

The HPC community is trying to solve the critical compute challenges of next generation high performance computing and ARM considers itself well-positioned to act as a catalyst in this regard. Applications like machine learning and scientific computing are driving demands for orders of magnitude improvements in capacity, capability and efficiency to achieve exascale computing for next generation deployments.
ARM has been taking a co-design approach with the ecosystem from silicon to system design to application development to provide innovative solutions that address this challenge. The recent Allinea acquisition is one example of ARM’s commitment to HPC, but ARM has worked with the HPC community to develop compilers, libraries, and other key tools that are now available for ARM HPC deployments in 2017.
ARM first seriously ramped up its internal HPC-specific software development efforts in July 2014, when it acquired a new lab in Manchester, United Kingdom, expressly for the purpose of developing the software required to enable deployment of ARM supercomputers. ARM’s involvement in HPC started with the European Mont Blanc project back in late 2011, which built out the first large-scale ARM cluster and began the process of porting and tuning the required HPC software stack. At that time, the component parts were based on the leading 32-bit mobile phone technology with a focus on optimizing for performance per watt.
Fast forward five years, and the ARM chip story has advanced considerably with the arrival of 64-bit ARM chips and purpose-built server chip designs. At the Hot Chips conference in August 2016, ARM announced its first HPC-specific architectural extension – the Scalable Vector Extension for the 64-bit ARM architecture and Fujitsu confirmed that it will use SVE in the ARMv8-A compatible cores it is developing for the exascale Japanese Post-K supercomputer that is due to launch early in the next decade. Meanwhile, prior to SVE silicon being available, ARM partners are already producing chips for HPC. The Mont Blanc project has just announced that Atos will be using Cavium ThunderX2 processors to develop their large-scale ARM cluster and, the UK G4 Alliance (comprising the UK Universities of Bath, Bristol, Cardiff, and Exeter) revealed that their new Tier 2 Isambard supercomputer would be provided by Cray and comprise 10,000 ARM processors.
While the ARM Manchester team continues its remit to deliver the foundational software keys to the ARM HPC kingdom, including optimized compilers and libraries for ARM partner processors, it has been apparent that more critical mass in HPC software was needed for ARM to support future HPC deployments. At its HPC User Group meeting at Supercomputing 2016, ARM announced its initial release of OpenHPC and in December of 2016, ARM capped the year off by announcing its acquisition of Allinea, a leading designer of debug and analysis tools for many of today’s top 500 supercomputers. The Allinea acquisition rounds out ARM’s HPC team and software solutions with a UK business that has a long history and world-wide connections in the HPC market.
Stacking The Deck With Compilers And Parallel Runtimes
ARM co-develops its architecture alongside its compiler technology, to ensure that the new instructions can be exploited by high-level languages, as well as hand-written assembly. LLVM has become its compiler of choice for these internal activities, primarily because of its permissive licensing; the LLVM license allows ARM to release compilers to lead partners without being obligated to release the corresponding source code before publicly announcing the architectural extensions.
LLVM is also emerging as the standard compiler for both academic research and commercial products – the LLVM-based clang compiler is already the default system compiler for iOS, MacOS and Android operating systems, with others like ChromeOS also looking to make the switch from GCC, the Linux system compiler.
ARM has been using LLVM as the foundation of its embedded commercial compilers for some time and, in December 2016, announced its first commercial compiler suite targeted at application users, including an SVE variant.
From an HPC perspective, one of LLVM’s major shortcomings has been the lack of support for the Fortran language, still the first choice for many developers of scientific applications. ARM has confirmed that it is backing PGI’s efforts to open source its Fortran front-end and integrate it with LLVM, something that PGI spoke about in its keynote at the Third Workshop on the LLVM Compiler Infrastructure in HPC at SC16. Until then, the GNU gfortran compiler remains the open-source Fortran compiler of choice.
While LLVM is the primary vehicle for internal architecture/compiler co-development for SVE and ARM’s commercial compilers, ARM is also a major contributor to the GNU GCC project. Following the public announcement of SVE, ARM were quick to post public patches to add full SVE support to GNU binutils and GCC, as well as LLVM. There are blogs and whitepapers that describe how SVE works and how to use it effectively. From ARM’s recent talk at the LLVM Developer Meeting, LLVM experts can learn how ARM’s engineers enabled SVE’s innovative vector capabilities.
