, performance improvements can be achieved if the hardware that executes such sparse DNNs can skip zero computations efficiently.
The emerging low precision and sparse DNN algorithms offer orders of magnitude algorithmic efficiency improvement over the traditional dense FP32 DNNs, but they introduce irregular parallelism and custom data types which are difficult for GPUs to handle. In contrast, FPGAs are designed for extreme customizability and shine when running irregular parallelism and custom data types. Such trends make future FPGAs a viable platform for running DNN, AI and ML applications. “FPGA-specific Machine Learning algorithms have more head room,” states Huang. Figure 2 illustrates FPGA’s extreme customizability (2A), enabling efficient implementations of emerging DNNs (2B).
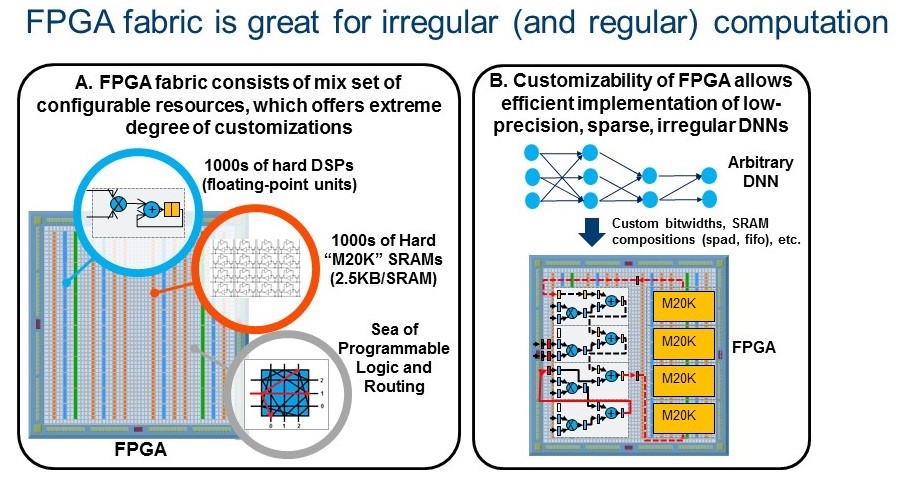
Figure 2. FPGAs are great for emerging DNNs.
Study hardware and methodology
| Type | Intel Arria 10 1150 FPGA | Intel Stratix 10 2800 FPGA | Titan X Pascal
GPU |
| Peak FP32 | 1.36 | 9.2 | 11 |
| On-chip
RAMs |
6.6 MB
(M20Ks) |
28.6 MB
(M20Ks) |
13.5 MB
(RF, SM, L2) |
| Memory BW | Assume same
as Titan X |
Assume same
as Titan X |
480 GB/s |
GPU: Used known library (cuBLAS) or framework (Torch with cuDNN)
FPGA: Estimated using Quartus Early Beta release and PowerPlay
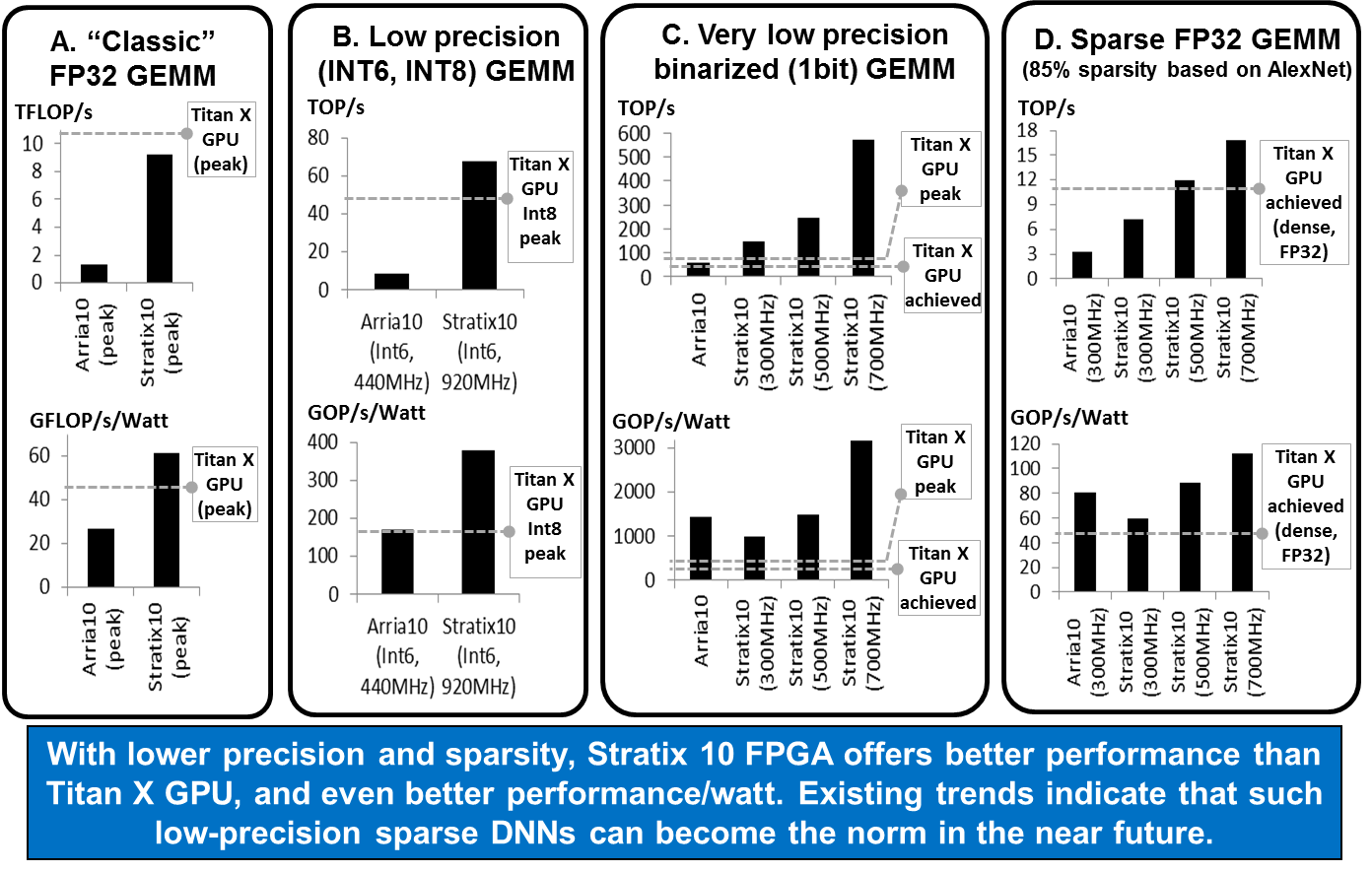
Figure 3. Results of Matrix Multiply (GEMM) test. GEMM is key operation in DNNs. Courtesy of Intel.
