

Conventional wisdom says that choosing between a GPU versus CPU architecture for running scientific visualization workloads or irregular code is easy. GPUs have long been the go-to solution, although recent research shows how the status quo could be shifting.
At SC 16 in Salt Lake City in a talk called CPUs versus GPUs, Dr. Aaron Knoll of the University of Utah, and Professor Hiroshi Nakashima of Kyoto University, presented comparisons of various CPU and GPU-based architectures running visualizations and irregular code. Notably, both researchers have found that Intel Xeon Phi processor-based systems show stand-out performance compared to GPUs for large scientific visualization workloads as well as for “regularized” irregular workloads.
For many years, people considered visualization a special use case for computer graphics that should be addressed using the same techniques as GPUs that are used for computer games. Over time, however, researchers have come to realize that many types of visualization and large-scale visualization are more like big data problems that are better suited to CPUs than compute-centric GPU architectures.
Dr. Aaron Knoll is intimately familiar with the evolution in thinking and approaches. Knoll researches ray tracing methods for large-scale visualization at the University of Utah’s Scientific Computing and Imaging (SCI) Institute, which also hosts the Utah Intel Parallel Computing Center (Intel PCC), along with the Intel Visualization Center. Knoll says that collective mission for collaborators across the organizations is to “modernize visualization and HPC with the help of Intel technology.”
Knoll and his colleagues have explored a range of large-scale visualization use cases leveraging combinations of OSPRay, Uintah, ViSUS and vl3 software against comparable GPU approaches. According to Knoll, the development of OSPray, an “open source, scalable and portable ray tracing engine for high-performance, high-fidelity visualization on Intel® architecture,”1 has been a game changer for scientific visualization. Especially given the fact that CPU-based systems are simply more widely available to scientists and that their memory provides distinct advantage for large-scale visualizations. In fact, as you’ll see in the research highlighted below, Knoll and his colleagues have demonstrated that while GPUs are great for small data and heavy compute workloads, CPUs and Intel Xeon Phi architectures are often better suited for large scientific visualization and memory-intensive workloads.
During the session titled Visualization Performance: CPU, GPU and Xeon Phi, Knoll highlighted some of the most compelling findings from the SCI and its various partners.
Polygonal rendering comparison
The two images below show a comparison of renderings for a large polygonal workload (170 million triangles) from ParaView and OpenGL versus Paraview and OSPRay with ambient occlusion. Knoll noted that not only is the lighting quality better in the OSPRay rendering, but it took about half as long to achieve the better result.


CPU ray tracing versus GPU rasterization
A recent comparison of OSPRay ray tracing versus OpenGL rasterization demonstrated that ray tracing is very competitive with rasterization—especially in the case of large-triangle data (316M RM) where OSPRay can run nearly 8x faster than rasterization. OSPRay was even 2x faster than OpenGL volume rendering in ParaView for large volume data (8 GB RM). For smaller volumes of data, Knoll said OSPRay was slower, but not by much.2
RBF volume rendering
One of the areas where Knoll and his colleagues are pushing the envelope of visualizations in new directions is with RBF volume rendering. Knoll said that trying to render data from raw points without having to convert them into structure volume representations has been a difficult problem for GPUs for years. He said that using an Intel Xeon Phi coprocessor system, his team achieved RBF volume rendering results up to 20x faster than a comparable GPU approach. Given those results, Knoll noted that there are now actually good reasons to use Intel Xeon Phi processors for visualizations.3
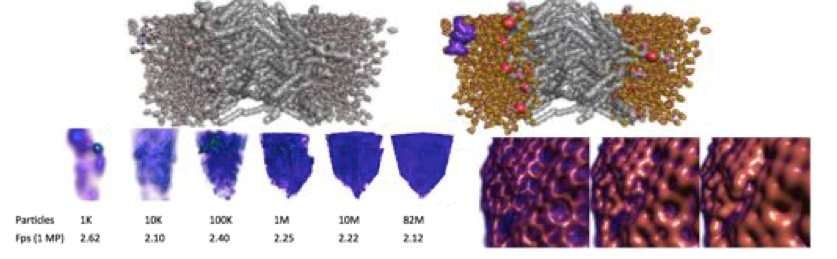
P-k-d Trees
Recently, Knoll and his colleagues have been exploring using OSPRay with P-k-d tree structures, which are a new approach for visualizing large particle data sets that builds off earlier balanced k-d tree approaches. P-k-d trees deliver similar performance to Embree BVH ray tracing approaches for less cost because the memory overhead is roughly 10 percent of standard BVH approaches. It does take about 30 percent longer to render visualizations in the P-k-d trees compared to BVH, but that’s still quite fast. Knoll explained that this is an interesting development because it is enabling researchers to use ray tracing for special purpose visualization techniques that support simultaneous data analysis, rather than simply as a general-purpose graphics technique.