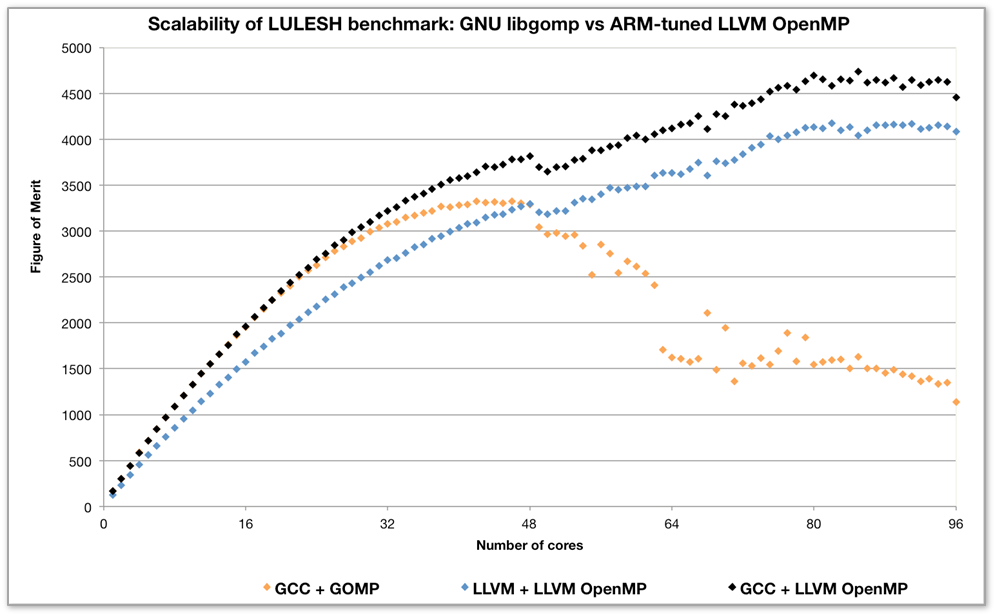
Users of ARM supercomputer nodes also see core counts that are much higher than those typically seen in the past on mobile platforms; for example, the Cavium ThunderX systems typically provide 96 cores per system, using two 48-core chips with a custom interconnect between the two chips. As a result, a lot of work is going into improving the scalability of parallel runtimes, which need to be tightly coordinated with the compiler to ensure that those cores can be utilized as effectively as possible. ARM showed how the popular HPC Lulesh benchmark now scales well with patches it has recently submitted to the LLVM OpenMP runtime, which now significantly outperforms libgomp, the equivalent GNU runtime. The patches provide better system topology awareness and improved support for locking primitives.
The LLVM OpenMP runtime has also been integrated with the GCC compiler, to produce a combination that delivers the best possible performance. The following chart shows how Lulesh performance scales as it runs across an increasing number of cores on a Cavium ThunderX-based dual-socket server – you can see the little dip at 48 cores when the workload starts to be split across the two chips for the first time, and the LLVM OpenMP runtime scales smoothly up to 96 cores, where libgomp quickly struggles and performance drops off significantly.
As ARM is a supplier of a computer architecture and supporting design IP, much work continues in order to advance the architecture for data-center and HPC workloads. In recent years, ARM has been delivering enhancements to the core ARMv8-A architecture (introduced in October 2011) on an approximately annual tick, designated 8.1 (December 2014), 8.2 (January 2016) and 8.3 (October 2016). For example, one key addition in 8.1 is support for a much richer set of atomic operations, which provide more efficient lock management capabilities, especially on larger systems.
The following chart shows how the Canneal benchmark (from the PARSEC suite) scales when using an LLVM OpenMP runtime that uses the original ARM 8.0 atomics, compared with a modified runtime (now upstreamed by ARM) that uses the new ARM 8.1 atomics.