Study 1: Matrix multiply (GEMM) testing
DNNs rely heavily on matrix multiply operations (GEMM). Conventional DNNs rely on FP32 dense GEMM. However, lower precision and sparse emerging DNNs rely on low-precision and/or sparse GEMMs. The Intel team evaluated these various GEMMs.
FP32 Dense GEMM: As FP32 dense GEMM is well studied, the team compared peak numbers on the FPGA and GPU datasheets. The peak theoretical performance of Titan X Pascal is 11 TFLOPs and 9.2 TFLOPs for Stratix 10. Figure 3A shows, Intel Stratix 10 with its far greater number of DSPs will offer much improved FP32 performance compared to the Intel Arria 10, bringing the Stratix 10 within striking distance to Titan X performance.
Low-Precision INT6 GEMM: To show the customizability benefits of FPGA, the team studied 6-bit (Int6) GEMM for FPGA by packing four int6 into a DSP block. For GPU, which does not natively support Int6, they used peak Int8 GPU performance for comparison. Figure 3B shows that Intel Stratix 10 performs better than the GPU. FPGAs offer even more compelling performance/watt than GPUs.
Very Low-Precision 1bit Binarized GEMM: Recent binarized DNNs proposed extremely compact 1bit data type that allows replacing multiplications with xnor and bitcounting operations, which are well-suited for FPGAs. Figure 3C shows the team’s binary GEMM test results, where FPGA substantially performed better than GPU (i.e., ~2x to ~10x across different frequency targets).