One comparison Knoll has made, which he admits is not completely fair, is between a 72-core CPU workstation with 3 TB of shared memory using ray tracing versus a 128-GPU cluster with 1 TB of distributed memory doing rasterization to visualize two different but similar data sets of roughly 30 billion particles. Both datasets were roughly 500GB. The CPU delivered 50 megapixels or 50 rays per second4 while the GPU cluster delivered roughly 20 megapixels per second.6 Knoll said a newer generation of GPU cluster likely would have performed better, but the takeaway was that ray tracing does in fact make sense for extremely large data sets.
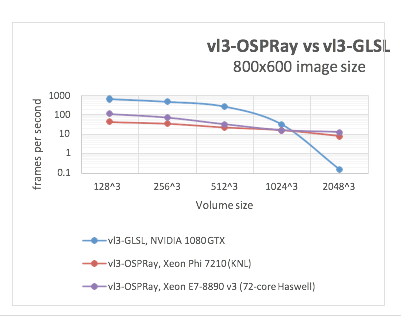
OSPRay on Xeon Phi processors versus GLSL on GPU
Knoll has done more of an apples-to-apples comparison of the vl3 distributed volume renderer and OSPRay on CPU and Intel Xeon Phi processor systems compared to vl3 and OSPRay on GLSL on a GPU system.
In this case, Knoll said that GPUs are markedly faster for small data sets, but with data volumes approaching 1K ^3, the performance gap narrows quickly. He said that once you are out of core or are going over the PCI bus, then Xeon Phi processors going over from DRAM to MCDRAM is probably two orders of magnitude faster than what the GPU can do going over the PCI bus.
In the end, Knoll said that he doesn’t think there is necessarily a better or worse choice for visualization codes, but that it is important to understand that there may be more options than you think.
Adapting irregular computations for high-performance processors
During the CPU versus GPU session, Professor Hiroshi Nakashima of Kyoto University delved into his research on finding ways to efficiently process irregular computations on Intel Xeon Phi architectures in his talk on How to Conquer Irregularities to Win the Game Versus Accelerators.

According to Nakashima, Kyoto University has four Intel-based supercomputing systems, the fastest of which is a Cray XC40. The system, which is nicknamed Camphor 2 and includes 1800 Xeon Phi processor (Knights Landing) cores, is ranked 33rd in the Top500 and 5th among Intel Xeon Phi processor systems. Nakashima said that the university prefers CPUs and has had success running irregular code on the Intel Xeon processor , so he is now keenly interested in finding ways to exert the full potential of the Intel Xeon Phi system on irregular workloads. The problem is that for the moment there is no efficient way to “regularize” common irregularities that are often found in big data workloads but seldom seen in HPC programs.
Nakashima says that irregularities are often included in code for the sake of simplicity. For example, to translate a formula or to minimize code size as in the example below.
left[N]={N-1,0,1,…,N-2};
Nakashima noted that irregularities are also a challenge with GPU-based systems. The difference is that GPUs have brute-force mechanisms for managing irregular accesses, with high levels of concurrency that may hide the costs arising from irregularities. Intel Xeon Phi processor systems have SIMD instruction support for some irregular operations (for example, gather, scatter, masking, compaction and conflict detection). They may require sequential semantics which some developers will expect the compiler to do all of the work without any changes to their code.
Nakashima believes that the way forward is to find ways to “regularize” irregular programs for Xeon Phi processor systems. He used reordering the sparse matrix y=A*x, which includes many diagonal sequences, as an example.
Sparse y=A*x
If A has many diagonal sequences …
y[i++]+=A.val[k++]*x[j++]; instead of
y[i]+=A.val[j++]+x[A.col[j++]];
In this case, the goal would be reordering the set of objects so there is a simple, continuous one-dimensional array that can be accessed directly and sequentially. The challenge would then be who finds the sequences and how do you handle operations other than y=A*x?