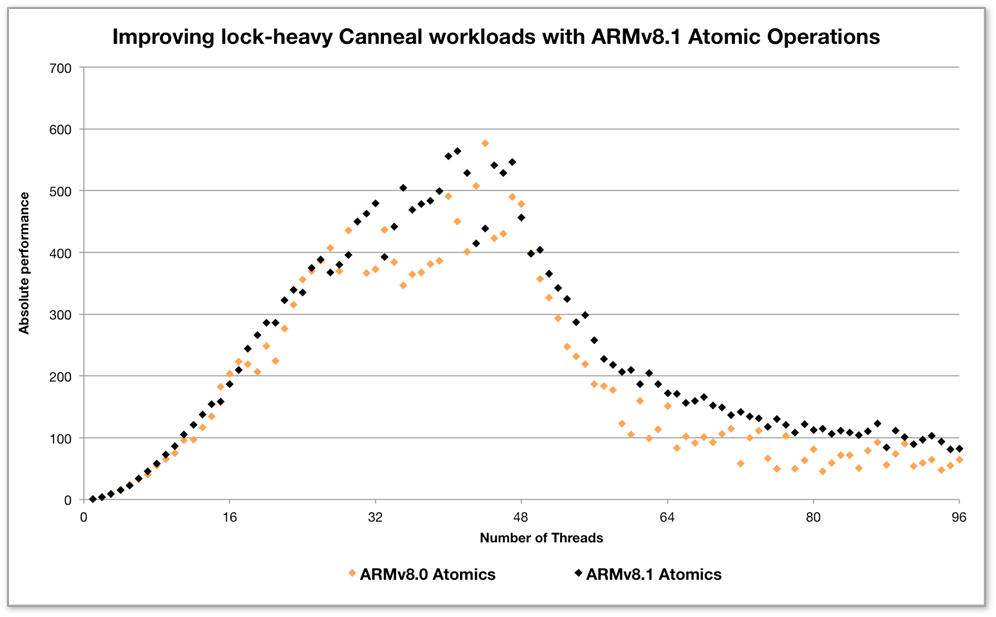
The size of the data set has deliberately been chosen so that at larger core counts, performance starts to be dominated by inter-thread communication, stressing the locking operations to the maximum extent possible. The use of the 8.1 atomic instructions seems to produce more predictable performance, and certainly improved performance at higher core counts, especially as we cross the point at which the system begins to utilize both of its sockets.
Placing Bets On Optimized Math Libraries
Another HPC ecosystem requirement was a high-quality, commercially-supported set of math libraries, and in November 2015 ARM released the first version of its ARM Performance Libraries product. The routines that it provides (BLAS, LAPACK and FFTs) may be unfamiliar to ARM’s mobile and embedded software developers, but they are the cornerstone of many scientific computing workloads, including the High Performance Linpack benchmark, upon which the Top500 supercomputer list is based. The most commonly used functions in the BLAS library (DGEMM and SGEMM, which are the double precision and single precision matrix multiplication routines) are also the key components of many emerging machine-learning algorithms, so the usefulness of these libraries extends beyond the HPC domain.