Sparse GEMM: Emerging sparse DNNs contain many zeros. The team tested a sparse GEMM on matrix with 85% zeros (chosen based on pruned AlexNet). The team tested a GEMM design that uses FPGA’s flexibility to skip zero computations in a fine-grained manner. The team also tested sparse GEMM on GPU, but found that performance was worse than performing dense GEMM on GPU (of same matrix size). The team’s sparse GEMM test (Figure 3D) shows that FPGA can perform better than GPU, depending on target FPGA frequency.
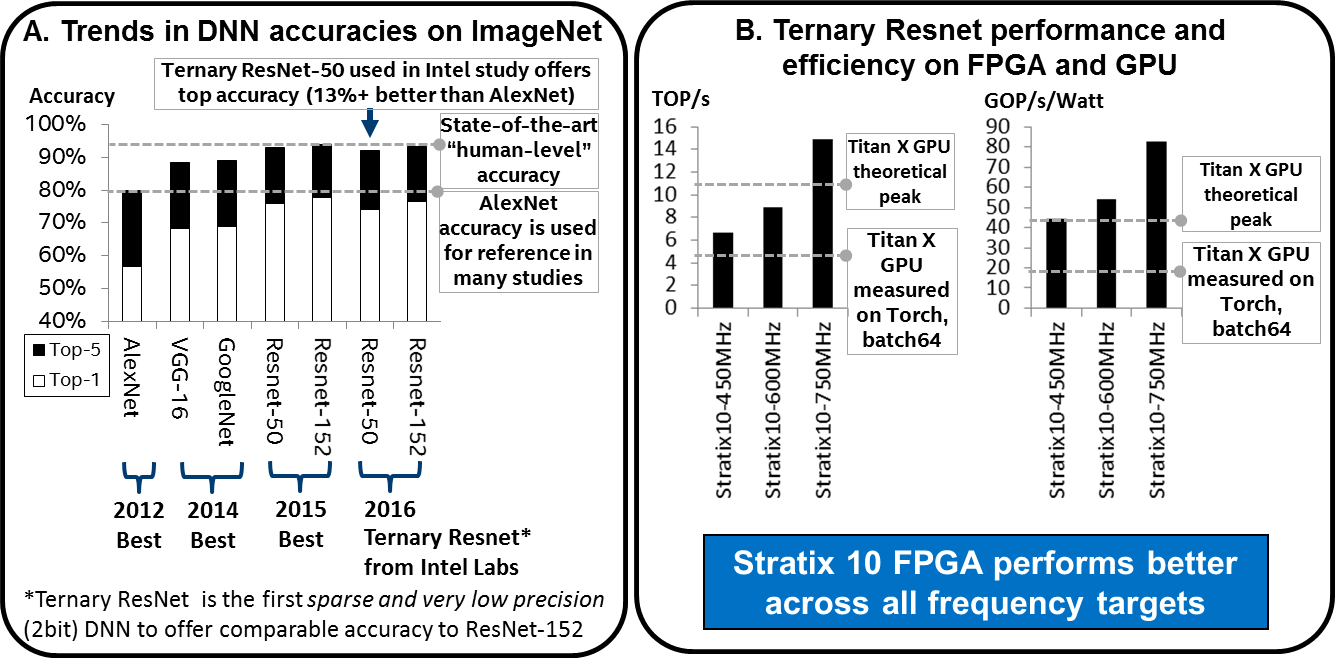
Figure 4. Trends in DNN Accuracies and Results FPGA and GPU testing on Ternary ResNet DNNs. Courtesy of Intel.
Study 2: Using Ternary ResNet DNNs testing
Ternary DNNs have recently proposed constraining neural network weights to +1, 0, or -1. This allows for sparse 2-bit weights and replacing multiplications with sign bit manipulations. In this test, the team used an FPGA design customized for zero skipping, 2-bit weight, and without multipliers to optimally run Ternary-ResNet DNNs.
Unlike many other low precision and sparse DNNs, ternary DNNs provide comparable accuracy to the state-of-the-art DNNs (i.e., ResNet), as shown in Figure 4A. “Many existing GPU and FPGA studies only target ‘good enough’ accuracy on ImageNet, which is based on AlexNet (proposed in 2012). The state-of-the-art Resnet (proposed in 2015) offers over 10 percent better accuracy than AlexNet. In late 2016, in another paper, we were the first to show that low precision and sparse ternary version DNN algorithm on Resnet could achieve within ~1% accuracy of full-precision ResNet. This ternary ResNet is our target in this FPGA study. So, we’re the first to show that FPGA can offer best-in-class (ResNet) ImageNet accuracy, and it can do it better than GPUs”, states Nurvitadhi.