Setting the challenges around regularization aside for a moment, Nakashima highlighted the potential of regularization for improving performance. Specifically, he compared an example or a particle-in-cell simulation with and without regularized particle sets running on a variety of systems, including a Xeon Phi system.
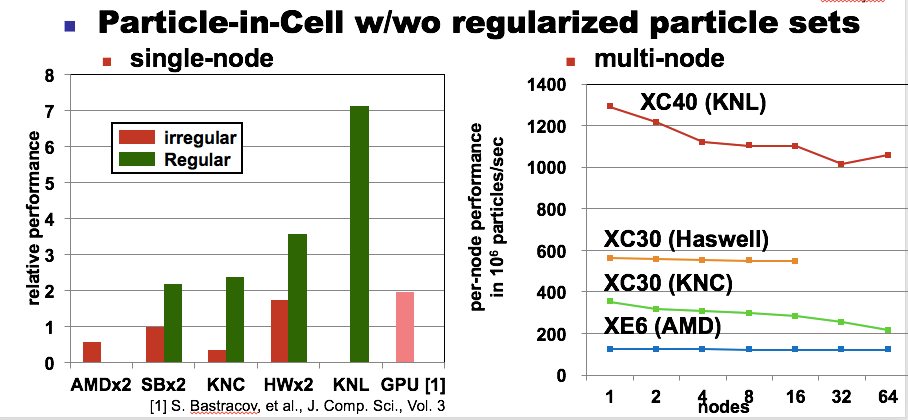
Although regularizing code clearly holds potential, Nakashima acknowledges the challenges. He notes that it takes a lot of time and money to do it yourself, making it impractical. He also pointed out that compilers can’t do everything and that although domain specific languages are a nice idea, there are no standard DSLs for all relevant applications.
Nakashima believes the answer may lie in an open-source library. He thinks it’s worth considering whether it would be possible to put together a library of algorithms for regularizing code that could be customized based on individual applications. He notes that the effort would require some sort of open-source framework for gathering ideas and managing the library, and he hopes that Intel will help lead a new initiative.
Despite the potential of Intel Xeon Phi processor systems for visualization and regularized code, not everyone begins there. Knoll said that in the visualization community everyone starts on GPU systems because the graphics libraries for them are already available and people are used to using them. His advice is to try using CPUs in a framework such as OSPRay to see what kind of performance you can get. Nakashima echoed his sentiment saying that GPUs have some good mechanisms for taking care of irregularities, but that finding ways to tap the potential of Intel Xeon Phi processors is well worth the effort.
Sources and further reading:
2 Ingo Wald, Gregory P Johnson, Jefferson Amstutz, Carson Brownlee, Aaron Knoll, James Jeffers, Paul Navratil. OSPRay: A CPU Ray Tracing Framework for Scientific Visualization. IEEE Visualization 2016.
4 I Wald, A Knoll, G Johnson, W Usher, M E Papka, V Pascucci. “CPU Ray Tracing Large Particle Data with Balanced P-k-d Trees”, IEEE Vis 2015.
5 S. Rizzi, M. Hereld, J. Insley, M. Papka, V. Vishwanath. “Large-Scale Parallel Vis. of Particle-Based Simulations using Point Sprites and LOD”, EGPGV 2015.

Changing Of The Guard For HPC And Big Iron At HPE
Hewlett Packard Enterprise has been building a mainstream and grassroots server business aimed at large enterprises, HPC centers, and academic and government institutions for two decades. HPE took a run at the hyperscalers and cloud builders and large service providers with its Cloudline minimalist machinery, but has largely backed away …
With HPC Humming Along, HPE Awaits Its AI Boom
The ProLiant server business is down in the dumps, and the storage business is in a slump. But petascale and exascale supercomputer deals based the combination of AMD CPUs and GPUs have filled in a lot of the gap. And Hewlett Packard Enterprise is now waiting, like all OEMs and …
Trying To Do More Real HPC In An Increasingly AI World
If you are in the traditional HPC community, it is not hard to be of two minds about the rise of AI and the mainstreaming of generative AI. At the very least, the GenAI tsunami makes it easier to argue for hardware budgets even though it is extremely difficult to …
Well, it is a common knowledge for some people for many years (decades) but mainstream is very reluctant to see it (fortunately for me ;o) there are many reasons why, mostly it is an experience/education inertia of people involved in 3D; adaptive algorithms require a mind/skill-set not common for 3D domain…