At the ARM User Group at Supercomputing 2016, ARM presented more details concerning the performance of its math libraries. The key metric for a DGEMM routine is the achieved percentage of “peak performance” – the performance theoretically achievable if all cores in a system were doing nothing but executing floating point operations at their fastest possible rate; 100 percent peak performance is only achievable if the CPU spends no time stalled on memory accesses or branch mispredictions, so high-quality implementations are often very heavily tuned to specific CPU cores. ARM presented its results as measured on one of its own Cortex-A57 implementations, as found in an AMD Opteron A1100 SoC design. The results show performance over 90 percent of peak for large data set sizes. By comparison, the open source OpenBLAS equivalent show performance up to 15 percent lower in parallel cases:
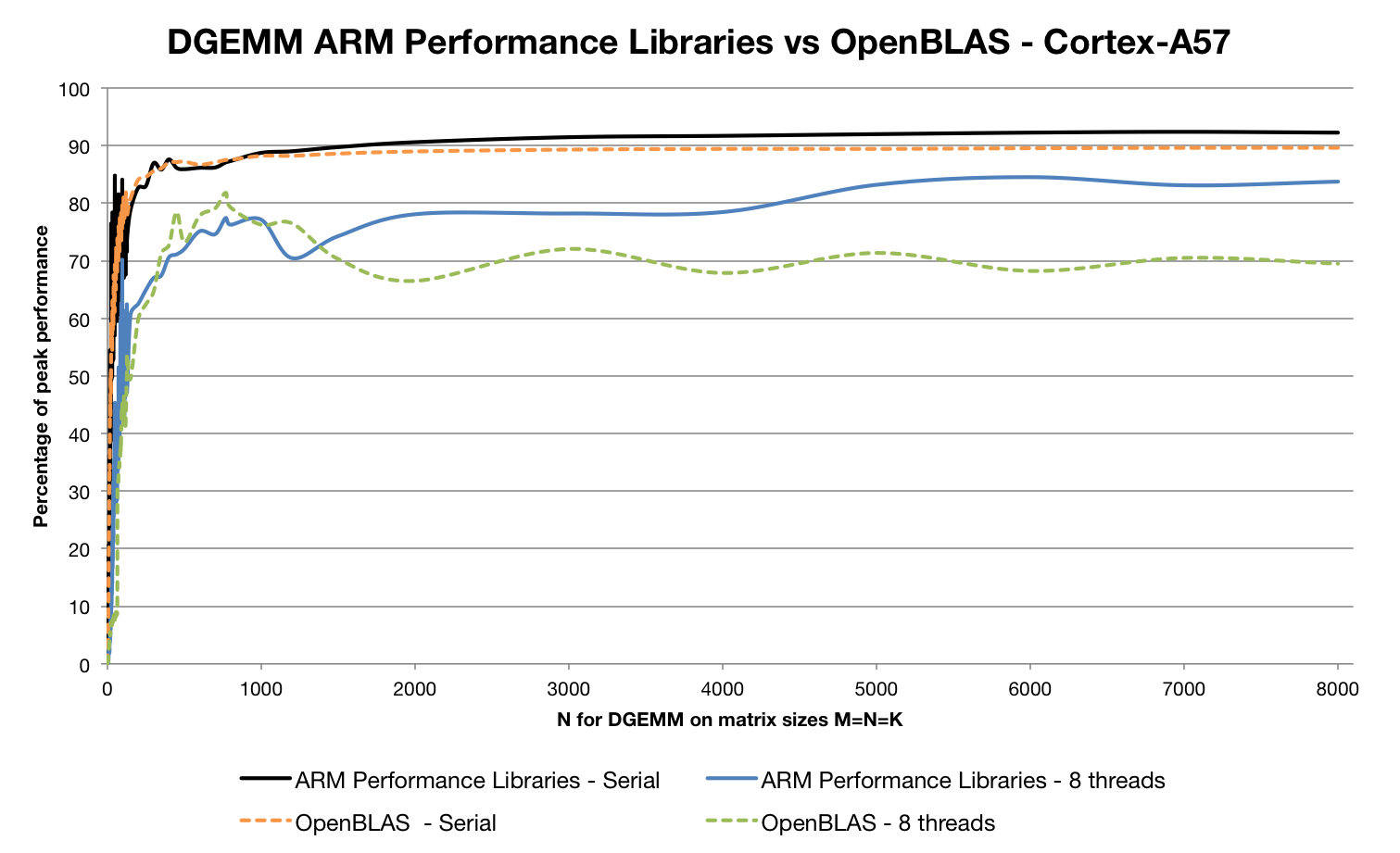
At the user group, ARM explained that there are a lot of different algorithms at work here – achieving high performance for small matrix sizes requires approaches that are very different to those required for large matrix sizes or in highly parallel environments.
“As the vendor math library for ARM HPC machines, we have lots of competing demands,” explained senior engineering manager, ARM HPC Software, Chris Goodyer. “Users have a range of hardware from different ARM partners, and are looking to run a wide range of cases in both serial and parallel. Micro-architectural differences, even between ARM’s own core designs, mean we have to implement different computational kernels for the same routine, which typically involves working with CPU modeling software to fine tune instruction placement, pre-fetch distance, blocking sizes and more.”