The performance and performance/watt of Intel Stratix 10 FPGA and Titan X GPU for ResNet-50 is shown in Figure 4B. Even for the conservative performance estimate, Intel Stratix 10 FPGA is already ~60% better than achieved Titan X GPU performance. The moderate and aggressive estimates are even better (i.e., 2.1x and 3.5x speedups). Interestingly, the Intel Stratix 10 aggressive 750MHz estimate can deliver 35% better performance than theoretical peak Titan X performance. In terms of performance/watt, Intel Stratix 10 is 2.3x to 4.3x better than Titan X, across conservative to aggressive estimates.
How FPGAs stacked up in the research tests
The results show that Intel Stratix 10 FPGA is 10%, 50%, and 5.4x better in performance (TOP/sec) than Titan X Pascal GPU on GEMMs for sparse, Int6, and binarized DNNs, respectively. On Ternary-ResNet, the Stratix 10 FPGA can deliver 60% better performance over Titan X Pascal GPU, while being 2.3x better in performance/watt. The results indicate that FPGAs may become the platform of choice for accelerating next-generation DNNs.
The Future of FPGAs in Deep Neural Networks
Can FPGAs beat GPUs in performance for next-generation DNNs? Intel’s evaluation of various emerging DNNs on two generations of FPGAs (Intel Arria 10 and Intel Stratix 10) and the latest Titan X GPU shows that current trends in DNN algorithms may favor FPGAs, and that FPGAs may even offer superior performance. While the results described are from work done in 2016, the Intel team continues testing Intel FPGAs for modern DNN algorithms and optimizations (e.g., FFT/winograd math transforms, aggressive quantizations, compressions). The team also pointed out FPGA opportunities for other irregular applications beyond DNNs, and on latency sensitive applications like ADAS and industrial uses.
“The current ML problems using 32-bit dense matrix multiplication is where GPUs excel. We encourage other developers and researchers to join forces with us to reformulate machine learning problems to take advantage of the strength of FPGAs using smaller bit processing because FPGAs can adapt to shifts toward lower precision,” says Huang.
References
Can FPGAs beat GPUs in Accelerating Next-Generation Deep Neural Networks published in ACM Digital Library, February 2017.
This article was sourced via our relationship with Intel HPC editorial program.


Making Exascale Accessible To Everyone
Paid Post Intel has been at the forefront of democratizing high performance computing (HPC) for the past three decades, and the HPC leader is taking its efforts up several more notches with the Aurora exascale HPC and AI supercomputer being designed and built by Intel and Hewlett Packard Enterprise for …
Why TSMC Did A $100 Billion Deal With Trump On US Chip Manufacturing
All presidents of these United States have the bully pulpit from which to lecture the American people and, for the past century, the rest of the world about how the global economy and culture should work. Donald Trump has certainly used this pulpit in his first and now second terms …

Datacenter And Xilinx Power Through In Q4 And Beyond For AMD
Imagine, if you will, how troublesome AMD’s chip business would be at the end of 2022 had it not decided way back in 2015 to re-enter the datacenter with its Epyc processors. And imagine further how 2022 might have turned out – and how 2023 might be – if it …
I’m not convinced. FPGA’s may be more “customizable” and flexible than GPUs, but if some of the big machine learning companies agree that that Int4 or Int1 will be the precision of choice for future machine learning algorithms, is there anything stopping Nvidia from building GPUs that support Int4 or Int1?
Sure those won’t be useful for games, but neither is Int8, and Nvidia already uses it. If Nvidia thinks it needs to go lower than Int8 it will probably do so. Unless there is some fundamental issue with GPUs not being able to support less than 8-bit computation that I’m missing.
Until less than 8-bit computation is actually needed, these tests done by Intel and show “how much better its FPGAs are in those tests” seem to be mostly academic.
However, I do wonder if Intel intends to allow the FPGA business to cannibalize its Xeon Phi business, at least for machine learning tasks.
>>However, I do wonder if Intel intends to allow the FPGA business to cannibalize its Xeon Phi business, at least for machine learning tasks.