All In For Exascale With SVE Enablement
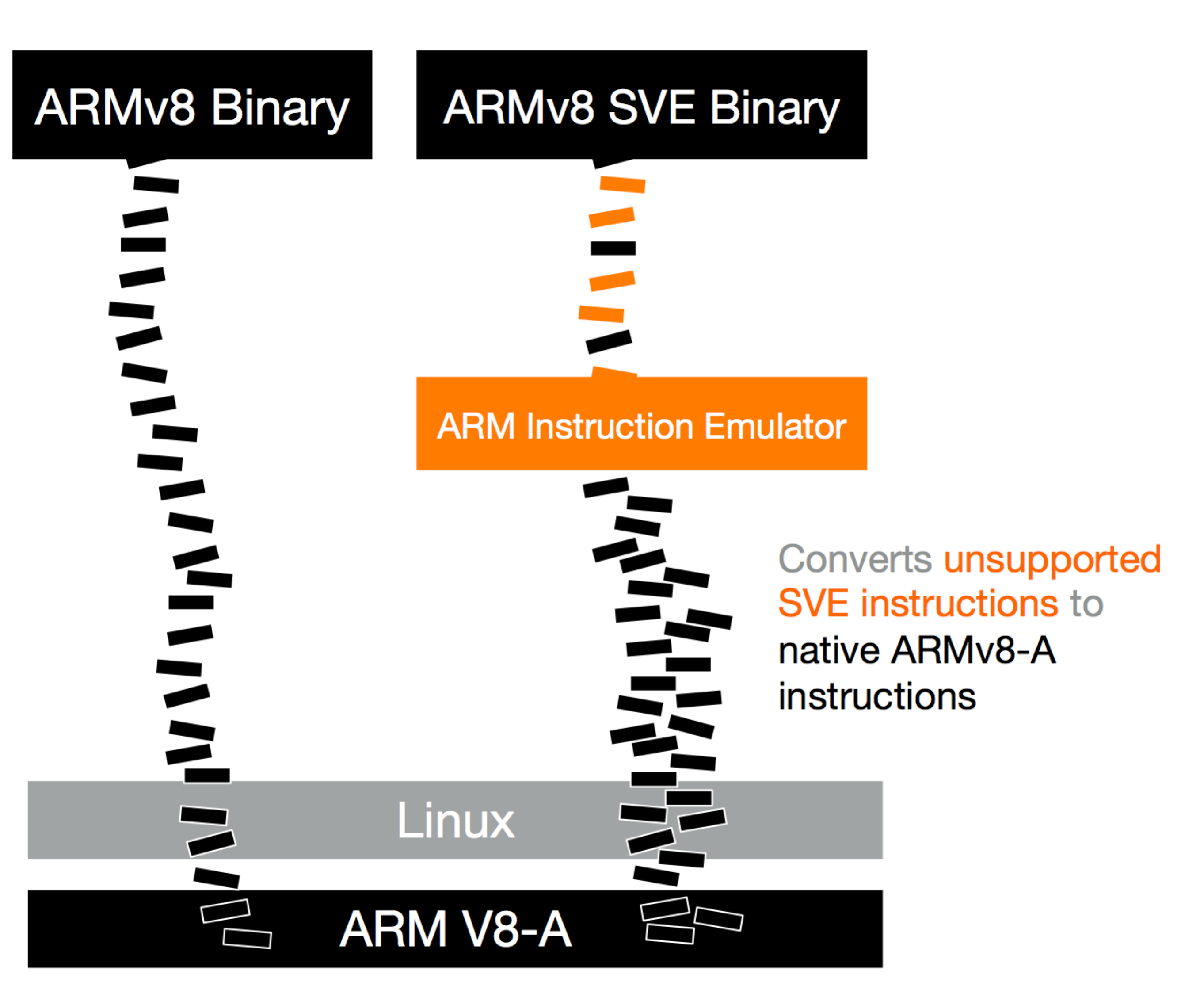
While supporting today’s ARM CPUs with its existing Advanced Neon SIMD Vector units, the tools announced at SC16 also fully support the new SVE architectural extension. ARM have packaged together the SVE Compiler and SVE-enabled ARM Performance Libraries (which includes SVE-enabled DGEMM and SGEMM routines), together with the ARM Instruction Emulator.