There is no Xeon Phi business for machine learning. Intel’s search for some thing move the needle w.r.t. GPU continues – Xeons, Xeon Phi, FPGA have failed. lets see if Nervana stuff can move the needle.
>> is there anything stopping Nvidia from building GPUs that support Int4 or Int1?
The point is that even if GPUs will support lower precision data types exclusively for AI, ML and DNN, they will still carry the big overhead of the graphics pipeline, hence lower efficiency than an FPGA (in terms of FLOPS/WATT). The winner? Dedicated AI processors, e.g. Google TPU
Yes there are very good reasons. They would have to split their design philosophy and that’s the big problem for nVidia always has been because adding such an amount of dead silicon for their primary usage (Graphics) to support lower bit ranges and the corresponding compute units will increase chip size tremendously unless they make special silicon.
Which is doable but that breaks their economic model which relies on economic of scale having basically the same chip design and simply switching off units/functions either via hardware or drivers to sell to a large area of market. I would say their graphics usage outsells their DNN usage currently easily by 1000:1.
If they make a special chip for just DNN they would have to sell it for probably 10x more then currently to regain the expanses which makes it unsalable product.
In other words
nVidia will be toast in the market just like they have been in the mobile sector.
The article claims that Titan X is the latest Pascal GPU, but it’s npt the highest end one.
The GP100 offers double the training speed with FP16 support and sits on HBM2 stacks that yields a much higher 768 GB/s bandwidth.
No one uses it though because nVidia asks way to much for ir.
Still more than 10x cheaper compared to state-of-art FPGA.
>> is there anything stopping Nvidia from building GPUs that support Int4 or Int1?
The point is that even if GPUs will support lower precision data types exclusively for AI, ML and DNN, they will still carry the big overhead of the graphics pipeline, hence lower efficiency than an FPGA (in terms of FLOPS/WATT). The winner? Dedicated AI processors, e.g. Google TPU
We should mention FPGA problems too.
LUT is basically just memory, which means that they are slow. Typical FPGA without hyperpipelining runs at around 500MHz (even 14nm Stratix10 did not improved it compared to 20nm). On the other hand, GPUs runs at 1,5-2,2 GHz.
These LUTs are usable if you are recunfiguring your design (in prototype phase). But do you really need to fully reconfigure your DNN so often? I don’t think so.
Hey Linda,
Really appreciate this article. It covers Intel’s research and approach really well. My feedback: I’d love to see more secondary reporting on how non-Intel AI researchers view all this. Eg. what do the FB and GOOGs of the world think of reduced precision? Do they plan to deploy these in their production services?
Thanks,
-James
I’m really surprised that there is no mention of Xilinx FPGAs – they have at least 1/2 of the high-end FPGA market, and they are literally not even mentioned. Also, the Xilinx ‘next gen’ UltraScale+ parts (that directly compete with the S10) are already in wide deployment with full functionality, while the S10 is still a paper tiger (i.e. it isn’t really out yet, aside from a select few marketing samples). Note – I’m not trying to argue Xilinx over Altera/Intel… just saying that this is more of an Intel platform perspective that real review of FPGAs.
The footnote might provide some clues as to why there was no mention of Xilinx FPGAs…
“This article was sourced via our relationship with Intel HPC editorial program.”
🙂
>> The team also tested sparse GEMM on GPU”
IMHO using cuSPARSE instead of cuBLAS would be more fair.
>> “what do the FB and GOOGs of the world think of reduced precision?”
“TPU is tailored to machine learning applications, allowing the chip to be more tolerant of reduced computational precision, which means it requires fewer transistors per operation.”
https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html
“Instead of 32-bit precision, the algorithms happily run with a reduced precision of 8 bits, so every transaction needs fewer transistors.”
https://techcrunch.com/2016/05/18/google-built-its-own-chips-to-expedite-its-machine-learning-algorithms/
The future of deep learning, whether in terms of FPGA or overall, depends primarily on scalability. For these technologies to successfully solve future problems, they must be extended to support the rapid growth of data scale and architecture. FPGA technology is adapting to this trend, and hardware is moving toward larger memory, smaller feature points, and better interconnectivity to accommodate multiple FPGA configurations.
As a recent graduate entering the workforce, I found the tips on building a personal brand extremely valuable. It’s something I hadn’t given much thought to before, but now I see its significance in establishing oneself professionally.