ARM Instruction Emulator is a new tool that allows application code containing SVE instructions to run on today’s ARM hardware without modification. SVE instructions are trapped and emulated, providing a means by which SVE code can be tested for functional correctness at high-speed, although there’s no accurate performance modelling in there right now – ARM’s existing Fast Models and Cycle Models products might be more appropriate for that today.
Doubling Down With Analysis Tools And Allinea
Supercomputing 2016 saw ARM talk about code analysis and advice tools for the first time, introducing a Beta version of ARM Code Advisor, which tightly integrates with the ARM Compiler and OpenMP runtime to provide the developers of scientific software with insight into how they can improve their code to ensure that it runs as well as possible on ARM.
Geraint North, distinguished engineer of ARM HPC Tools, explained why ARM HPC needs Code Advisor: “In the past, when a user moves to a new HPC system, it is often just more of the same, with fairly minor microarchitecture differences and larger scale. When users move to ARM, we recognize that they are significantly changing their architecture, their compilers, their libraries, and their runtimes, as well as often increasing their per-node core counts, and we need to provide tools that quickly let them understand where they need to focus their performance optimization efforts.”
Shortly after SC16, ARM announced the acquisition of Allinea, and integrating its multi-node debug (DDT) and profiling (MAP and Performance Reports) tools with the existing ARM HPC software portfolio would be a logical next step – Allinea’s tools have supported the ARM architecture for a few years now. To date, ARM’s debug and performance analysis tools have been focused on a single node – products such as DS-5 and Streamline are well-known to the embedded and mobile developers and those bringing up ARM SoC devices of all shapes and sizes, but as ARM supercomputer deployments begin in earnest, ARM needs tools like Allinea’s to ensure that application developers are able to optimize the performance of their codes as they run on the large clusters that are coming. Allinea’s tools already support the ARM CPU implementations available today, with SVE support on the roadmap.
Crucially, ARM has said that it will retain the cross-platform capabilities of Allinea’s tools, which support a broad set of platforms including the ARM, X86, and OpenPower CPU architectures, as well as Nvidia accelerators. This is vital if ARM is to keep its tools at the cutting-edge of supercomputing, as broad architecture support keeps Allinea installed on 80 percent of the world’s 25 largest supercomputers and will provide ARM with insight into the needs of the large HPC centers that will be deploying its architectures in the future.
Allinea’s tools are unique in their ability to debug and profile at extreme scale, attaching to applications running across tens of thousands of cores to provide the end-user with clear views of where an application is spending its time or where bugs might lie. Allinea have been laser-focused on ensuring that its tools are intuitive and straightforward, intended for use by computational scientists for whom HPC systems architecture may not be their primary background. This user-focused approach should transfer well into scientific computing’s adjacent domains of machine learning and big data analytics, where users are often also first and foremost domain experts, and for whom time profiling and debugging is time away from getting the real science done.
Darren Cepulis, datacenter architect and business segment manager for HPC at ARM Ltd.

Nvidia Unfolds GPU, Interconnect Roadmaps Out To 2027
There are many things that are unique about Nvidia at this point in the history of computing, networking, and graphics. But one of them is that it has so much money on hand right now, and such a lead in the generative AI market thanks to its architecture, engineering, and …
AWS Boosts Memory Capacity On Graviton 4 Compute
UPDATED With its Graviton 4 homegrown Graviton 4 Arm server processors, Amazon Web Services has put into the field a CPU that can compete with all but the toppest of bin parts from AMD for X86 CPUs and Ampere Computing and Nvidia for Arm CPUs, and it is driving price/performance …

AMD Finally Breaks The 10 Percent Server Share Barrier
History doesn’t really repeat itself, but it surely does use a lot of synonyms and rhymes, and sometimes, if you listen very closely, you can catch it muttering to itself. It is with this in mind that we contemplate the recent data coming out of Mercury Research, which is the …
Be the first to comment